 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Denoising Neural Networks for Few Shot Learning
Oct 26, 2021
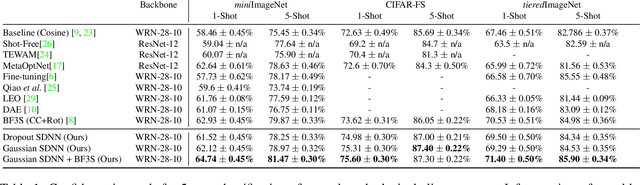
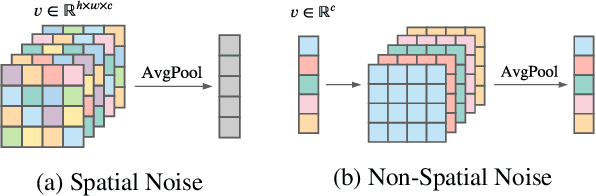

In this paper, we introduce a new architecture for few shot learning, the task of teaching a neural network from as few as one or five labeled examples. Inspired by the theoretical results of Alaine et al that Denoising Autoencoders refine features to lie closer to the true data manifold, we present a new training scheme that adds noise at multiple stages of an existing neural architecture while simultaneously learning to be robust to this added noise. This architecture, which we call a Self-Denoising Neural Network (SDNN), can be applied easily to most modern convolutional neural architectures, and can be used as a supplement to many existing few-shot learning techniques. We empirically show that SDNNs out-perform previous state-of-the-art methods for few shot image recognition using the Wide-ResNet architecture on the \textit{mini}ImageNet, tiered-ImageNet, and CIFAR-FS few shot learning datasets. We also perform a series of ablation experiments to empirically justify the construction of the SDNN architecture. Finally, we show that SDNNs even improve few shot performance on the task of human action detection in video using experiments on the ActEV SDL Surprise Activities challenge.
Finding Facial Forgery Artifacts with Parts-Based Detectors
Sep 21, 2021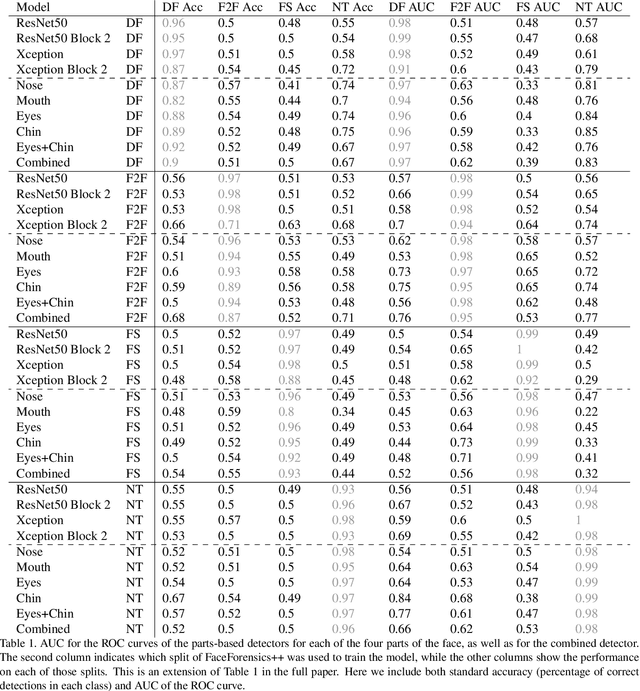

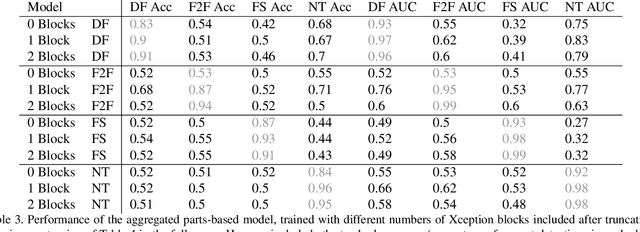
Manipulated videos, especially those where the identity of an individual has been modified using deep neural networks, are becoming an increasingly relevant threat in the modern day. In this paper, we seek to develop a generalizable, explainable solution to detecting these manipulated videos. To achieve this, we design a series of forgery detection systems that each focus on one individual part of the face. These parts-based detection systems, which can be combined and used together in a single architecture, meet all of our desired criteria - they generalize effectively between datasets and give us valuable insights into what the network is looking at when making its decision. We thus use these detectors to perform detailed empirical analysis on the FaceForensics++, Celeb-DF, and Facebook Deepfake Detection Challenge datasets, examining not just what the detectors find but also collecting and analyzing useful related statistics on the datasets themselves.
SPIN: A High Speed, High Resolution Vision Dataset for Tracking and Action Recognition in Ping Pong
Dec 13, 2019

