 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Select Pre-Trained Code Models for Reuse? A Learning Perspective
Jan 07, 2025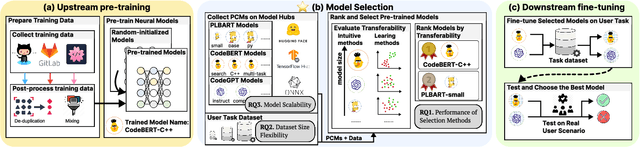


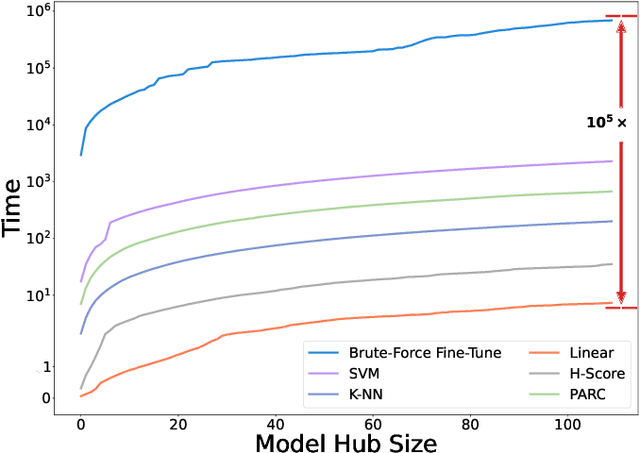
Pre-training a language model and then fine-tuning it has shown to be an efficient and effective technique for a wide range of code intelligence tasks, such as code generation, code summarization, and vulnerability detection. However, pretraining language models on a large-scale code corpus is computationally expensive. Fortunately, many off-the-shelf Pre-trained Code Models (PCMs), such as CodeBERT, CodeT5, CodeGen, and Code Llama, have been released publicly. These models acquire general code understanding and generation capability during pretraining, which enhances their performance on downstream code intelligence tasks. With an increasing number of these public pre-trained models, selecting the most suitable one to reuse for a specific task is essential. In this paper, we systematically investigate the reusability of PCMs. We first explore three intuitive model selection methods that select by size, training data, or brute-force fine-tuning. Experimental results show that these straightforward techniques either perform poorly or suffer high costs. Motivated by these findings, we explore learning-based model selection strategies that utilize pre-trained models without altering their parameters. Specifically, we train proxy models to gauge the performance of pre-trained models, and measure the distribution deviation between a model's latent features and the task's labels, using their closeness as an indicator of model transferability. We conduct experiments on 100 widely-used opensource PCMs for code intelligence tasks, with sizes ranging from 42.5 million to 3 billion parameters. The results demonstrate that learning-based selection methods reduce selection time to 100 seconds, compared to 2,700 hours with brute-force fine-tuning, with less than 6% performance degradation across related tasks.
