 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Headlines for Online Math Questions
Nov 27, 2019

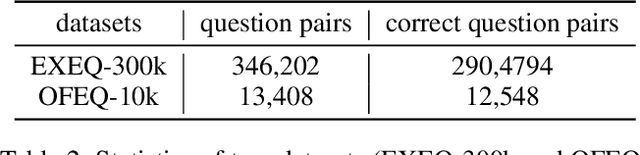
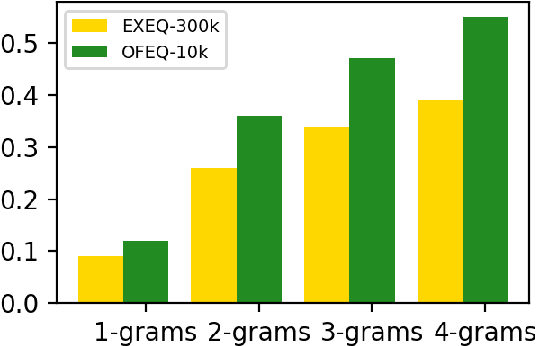
Mathematical equations are an important part of dissemination and communication of scientific information. Students, however, often feel challenged in reading and understanding math content and equations. With the development of the Web, students are posting their math questions online. Nevertheless, constructing a concise math headline that gives a good description of the posted detailed math question is nontrivial. In this study, we explore a novel summarization task denoted as geNerating A concise Math hEadline from a detailed math question (NAME). Compared to conventional summarization tasks, this task has two extra and essential constraints: 1) Detailed math questions consist of text and math equations which require a unified framework to jointly model textual and mathematical information; 2) Unlike text, math equations contain semantic and structural features, and both of them should be captured together. To address these issues, we propose MathSum, a novel summarization model which utilizes a pointer mechanism combined with a multi-head attention mechanism for mathematical representation augmentation. The pointer mechanism can either copy textual tokens or math tokens from source questions in order to generate math headlines. The multi-head attention mechanism is designed to enrich the representation of math equations by modeling and integrating both its semantic and structural features. For evaluation, we collect and make available two sets of real-world detailed math questions along with human-written math headlines, namely EXEQ-300k and OFEQ-10k. Experimental results demonstrate that our model (MathSum) significantly outperforms state-of-the-art models for both the EXEQ-300k and OFEQ-10k datasets.
TextContourNet: a Flexible and Effective Framework for Improving Scene Text Detection Architecture with a Multi-task Cascade
Sep 09, 2018
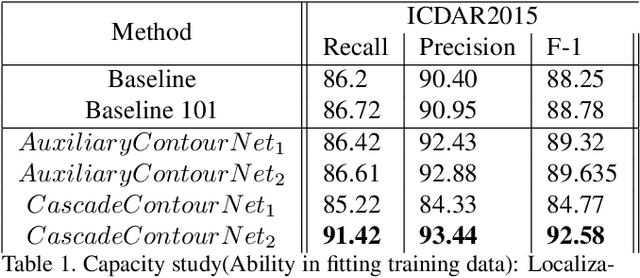

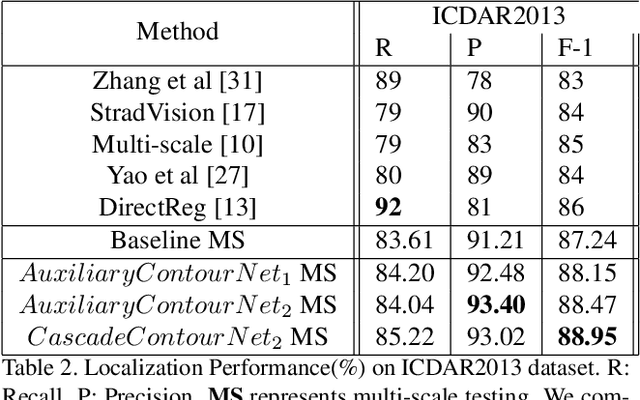
We study the problem of extracting text instance contour information from images and use it to assist scene text detection. We propose a novel and effective framework for this and experimentally demonstrate that: (1) A CNN that can be effectively used to extract instance-level text contour from natural images. (2) The extracted contour information can be used for better scene text detection. We propose two ways for learning the contour task together with the scene text detection: (1) as an auxiliary task and (2) as multi-task cascade. Extensive experiments with different benchmark datasets demonstrate that both designs improve the performance of a state-of-the-art scene text detector and that a multi-task cascade design achieves the best performance.
Guided Attention for Large Scale Scene Text Verification
Apr 23, 2018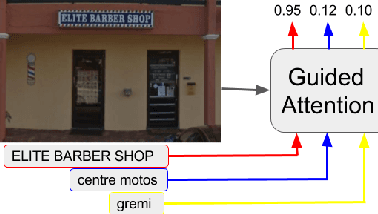
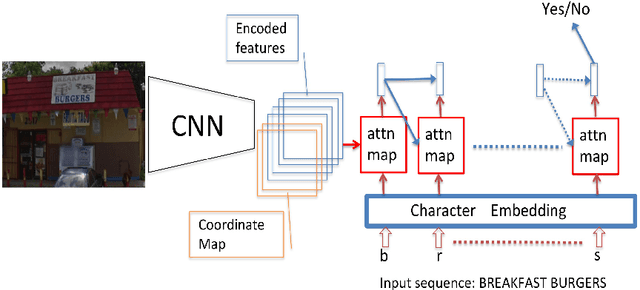
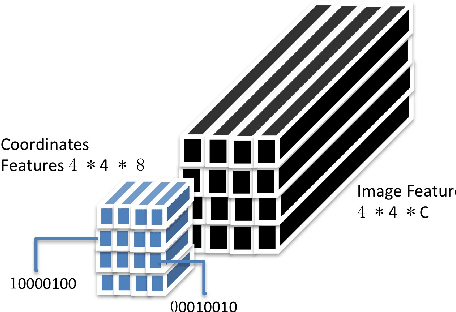

