 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Adaptive Intermediate Representations for Video Understanding
Apr 14, 2021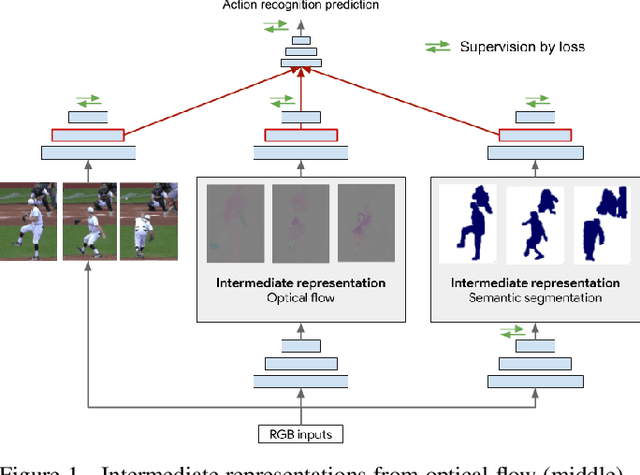
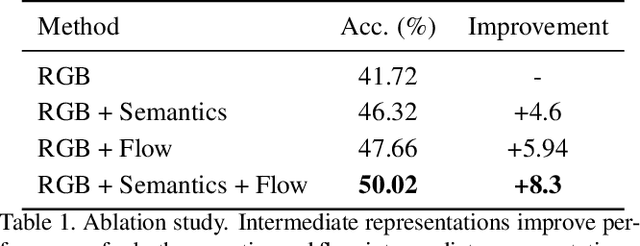
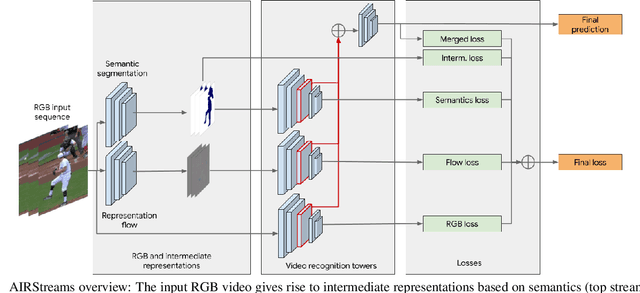
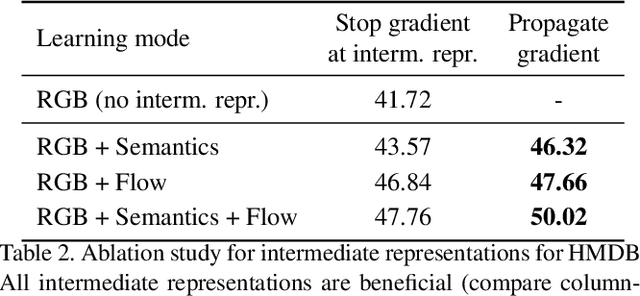
A common strategy to video understanding is to incorporate spatial and motion information by fusing features derived from RGB frames and optical flow. In this work, we introduce a new way to leverage semantic segmentation as an intermediate representation for video understanding and use it in a way that requires no additional labeling. Second, we propose a general framework which learns the intermediate representations (optical flow and semantic segmentation) jointly with the final video understanding task and allows the adaptation of the representations to the end goal. Despite the use of intermediate representations within the network, during inference, no additional data beyond RGB sequences is needed, enabling efficient recognition with a single network. Finally, we present a way to find the optimal learning configuration by searching the best loss weighting via evolution. We obtain more powerful visual representations for videos which lead to performance gains over the state-of-the-art.
