 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Attention for Large Scale Scene Text Verification
Apr 23, 2018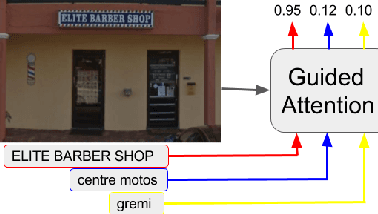
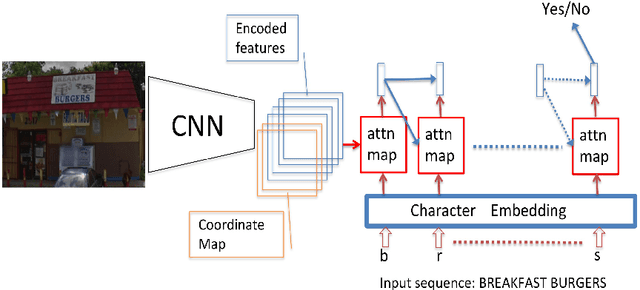
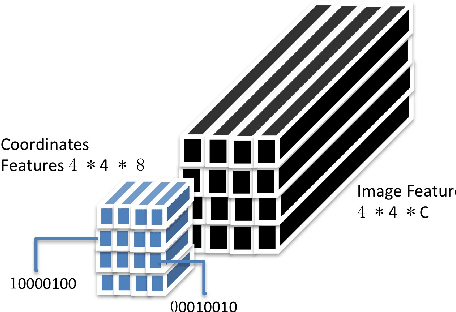

Many tasks are related to determining if a particular text string exists in an image. In this work, we propose a new framework that learns this task in an end-to-end way. The framework takes an image and a text string as input and then outputs the probability of the text string being present in the image. This is the first end-to-end framework that learns such relationships between text and images in scene text area. The framework does not require explicit scene text detection or recognition and thus no bounding box annotations are needed for it. It is also the first work in scene text area that tackles suh a weakly labeled problem. Based on this framework, we developed a model called Guided Attention. Our designed model achieves much better results than several state-of-the-art scene text reading based solutions for a challenging Street View Business Matching task. The task tries to find correct business names for storefront images and the dataset we collected for it is substantially larger, and more challenging than existing scene text dataset. This new real-world task provides a new perspective for studying scene text related problems. We also demonstrate the uniqueness of our task via a comparison between our problem and a typical Visual Question Answering problem.