 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin-X2S: Reconstructing 3D Shape from 2D Biplanar X-ray with Swin Transformers
Jan 10, 2025



The conversion from 2D X-ray to 3D shape holds significant potential for improving diagnostic efficiency and safety. However, existing reconstruction methods often rely on hand-crafted features, manual intervention, and prior knowledge, resulting in unstable shape errors and additional processing costs. In this paper, we introduce Swin-X2S, an end-to-end deep learning method for directly reconstructing 3D segmentation and labeling from 2D biplanar orthogonal X-ray images. Swin-X2S employs an encoder-decoder architecture: the encoder leverages 2D Swin Transformer for X-ray information extraction, while the decoder employs 3D convolution with cross-attention to integrate structural features from orthogonal views. A dimension-expanding module is introduced to bridge the encoder and decoder, ensuring a smooth conversion from 2D pixels to 3D voxels. We evaluate proposed method through extensive qualitative and quantitative experiments across nine publicly available datasets covering four anatomies (femur, hip, spine, and rib), with a total of 54 categories. Significant improvements over previous methods have been observed not only in the segmentation and labeling metrics but also in the clinically relevant parameters that are of primary concern in practical applications, which demonstrates the promise of Swin-X2S to provide an effective option for anatomical shape reconstruction in clinical scenarios. Code implementation is available at: \url{https://github.com/liukuan5625/Swin-X2S}.
Volumetric Medical Image Segmentation via Scribble Annotations and Shape Priors
Oct 12, 2023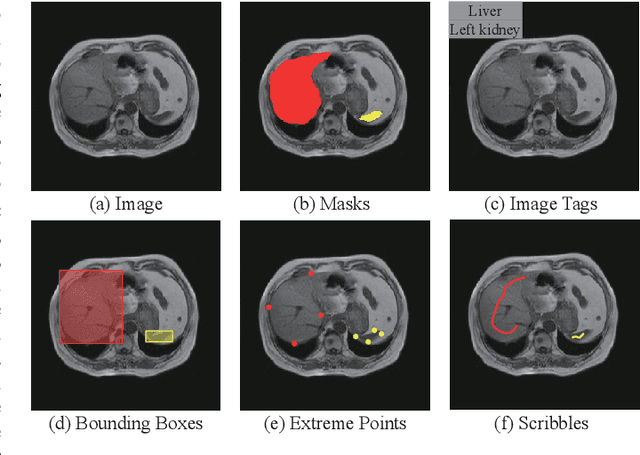
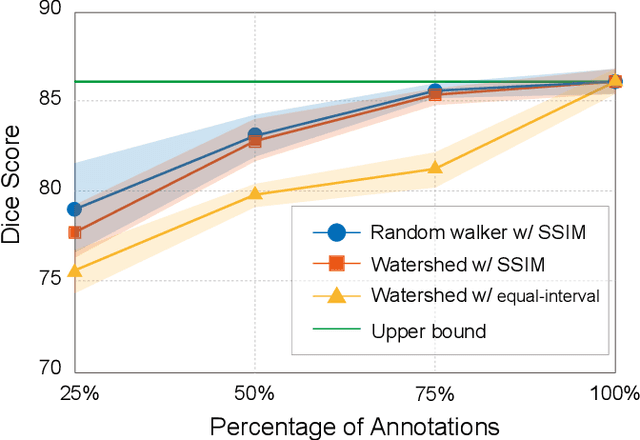
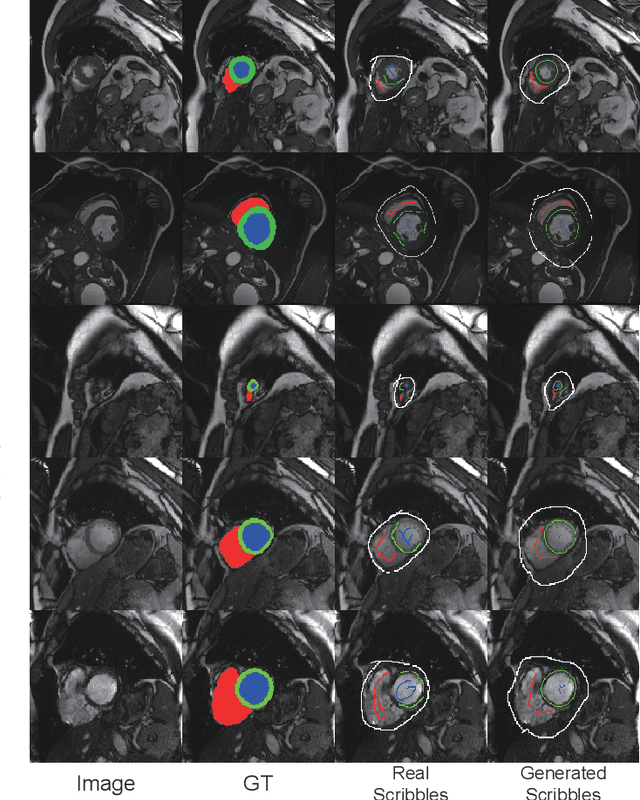
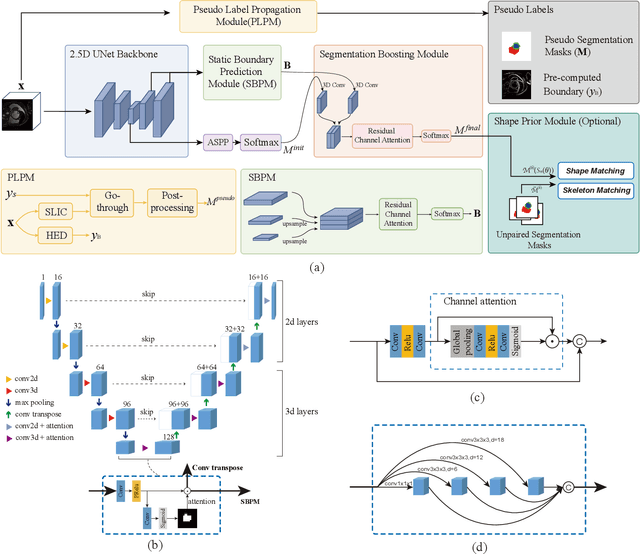
Recently, weakly-supervised image segmentation using weak annotations like scribbles has gained great attention in computer vision and medical image analysis, since such annotations are much easier to obtain compared to time-consuming and labor-intensive labeling at the pixel/voxel level. However, due to a lack of structure supervision on regions of interest (ROIs), existing scribble-based methods suffer from poor boundary localization. Furthermore, most current methods are designed for 2D image segmentation, which do not fully leverage the volumetric information if directly applied to each image slice. In this paper, we propose a scribble-based volumetric image segmentation, Scribble2D5, which tackles 3D anisotropic image segmentation and aims to its improve boundary prediction. To achieve this, we augment a 2.5D attention UNet with a