 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile gesture recognition for capacitive sensing devices: adapting on-the-job
May 12, 2023Automated hand gesture recognition has been a focus of the AI community for decades. Traditionally, work in this domain revolved largely around scenarios assuming the availability of the flow of images of the user hands. This has partly been due to the prevalence of camera-based devices and the wide availability of image data. However, there is growing demand for gesture recognition technology that can be implemented on low-power devices using limited sensor data instead of high-dimensional inputs like hand images. In this work, we demonstrate a hand gesture recognition system and method that uses signals from capacitive sensors embedded into the etee hand controller. The controller generates real-time signals from each of the wearer five fingers. We use a machine learning technique to analyse the time series signals and identify three features that can represent 5 fingers within 500 ms. The analysis is composed of a two stage training strategy, including dimension reduction through principal component analysis and classification with K nearest neighbour. Remarkably, we found that this combination showed a level of performance which was comparable to more advanced methods such as supervised variational autoencoder. The base system can also be equipped with the capability to learn from occasional errors by providing it with an additional adaptive error correction mechanism. The results showed that the error corrector improve the classification performance in the base system without compromising its performance. The system requires no more than 1 ms of computing time per input sample, and is smaller than deep neural networks, demonstrating the feasibility of agile gesture recognition systems based on this technology.
HUM3DIL: Semi-supervised Multi-modal 3D Human Pose Estimation for Autonomous Driving
Dec 15, 2022Autonomous driving is an exciting new industry, posing important research questions. Within the perception module, 3D human pose estimation is an emerging technology, which can enable the autonomous vehicle to perceive and understand the subtle and complex behaviors of pedestrians. While hardware systems and sensors have dramatically improved over the decades -- with cars potentially boasting complex LiDAR and vision systems and with a growing expansion of the available body of dedicated datasets for this newly available information -- not much work has been done to harness these novel signals for the core problem of 3D human pose estimation. Our method, which we coin HUM3DIL (HUMan 3D from Images and LiDAR), efficiently makes use of these complementary signals, in a semi-supervised fashion and outperforms existing methods with a large margin. It is a fast and compact model for onboard deployment. Specifically, we embed LiDAR points into pixel-aligned multi-modal features, which we pass through a sequence of Transformer refinement stages. Quantitative experiments on the Waymo Open Dataset support these claims, where we achieve state-of-the-art results on the task of 3D pose estimation.