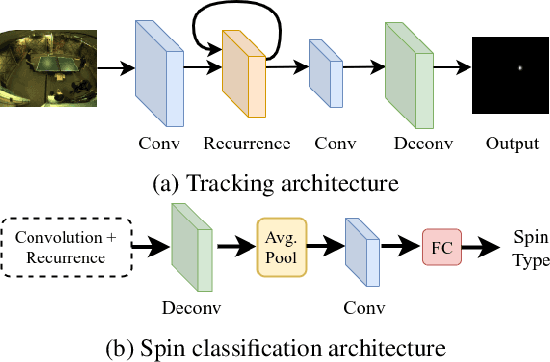
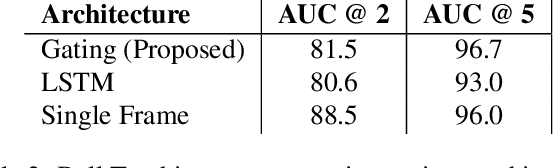
We introduce a new high resolution, high frame rate stereo video dataset, which we call SPIN, for tracking and action recognition in the game of ping pong. The corpus consists of ping pong play with three main annotation streams that can be used to learn tracking and action recognition models -- tracking of the ping pong ball and poses of humans in the videos and the spin of the ball being hit by humans. The training corpus consists of 53 hours of data with labels derived from previous models in a semi-supervised method. The testing corpus contains 1 hour of data with the same information, except that crowd compute was used to obtain human annotations of the ball position, from which ball spin has been derived. Along with the dataset we introduce several baseline models that were trained on this data. The models were specifically chosen to be able to perform inference at the same rate as the images are generated -- specifically 150 fps. We explore the advantages of multi-task training on this data, and also show interesting properties of ping pong ball trajectories that are derived from our observational data, rather than from prior physics models. To our knowledge this is the first large scale dataset of ping pong; we offer it to the community as a rich dataset that can be used for a large variety of machine learning and vision tasks such as tracking, pose estimation, semi-supervised and unsupervised learning and generative modeling.
3D Human Pose Estimation from Deep Multi-View 2D Pose
Feb 07, 2019
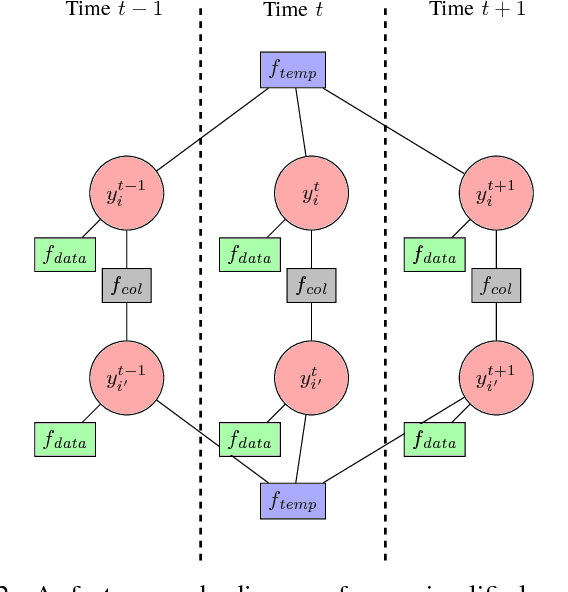
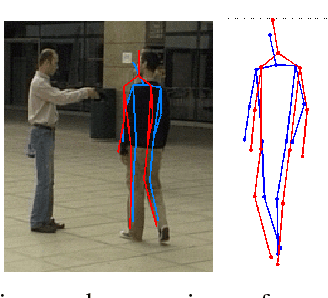

Human pose estimation - the process of recognizing a human's limb positions and orientations in a video - has many important applications including surveillance, diagnosis of movement disorders, and computer animation. While deep learning has lead to great advances in 2D and 3D pose estimation from single video sources, the problem of estimating 3D human pose from multiple video sensors with overlapping fields of view has received less attention. When the application allows use of multiple cameras, 3D human pose estimates may be greatly improved through fusion of multi-view pose estimates and observation of limbs that are fully or partially occluded in some views. Past approaches to multi-view 3D pose estimation have used probabilistic graphical models to reason over constraints, including per-image pose estimates, temporal smoothness, and limb length. In this paper, we present a pipeline for multi-view 3D pose estimation of multiple individuals which combines a state-of-art 2D pose detector with a factor graph of 3D limb constraints optimized with belief propagation. We evaluate our results on the TUM-Campus and Shelf datasets for multi-person 3D pose estimation and show that our system significantly out-performs the previous state-of-the-art with a simpler model of limb dependency.
A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos
Nov 23, 2018


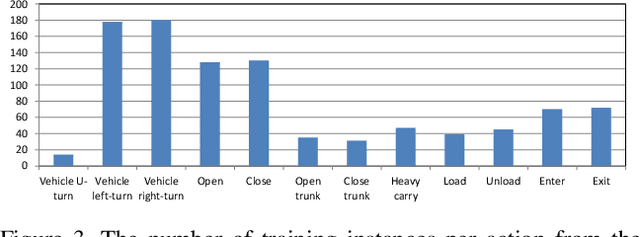
Existing approaches for spatio-temporal action detection in videos are limited by the spatial extent and temporal duration of the actions. In this paper, we present a modular system for spatio-temporal action detection in untrimmed security videos. We propose a two stage approach. The first stage generates dense spatio-temporal proposals using hierarchical clustering and temporal jittering techniques on frame-wise object detections. The second stage is a Temporal Refinement I3D (TRI-3D) network that performs action classification and temporal refinement on the generated proposals. The object detection-based proposal generation step helps in detecting actions occurring in a small spatial region of a video frame, while temporal jittering and refinement helps in detecting actions of variable lengths. Experimental results on the spatio-temporal action detection dataset - DIVA - show the effectiveness of our system. For comparison, the performance of our system is also evaluated on the THUMOS14 temporal action detection dataset.