proposed label propagation module to extend semantic information from scribbles and use a combination of static and active boundary prediction to learn ROI's boundary and regularize its shape. Also, we propose an optional add-on component, which incorporates the shape prior information from unpaired segmentation masks to further improve model accuracy. Extensive experiments on three public datasets and one private dataset demonstrate our Scribble2D5 achieves state-of-the-art performance on volumetric image segmentation using scribbles and shape prior if available.
Combining Visible Light and Infrared Imaging for Efficient Detection of Respiratory Infections such as COVID-19 on Portable Device
Apr 15, 2020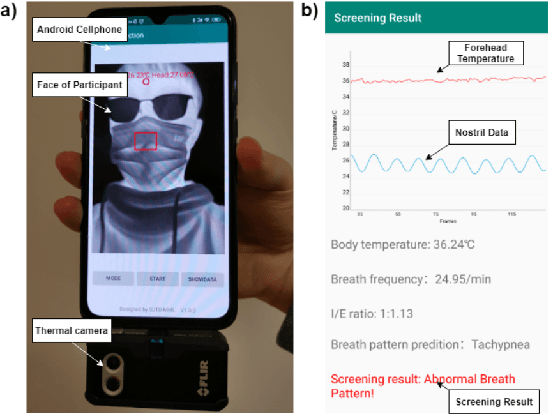
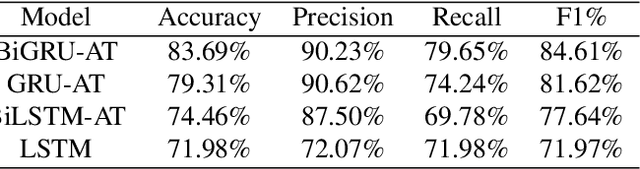

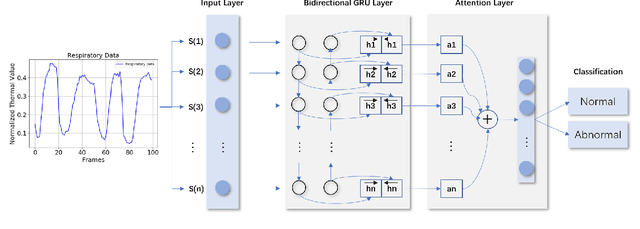
Coronavirus Disease 2019 (COVID-19) has become a serious global epidemic in the past few months and caused huge loss to human society worldwide. For such a large-scale epidemic, early detection and isolation of potential virus carriers is essential to curb the spread of the epidemic. Recent studies have shown that one important feature of COVID-19 is the abnormal respiratory status caused by viral infections. During the epidemic, many people tend to wear masks to reduce the risk of getting sick. Therefore, in this paper, we propose a portable non-contact method to screen the health condition of people wearing masks through analysis of the respiratory characteristics. The device mainly consists of a FLIR one thermal camera and an Android phone. This may help identify those potential patients of COVID-19 under practical scenarios such as pre-inspection in schools and hospitals. In this work, we perform the health screening through the combination of the RGB and thermal videos obtained from the dual-mode camera and deep learning architecture.We first accomplish a respiratory data capture technique for people wearing masks by using face recognition. Then, a bidirectional GRU neural network with attention mechanism is applied to the respiratory data to obtain the health screening result. The results of validation experiments show that our model can identify the health status on respiratory with the accuracy of 83.7\% on the real-world dataset. The abnormal respiratory data and part of normal respiratory data are collected from Ruijin Hospital Affiliated to The Shanghai Jiao Tong University Medical School. Other normal respiratory data are obtained from healthy people around our researchers. This work demonstrates that the proposed portable and intelligent health screening device can be used as a pre-scan method for respiratory infections, which may help fight the current COVID-19 epidemic.