Multi-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
Dec 22, 2021
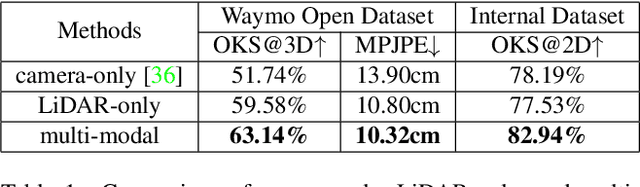
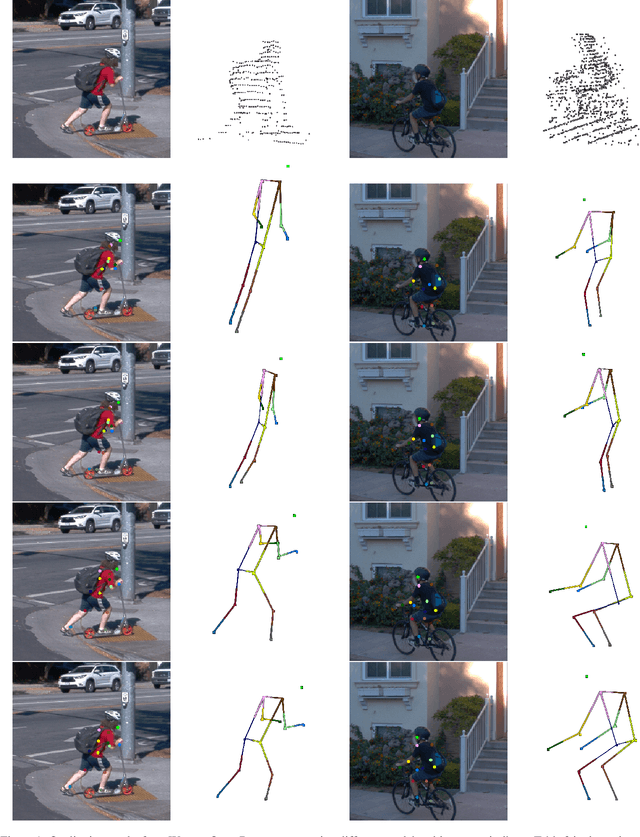
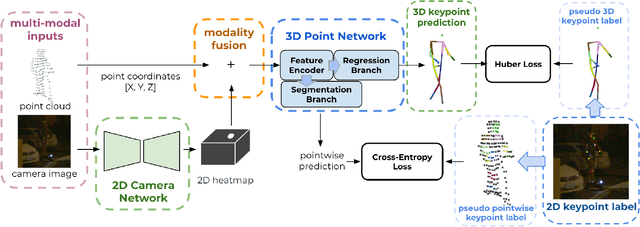
3D human pose estimation (HPE) in autonomous vehicles (AV) differs from other use cases in many factors, including the 3D resolution and range of data, absence of dense depth maps, failure modes for LiDAR, relative location between the camera and LiDAR, and a high bar for estimation accuracy. Data collected for other use cases (such as virtual reality, gaming, and animation) may therefore not be usable for AV applications. This necessitates the collection and annotation of a large amount of 3D data for HPE in AV, which is time-consuming and expensive. In this paper, we propose one of the first approaches to alleviate this problem in the AV setting. Specifically, we propose a multi-modal approach which uses 2D labels on RGB images as weak supervision to perform 3D HPE. The proposed multi-modal architecture incorporates LiDAR and camera inputs with an auxiliary segmentation branch. On the Waymo Open Dataset, our approach achieves a 22% relative improvement over camera-only 2D HPE baseline, and 6% improvement over LiDAR-only model. Finally, careful ablation studies and parts based analysis illustrate the advantages of each of our contributions.
Astrocytes mediate analogous memory in a multi-layer neuron-astrocytic network
Aug 31, 2021



Modeling the neuronal processes underlying short-term working memory remains the focus of many theoretical studies in neuroscience. Here we propose a mathematical model of spiking neuron network (SNN) demonstrating how a piece of information can be maintained as a robust activity pattern for several seconds then completely disappear if no other stimuli come. Such short-term memory traces are preserved due to the activation of astrocytes accompanying the SNN. The astrocytes exhibit calcium transients at a time scale of seconds. These transients further modulate the efficiency of synaptic transmission and, hence, the firing rate of neighboring neurons at diverse timescales through gliotransmitter release. We show how such transients continuously encode frequencies of neuronal discharges and provide robust short-term storage of analogous information. This kind of short-term memory can keep operative information for seconds, then completely forget it to avoid overlapping with forthcoming patterns. The SNN is inter-connected with the astrocytic layer by local inter-cellular diffusive connections. The astrocytes are activated only when the neighboring neurons fire quite synchronously, e.g. when an information pattern is loaded. For illustration, we took greyscale photos of people's faces where the grey level encoded the level of applied current stimulating the neurons. The astrocyte feedback modulates (facilitates) synaptic transmission by varying the frequency of neuronal firing. We show how arbitrary patterns can be loaded, then stored for a certain interval of time, and retrieved if the appropriate clue pattern is applied to the input.