Reliable Semantic Segmentation with Superpixel-Mix
Aug 02, 2021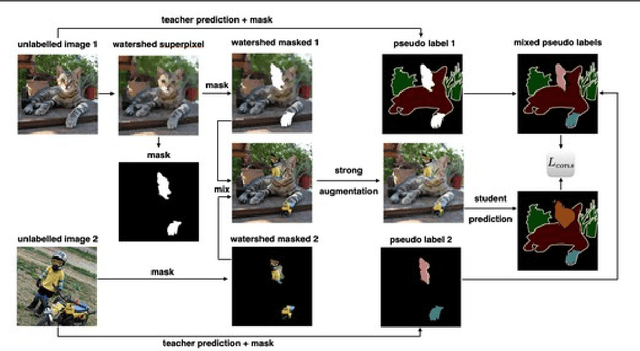
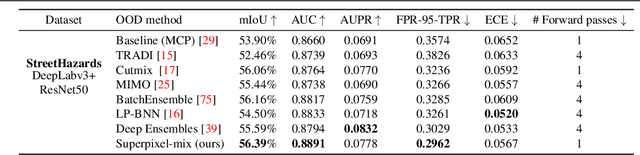
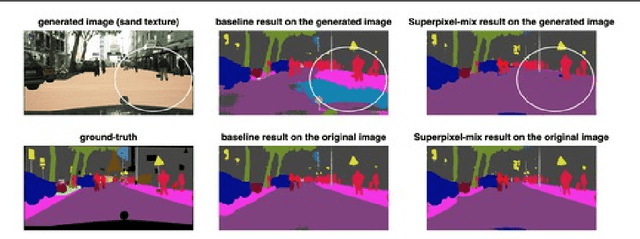
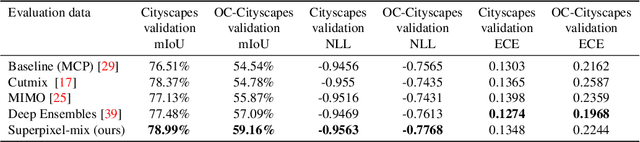
Along with predictive performance and runtime speed, reliability is a key requirement for real-world semantic segmentation. Reliability encompasses robustness, predictive uncertainty and reduced bias. To improve reliability, we introduce Superpixel-mix, a new superpixel-based data augmentation method with teacher-student consistency training. Unlike other mixing-based augmentation techniques, mixing superpixels between images is aware of object boundaries, while yielding consistent gains in segmentation accuracy. Our proposed technique achieves state-of-the-art results in semi-supervised semantic segmentation on the Cityscapes dataset. Moreover, Superpixel-mix improves the reliability of semantic segmentation by reducing network uncertainty and bias, as confirmed by competitive results under strong distributions shift (adverse weather, image corruptions) and when facing out-of-distribution data.
Learning Deep Morphological Networks with Neural Architecture Search
Jun 14, 2021

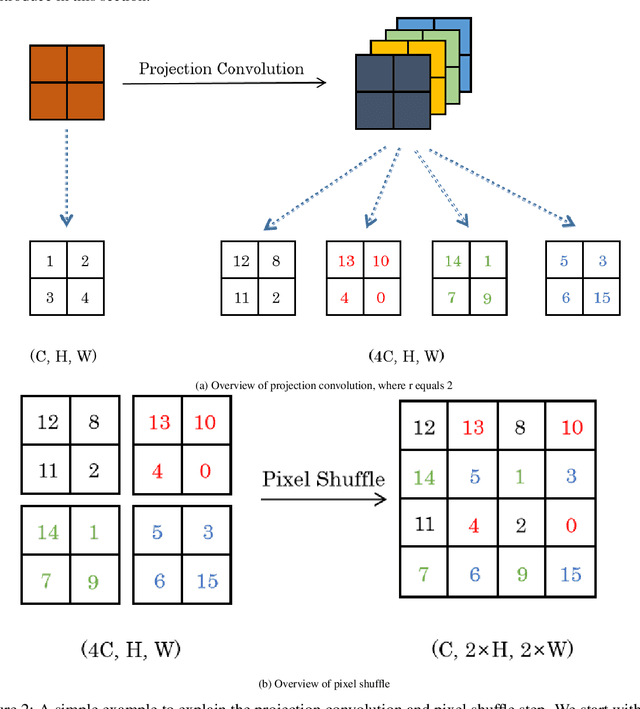

Deep Neural Networks (DNNs) are generated by sequentially performing linear and non-linear processes. Using a combination of linear and non-linear procedures is critical for generating a sufficiently deep feature space. The majority of non-linear operators are derivations of activation functions or pooling functions. Mathematical morphology is a branch of mathematics that provides non-linear operators for a variety of image processing problems. We investigate the utility of integrating these operations in an end-to-end deep learning framework in this paper. DNNs are designed to acquire a realistic representation for a particular job. Morphological operators give topological descriptors that convey salient information about the shapes of objects depicted in images. We propose a method based on meta-learning to incorporate morphological operators into DNNs. The learned architecture demonstrates how our novel morphological operations significantly increase DNN performance on various tasks, including picture classification and edge detection.
