 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssembleNet++: Assembling Modality Representations via Attention Connections
Paper and Code

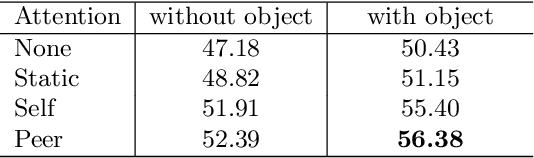
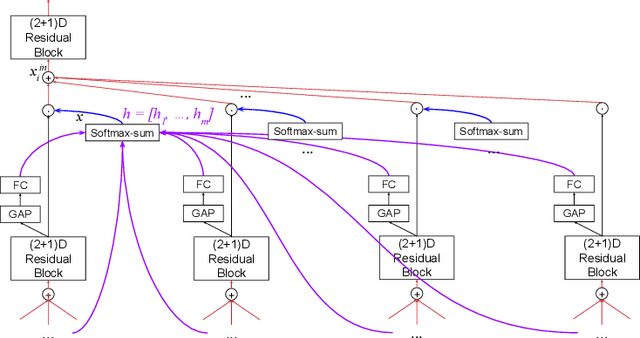
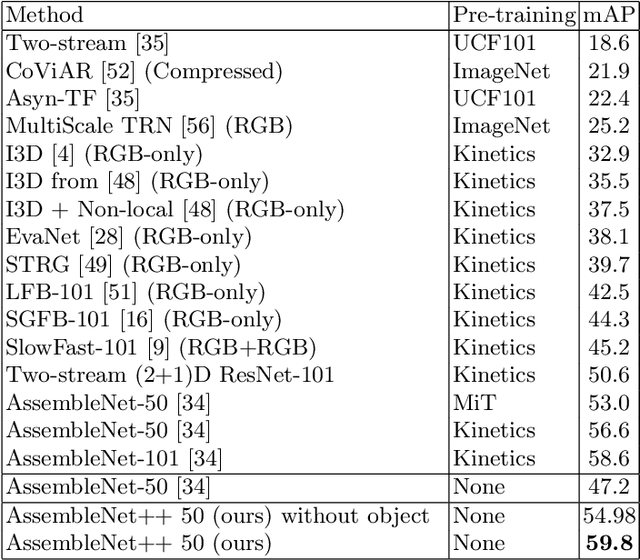
We create a family of powerful video models which are able to: (i) learn interactions between semantic object information and raw appearance and motion features, and (ii) deploy attention in order to better learn the importance of features at each convolutional block of the network. A new network component named peer-attention is introduced, which dynamically learns the attention weights using another block or input modality. Even without pre-training, our models outperform the previous work on standard public activity recognition datasets with continuous videos, establishing new state-of-the-art. We also confirm that our findings of having neural connections from the object modality and the use of peer-attention is generally applicable for different existing architectures, improving their performances. We name our model explicitly as AssembleNet++. The code will be available at: https://sites.google.com/corp/view/assemblenet/