Semantic Analysis for Automated Evaluation of the Potential Impact of Research Articles
Apr 26, 2021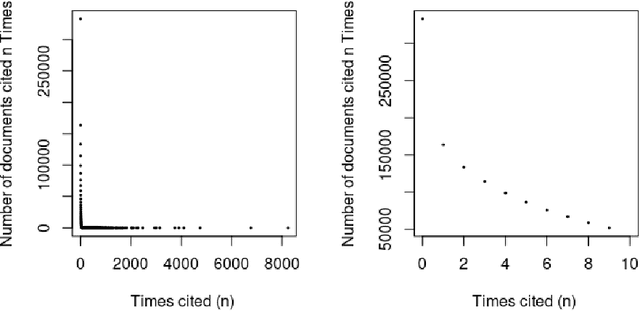
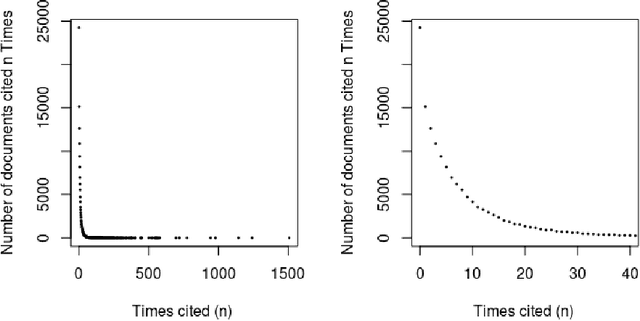
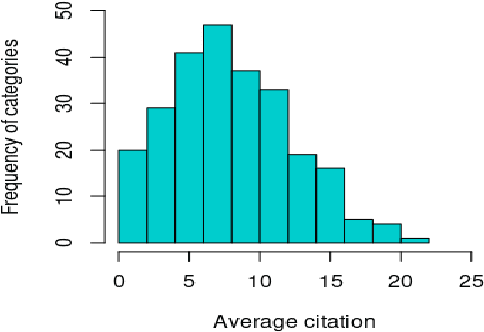
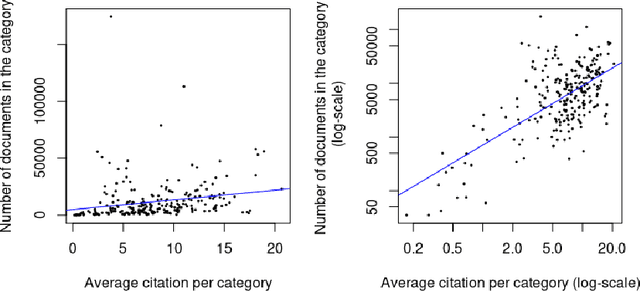
Can the analysis of the semantics of words used in the text of a scientific paper predict its future impact measured by citations? This study details examples of automated text classification that achieved 80% success rate in distinguishing between highly-cited and little-cited articles. Automated intelligent systems allow the identification of promising works that could become influential in the scientific community. The problems of quantifying the meaning of texts and representation of human language have been clear since the inception of Natural Language Processing. This paper presents a novel method for vector representation of text meaning based on information theory and show how this informational semantics is used for text classification on the basis of the Leicester Scientific Corpus. We describe the experimental framework used to evaluate the impact of scientific articles through their informational semantics. Our interest is in citation classification to discover how important semantics of texts are in predicting the citation count. We propose the semantics of texts as an important factor for citation prediction. For each article, our system extracts the abstract of paper, represents the words of the abstract as vectors in Meaning Space, automatically analyses the distribution of scientific categories (Web of Science categories) within the text of abstract, and then classifies papers according to citation counts (highly-cited, little-cited). We show that an informational approach to representing the meaning of a text has offered a way to effectively predict the scientific impact of research papers.
Principal Components of the Meaning
Sep 18, 2020In this paper we argue that (lexical) meaning in science can be represented in a 13 dimension Meaning Space. This space is constructed using principal component analysis (singular decomposition) on the matrix of word category relative information gains, where the categories are those used by the Web of Science, and the words are taken from a reduced word set from texts in the Web of Science. We show that this reduced word set plausibly represents all texts in the corpus, so that the principal component analysis has some objective meaning with respect to the corpus. We argue that 13 dimensions is adequate to describe the meaning of scientific texts, and hypothesise about the qualitative meaning of the principal components.
