 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Box Anomaly Scoring for simple and efficient Out-of-Distribution detection
Mar 24, 2026Out-of-distribution (OOD) detection aims to identify inputs that differ from the training distribution in order to reduce unreliable predictions by deep neural networks. Among post-hoc feature-space approaches, OOD detection is commonly performed by approximating the in-distribution support in the representation space of a pretrained network. Existing methods often reflect a trade-off between compact parametric models, such as Mahalanobis-based scores, and more flexible but reference-based methods, such as k-nearest neighbors. Bounding-box abstraction provides an attractive intermediate perspective by representing in-distribution support through compact axis-aligned summaries of hidden activations. In this paper, we introduce Bounding Box Anomaly Scoring (BBAS), a post-hoc OOD detection method that leverages bounding-box abstraction. BBAS combines graded anomaly scores based on interval exceedances, monitoring variables adapted to convolutional layers, and decoupled clustering and box construction for richer and multi-layer representations. Experiments on image-classification benchmarks show that BBAS provides robust separation between in-distribution and out-of-distribution samples while preserving the simplicity, compactness, and updateability of the bounding-box approach.
Multivariate Bayesian Last Layer for Regression: Uncertainty Quantification and Disentanglement
May 02, 2024We present new Bayesian Last Layer models in the setting of multivariate regression under heteroscedastic noise, and propose an optimization algorithm for parameter learning. Bayesian Last Layer combines Bayesian modelling of the predictive distribution with neural networks for parameterization of the prior, and has the attractive property of uncertainty quantification with a single forward pass. The proposed framework is capable of disentangling the aleatoric and epistemic uncertainty, and can be used to transfer a canonically trained deep neural network to new data domains with uncertainty-aware capability.
Deep Learning reconstruction with uncertainty estimation for $γ$ photon interaction in fast scintillator detectors
Oct 10, 2023



This article presents a physics-informed deep learning method for the quantitative estimation of the spatial coordinates of gamma interactions within a monolithic scintillator, with a focus on Positron Emission Tomography (PET) imaging. A Density Neural Network approach is designed to estimate the 2-dimensional gamma photon interaction coordinates in a fast lead tungstate (PbWO4) monolithic scintillator detector. We introduce a custom loss function to estimate the inherent uncertainties associated with the reconstruction process and to incorporate the physical constraints of the detector. This unique combination allows for more robust and reliable position estimations and the obtained results demonstrate the effectiveness of the proposed approach and highlights the significant benefits of the uncertainties estimation. We discuss its potential impact on improving PET imaging quality and show how the results can be used to improve the exploitation of the model, to bring benefits to the application and how to evaluate the validity of the given prediction and the associated uncertainties. Importantly, our proposed methodology extends beyond this specific use case, as it can be generalized to other applications beyond PET imaging.
Packed-Ensembles for Efficient Uncertainty Estimation
Oct 17, 2022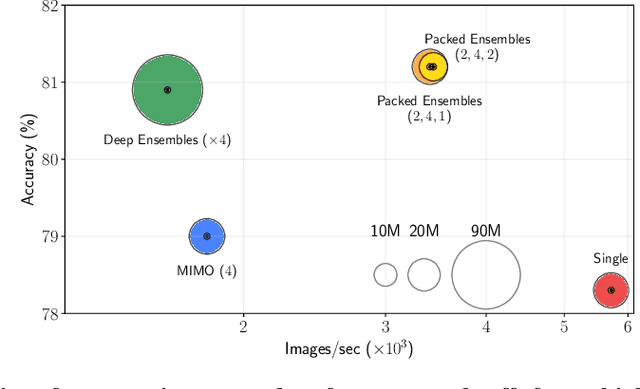
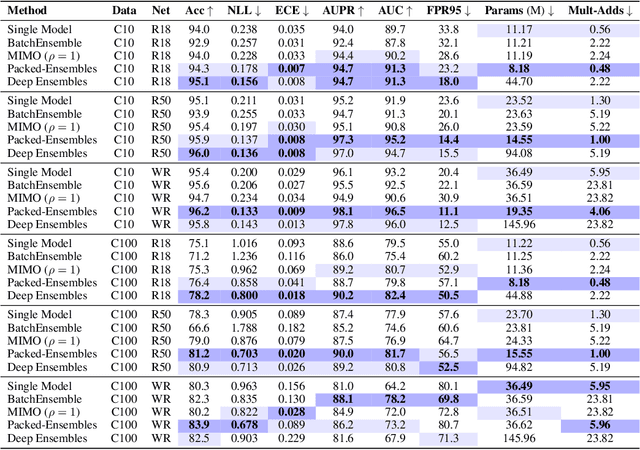
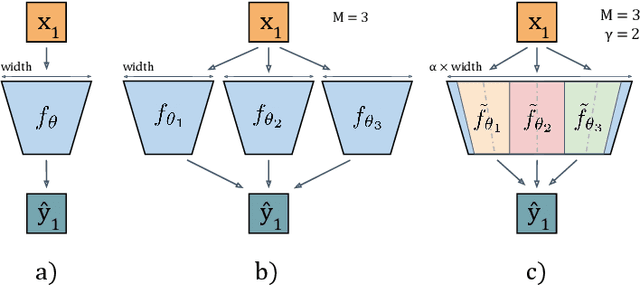

Deep Ensembles (DE) are a prominent approach achieving excellent performance on key metrics such as accuracy, calibration, uncertainty estimation, and out-of-distribution detection. However, hardware limitations of real-world systems constrain to smaller ensembles and lower capacity networks, significantly deteriorating their performance and properties. We introduce Packed-Ensembles (PE), a strategy to design and train lightweight structured ensembles by carefully modulating the dimension of their encoding space. We leverage grouped convolutions to parallelize the ensemble into a single common backbone and forward pass to improve training and inference speeds. PE is designed to work under the memory budget of a single standard neural network. Through extensive studies we show that PE faithfully preserve the properties of DE, e.g., diversity, and match their performance in terms of accuracy, calibration, out-of-distribution detection and robustness to distribution shift.