AssembleNet++: Assembling Modality Representations via Attention Connections
Aug 18, 2020
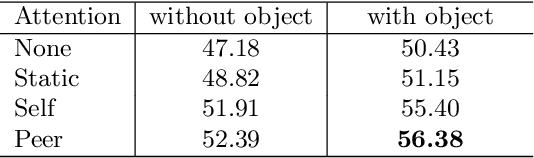
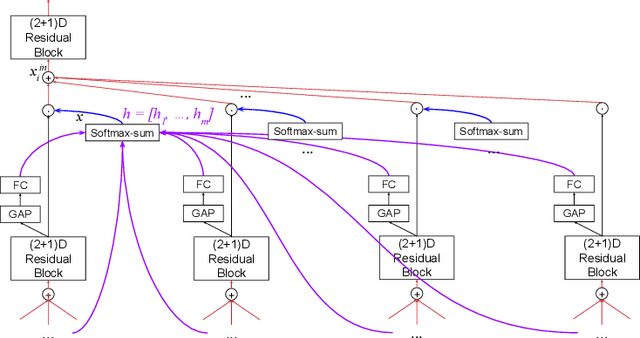
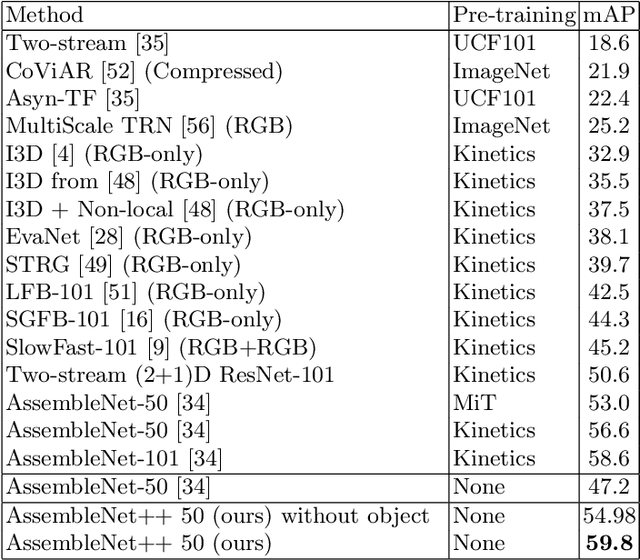
We create a family of powerful video models which are able to: (i) learn interactions between semantic object information and raw appearance and motion features, and (ii) deploy attention in order to better learn the importance of features at each convolutional block of the network. A new network component named peer-attention is introduced, which dynamically learns the attention weights using another block or input modality. Even without pre-training, our models outperform the previous work on standard public activity recognition datasets with continuous videos, establishing new state-of-the-art. We also confirm that our findings of having neural connections from the object modality and the use of peer-attention is generally applicable for different existing architectures, improving their performances. We name our model explicitly as AssembleNet++. The code will be available at: https://sites.google.com/corp/view/assemblenet/
* ECCV 2020 camera-ready version
SPIN: A High Speed, High Resolution Vision Dataset for Tracking and Action Recognition in Ping Pong
Dec 13, 2019

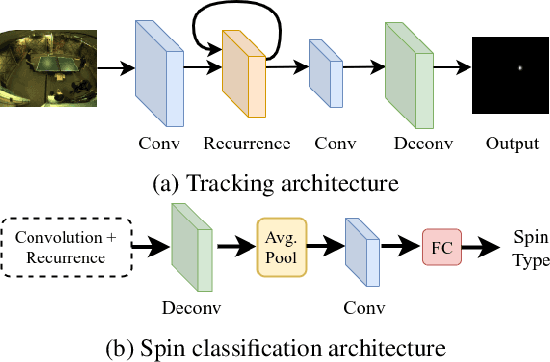
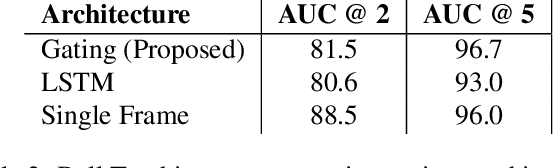
We introduce a new high resolution, high frame rate stereo video dataset, which we call SPIN, for tracking and action recognition in the game of ping pong. The corpus consists of ping pong play with three main annotation streams that can be used to learn tracking and action recognition models -- tracking of the ping pong ball and poses of humans in the videos and the spin of the ball being hit by humans. The training corpus consists of 53 hours of data with labels derived from previous models in a semi-supervised method. The testing corpus contains 1 hour of data with the same information, except that crowd compute was used to obtain human annotations of the ball position, from which ball spin has been derived. Along with the dataset we introduce several baseline models that were trained on this data. The models were specifically chosen to be able to perform inference at the same rate as the images are generated -- specifically 150 fps. We explore the advantages of multi-task training on this data, and also show interesting properties of ping pong ball trajectories that are derived from our observational data, rather than from prior physics models. To our knowledge this is the first large scale dataset of ping pong; we offer it to the community as a rich dataset that can be used for a large variety of machine learning and vision tasks such as tracking, pose estimation, semi-supervised and unsupervised learning and generative modeling.