Automatic Short Answer Grading and Feedback Using Text Mining Methods
Jul 27, 2018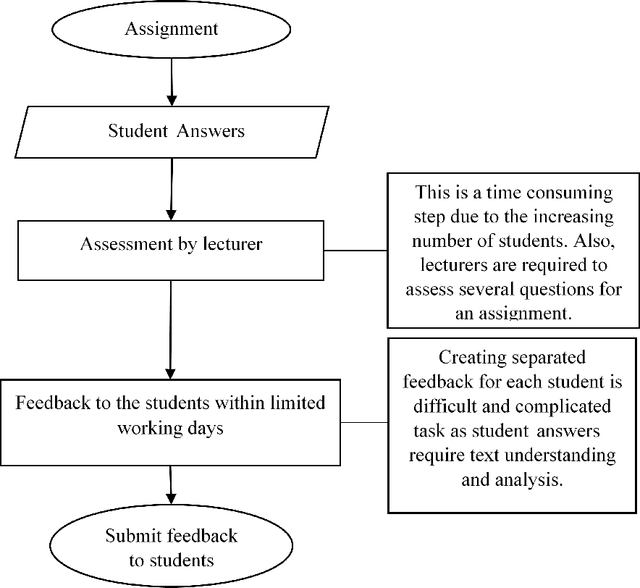


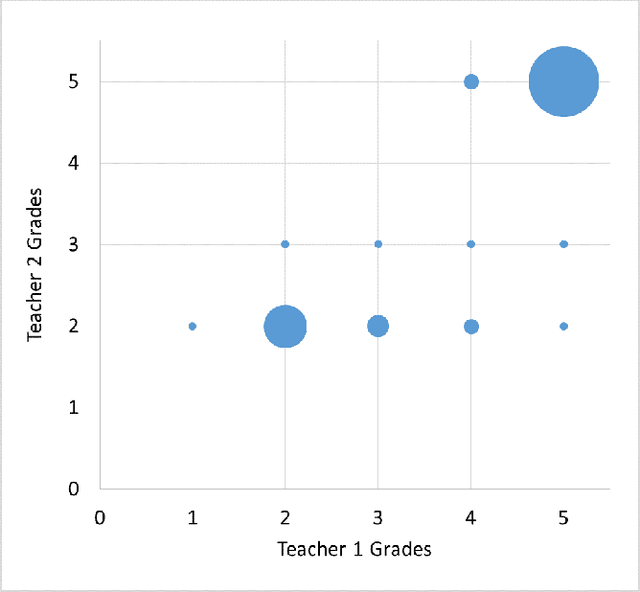
Automatic grading is not a new approach but the need to adapt the latest technology to automatic grading has become very important. As the technology has rapidly became more powerful on scoring exams and es- says, especially after the 1990s, partially or wholly automated grading systems using computational methods have evolved and have become a major area of research. In particular, the demand of scoring of natural language responses has created a need for tools that can be applied to automatically grade these responses. In this paper, we focus on the concept of automatic grading of short answer questions such as are typical in the UK GCSE system, and providing useful feedback on their answers to students. We present experimental results on a dataset provided from the introductory computer science class in the Uni- versity of North Texas. We first apply standard data mining techniques to the corpus of student answers for the purpose of measuring similarity between the student answers and the model answer. This is based on the number of common words. We then evaluate the relation between these similarities and marks awarded by scorers. We then consider a clustering approach that groups student answers into clusters. Each cluster would be awarded the same mark, and the same feedback given to each answer in a cluster. In this manner, we demonstrate that clusters indicate the groups of students who are awarded the same or the similar scores. Words in each cluster are compared to show that clusters are constructed based on how many and which words of the model answer have been used. The main novelty in this paper is that we design a model to predict marks based on the similarities between the student answers and the model answer.
Guided Attention for Large Scale Scene Text Verification
Apr 23, 2018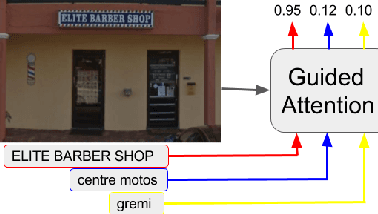
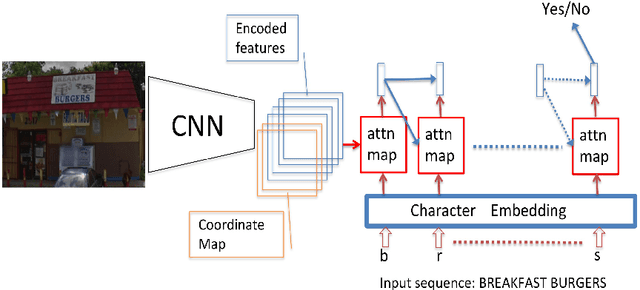

Many tasks are related to determining if a particular text string exists in an image. In this work, we propose a new framework that learns this task in an end-to-end way. The framework takes an image and a text string as input and then outputs the probability of the text string being present in the image. This is the first end-to-end framework that learns such relationships between text and images in scene text area. The framework does not require explicit scene text detection or recognition and thus no bounding box annotations are needed for it. It is also the first work in scene text area that tackles suh a weakly labeled problem. Based on this framework, we developed a model called Guided Attention. Our designed model achieves much better results than several state-of-the-art scene text reading based solutions for a challenging Street View Business Matching task. The task tries to find correct business names for storefront images and the dataset we collected for it is substantially larger, and more challenging than existing scene text dataset. This new real-world task provides a new perspective for studying scene text related problems. We also demonstrate the uniqueness of our task via a comparison between our problem and a typical Visual Question Answering problem.
