 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Intermediate Representations for Video Understanding
Paper and Code
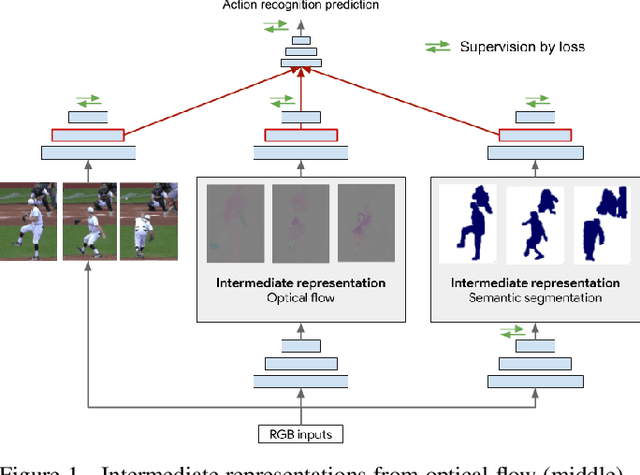
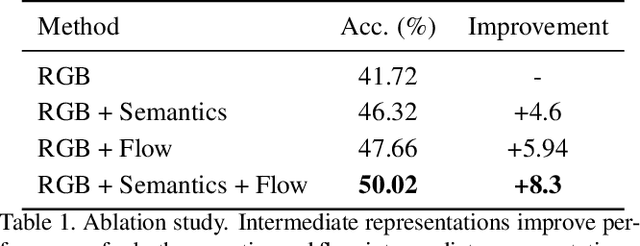
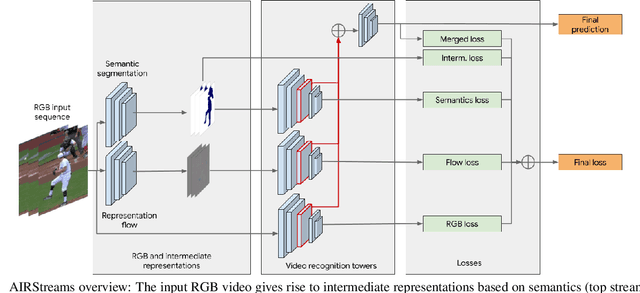
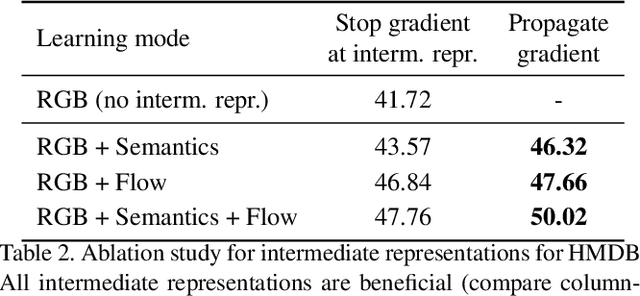
A common strategy to video understanding is to incorporate spatial and motion information by fusing features derived from RGB frames and optical flow. In this work, we introduce a new way to leverage semantic segmentation as an intermediate representation for video understanding and use it in a way that requires no additional labeling. Second, we propose a general framework which learns the intermediate representations (optical flow and semantic segmentation) jointly with the final video understanding task and allows the adaptation of the representations to the end goal. Despite the use of intermediate representations within the network, during inference, no additional data beyond RGB sequences is needed, enabling efficient recognition with a single network. Finally, we present a way to find the optimal learning configuration by searching the best loss weighting via evolution. We obtain more powerful visual representations for videos which lead to performance gains over the state-of-the-art.