Surrogate Supervision for Medical Image Analysis: Effective Deep Learning From Limited Quantities of Labeled Data
Jan 25, 2019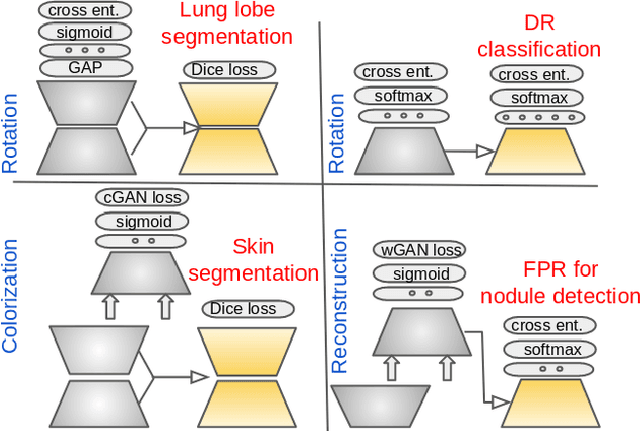

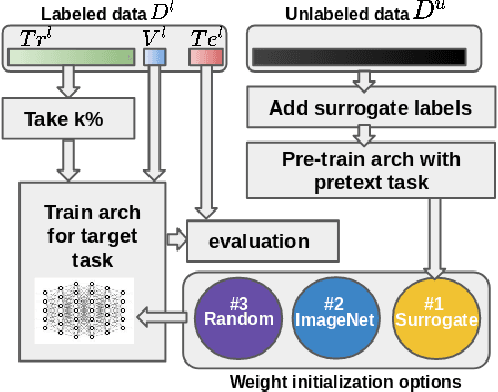
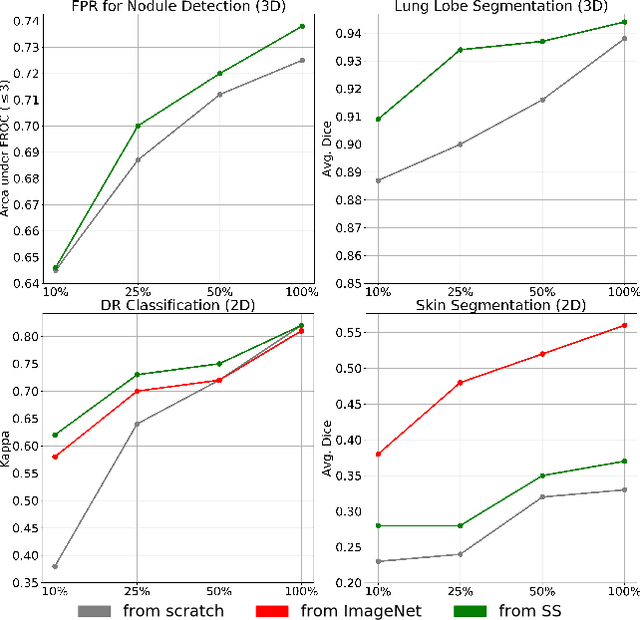
We investigate the effectiveness of a simple solution to the common problem of deep learning in medical image analysis with limited quantities of labeled training data. The underlying idea is to assign artificial labels to abundantly available unlabeled medical images and, through a process known as surrogate supervision, pre-train a deep neural network model for the target medical image analysis task lacking sufficient labeled training data. In particular, we employ 3 surrogate supervision schemes, namely rotation, reconstruction, and colorization, in 4 different medical imaging applications representing classification and segmentation for both 2D and 3D medical images. 3 key findings emerge from our research: 1) pre-training with surrogate supervision is effective for small training sets; 2) deep models trained from initial weights pre-trained through surrogate supervision outperform the same models when trained from scratch, suggesting that pre-training with surrogate supervision should be considered prior to training any deep 3D models; 3) pre-training models in the medical domain with surrogate supervision is more effective than transfer learning from an unrelated domain (e.g., natural images), indicating the practical value of abundant unlabeled medical image data.