Detecting events and key actors in multi-person videos
Mar 17, 2016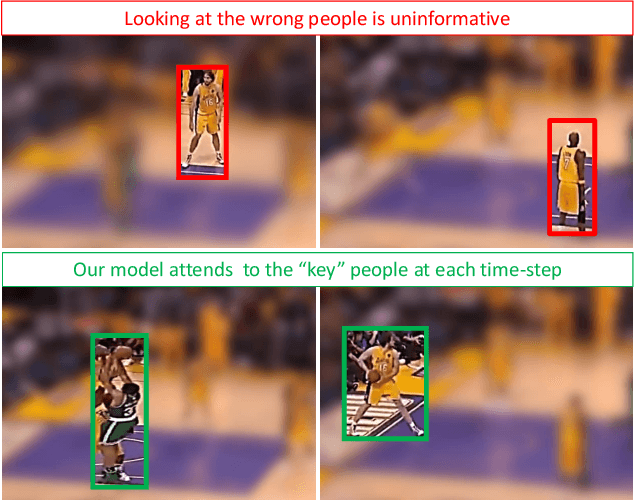
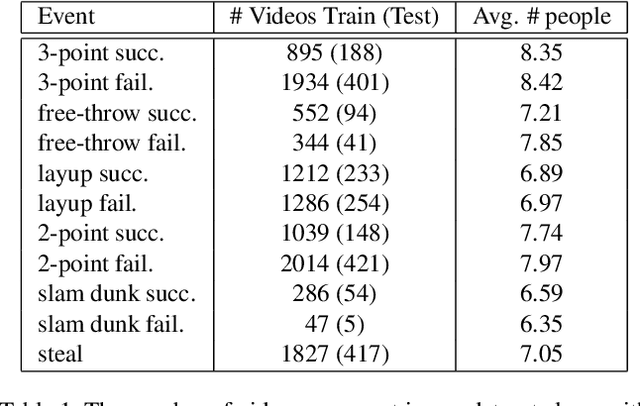

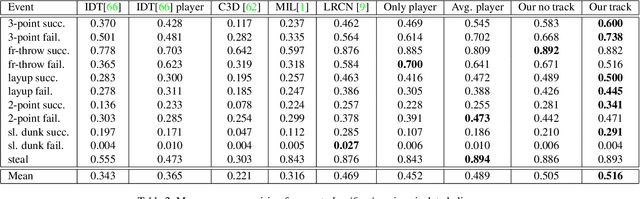
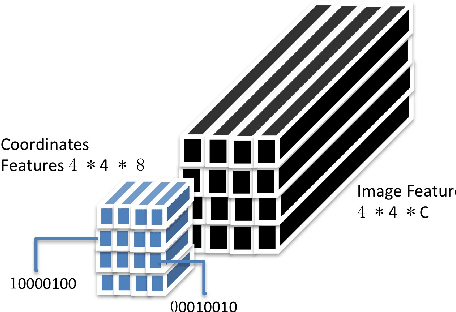
Multi-person event recognition is a challenging task, often with many people active in the scene but only a small subset contributing to an actual event. In this paper, we propose a model which learns to detect events in such videos while automatically "attending" to the people responsible for the event. Our model does not use explicit annotations regarding who or where those people are during training and testing. In particular, we track people in videos and use a recurrent neural network (RNN) to represent the track features. We learn time-varying attention weights to combine these features at each time-instant. The attended features are then processed using another RNN for event detection/classification. Since most video datasets with multiple people are restricted to a small number of videos, we also collected a new basketball dataset comprising 257 basketball games with 14K event annotations corresponding to 11 event classes. Our model outperforms state-of-the-art methods for both event classification and detection on this new dataset. Additionally, we show that the attention mechanism is able to consistently localize the relevant players.