 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Denoising Neural Networks for Few Shot Learning
Paper and Code
Oct 26, 2021
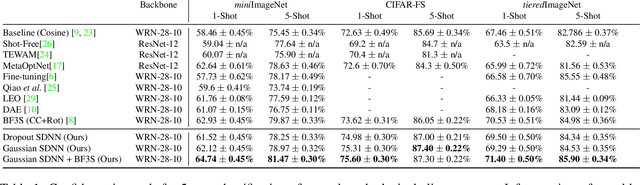
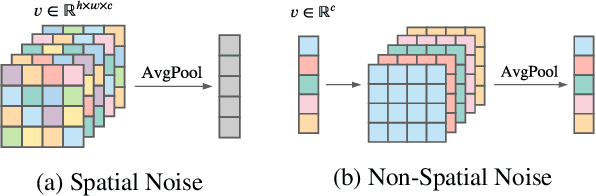

In this paper, we introduce a new architecture for few shot learning, the task of teaching a neural network from as few as one or five labeled examples. Inspired by the theoretical results of Alaine et al that Denoising Autoencoders refine features to lie closer to the true data manifold, we present a new training scheme that adds noise at multiple stages of an existing neural architecture while simultaneously learning to be robust to this added noise. This architecture, which we call a Self-Denoising Neural Network (SDNN), can be applied easily to most modern convolutional neural architectures, and can be used as a supplement to many existing few-shot learning techniques. We empirically show that SDNNs out-perform previous state-of-the-art methods for few shot image recognition using the Wide-ResNet architecture on the \textit{mini}ImageNet, tiered-ImageNet, and CIFAR-FS few shot learning datasets. We also perform a series of ablation experiments to empirically justify the construction of the SDNN architecture. Finally, we show that SDNNs even improve few shot performance on the task of human action detection in video using experiments on the ActEV SDL Surprise Activities challenge.