Many tasks are related to determining if a particular text string exists in an image. In this work, we propose a new framework that learns this task in an end-to-end way. The framework takes an image and a text string as input and then outputs the probability of the text string being present in the image. This is the first end-to-end framework that learns such relationships between text and images in scene text area. The framework does not require explicit scene text detection or recognition and thus no bounding box annotations are needed for it. It is also the first work in scene text area that tackles suh a weakly labeled problem. Based on this framework, we developed a model called Guided Attention. Our designed model achieves much better results than several state-of-the-art scene text reading based solutions for a challenging Street View Business Matching task. The task tries to find correct business names for storefront images and the dataset we collected for it is substantially larger, and more challenging than existing scene text dataset. This new real-world task provides a new perspective for studying scene text related problems. We also demonstrate the uniqueness of our task via a comparison between our problem and a typical Visual Question Answering problem.
Smart Library: Identifying Books in a Library using Richly Supervised Deep Scene Text Reading
Nov 22, 2016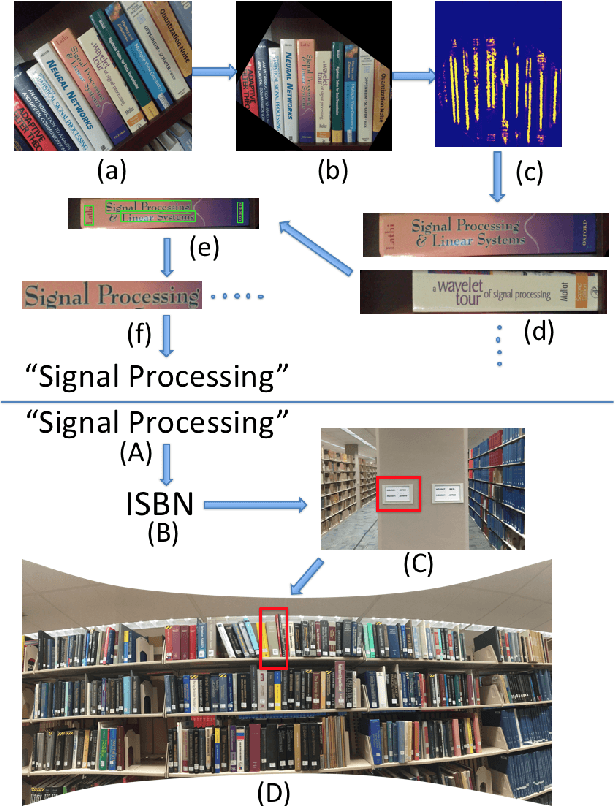
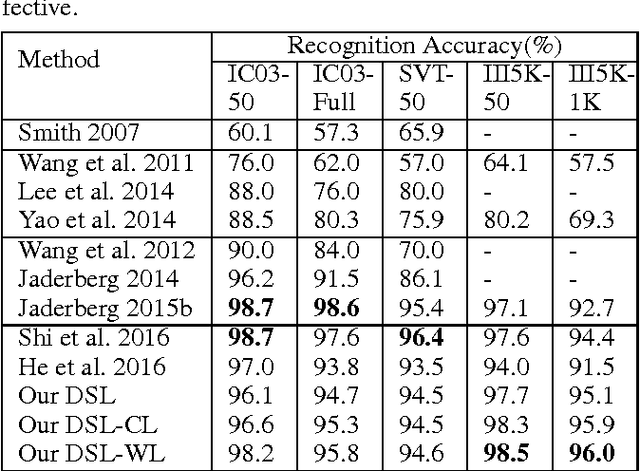
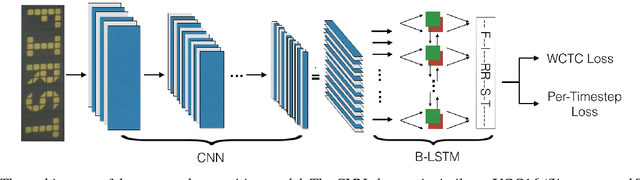

Physical library collections are valuable and long standing resources for knowledge and learning. However, managing books in a large bookshelf and finding books on it often leads to tedious manual work, especially for large book collections where books might be missing or misplaced. Recently, deep neural models, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) have achieved great success for scene text detection and recognition. Motivated by these recent successes, we aim to investigate their viability in facilitating book management, a task that introduces further challenges including large amounts of cluttered scene text, distortion, and varied lighting conditions. In this paper, we present a library inventory building and retrieval system based on scene text reading methods. We specifically design our scene text recognition model using rich supervision to accelerate training and achieve state-of-the-art performance on several benchmark datasets. Our proposed system has the potential to greatly reduce the amount of human labor required in managing book inventories as well as the space needed to store book information.