Surrogate Supervision for Medical Image Analysis: Effective Deep Learning From Limited Quantities of Labeled Data
Jan 25, 2019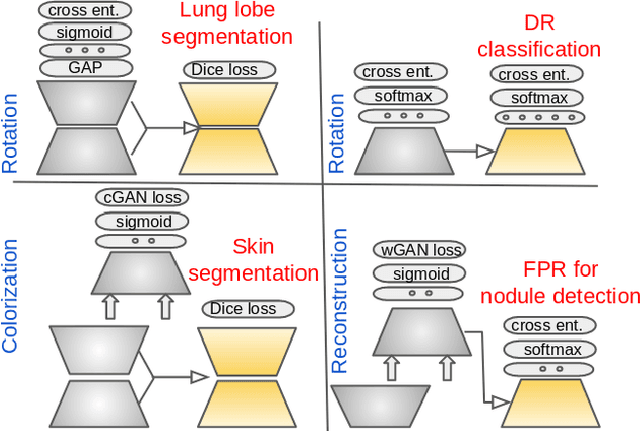

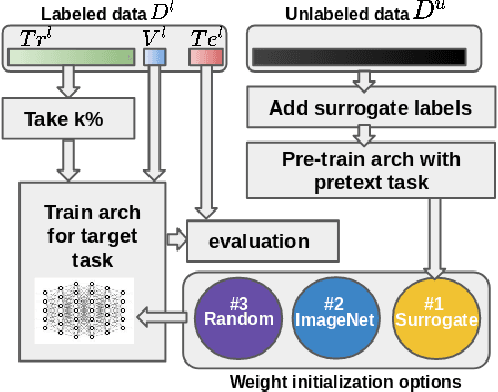
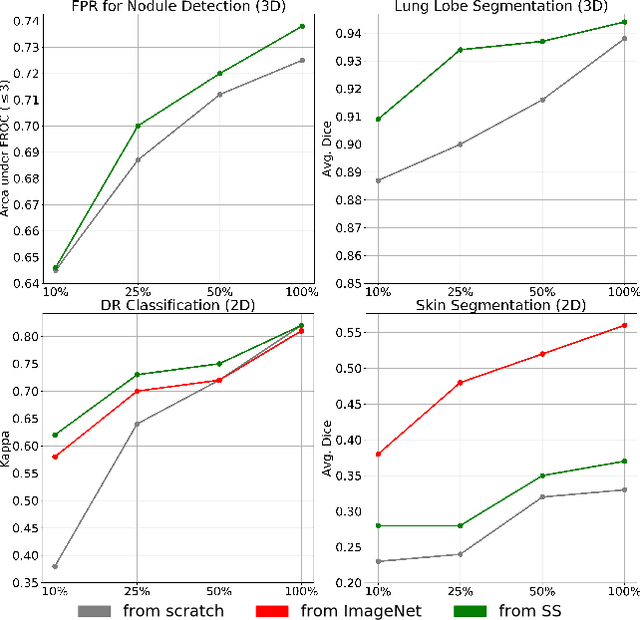
We investigate the effectiveness of a simple solution to the common problem of deep learning in medical image analysis with limited quantities of labeled training data. The underlying idea is to assign artificial labels to abundantly available unlabeled medical images and, through a process known as surrogate supervision, pre-train a deep neural network model for the target medical image analysis task lacking sufficient labeled training data. In particular, we employ 3 surrogate supervision schemes, namely rotation, reconstruction, and colorization, in 4 different medical imaging applications representing classification and segmentation for both 2D and 3D medical images. 3 key findings emerge from our research: 1) pre-training with surrogate supervision is effective for small training sets; 2) deep models trained from initial weights pre-trained through surrogate supervision outperform the same models when trained from scratch, suggesting that pre-training with surrogate supervision should be considered prior to training any deep 3D models; 3) pre-training models in the medical domain with surrogate supervision is more effective than transfer learning from an unrelated domain (e.g., natural images), indicating the practical value of abundant unlabeled medical image data.