 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Hiding in Medicine's Dark Matter? Learning with Missing Data in Medical Practices
Feb 09, 2024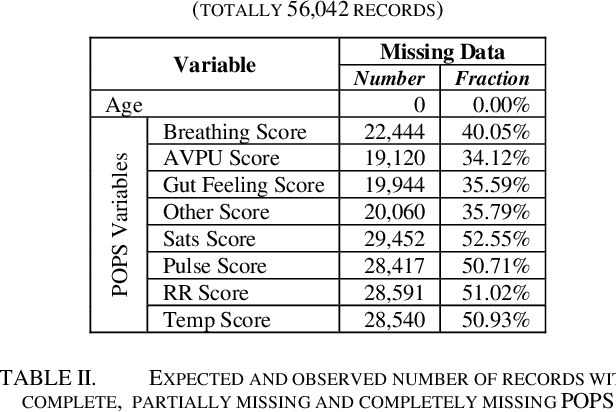

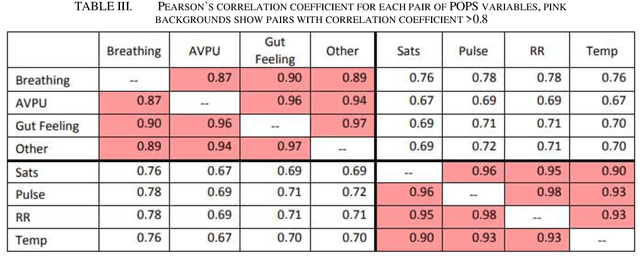
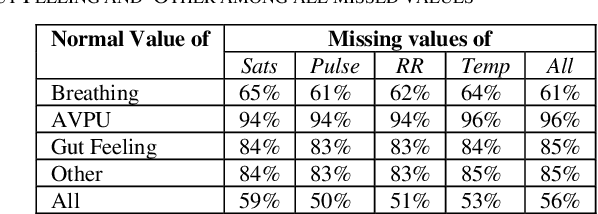
Electronic patient records (EPRs) produce a wealth of data but contain significant missing information. Understanding and handling this missing data is an important part of clinical data analysis and if left unaddressed could result in bias in analysis and distortion in critical conclusions. Missing data may be linked to health care professional practice patterns and imputation of missing data can increase the validity of clinical decisions. This study focuses on statistical approaches for understanding and interpreting the missing data and machine learning based clinical data imputation using a single centre's paediatric emergency data and the data from UK's largest clinical audit for traumatic injury database (TARN). In the study of 56,961 data points related to initial vital signs and observations taken on children presenting to an Emergency Department, we have shown that missing data are likely to be non-random and how these are linked to health care professional practice patterns. We have then examined 79 TARN fields with missing values for 5,791 trauma cases. Singular Value Decomposition (SVD) and k-Nearest Neighbour (kNN) based missing data imputation methods are used and imputation results against the original dataset are compared and statistically tested. We have concluded that the 1NN imputer is the best imputation which indicates a usual pattern of clinical decision making: find the most similar patients and take their attributes as imputation.
* 8 pages
An Informational Space Based Semantic Analysis for Scientific Texts
May 31, 2022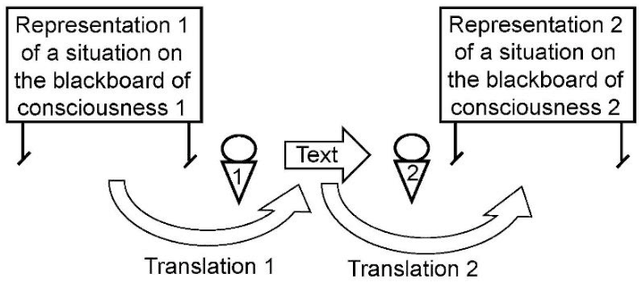
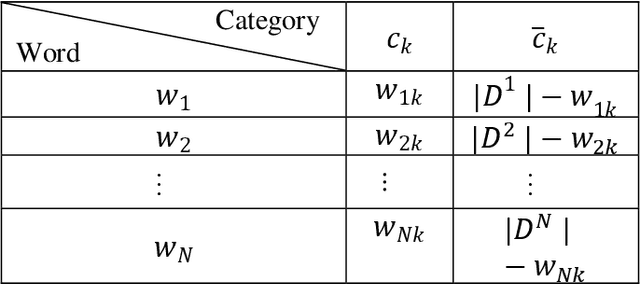
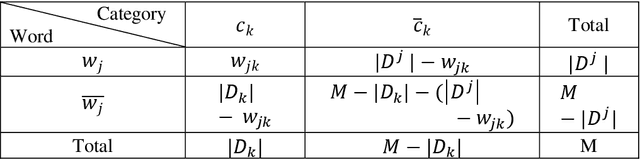

One major problem in Natural Language Processing is the automatic analysis and representation of human language. Human language is ambiguous and deeper understanding of semantics and creating human-to-machine interaction have required an effort in creating the schemes for act of communication and building common-sense knowledge bases for the 'meaning' in texts. This paper introduces computational methods for semantic analysis and the quantifying the meaning of short scientific texts. Computational methods extracting semantic feature are used to analyse the relations between texts of messages and 'representations of situations' for a newly created large collection of scientific texts, Leicester Scientific Corpus. The representation of scientific-specific meaning is standardised by replacing the situation representations, rather than psychological properties, with the vectors of some attributes: a list of scientific subject categories that the text belongs to. First, this paper introduces 'Meaning Space' in which the informational representation of the meaning is extracted from the occurrence of the word in texts across the scientific categories, i.e., the meaning of a word is represented by a vector of Relative Information Gain about the subject categories. Then, the meaning space is statistically analysed for Leicester Scientific Dictionary-Core and we investigate 'Principal Components of the Meaning' to describe the adequate dimensions of the meaning. The research in this paper conducts the base for the geometric representation of the meaning of texts.
* 19 pages. arXiv admin note: substantial text overlap with arXiv:2009.08859, arXiv:2004.13717
Semantic Analysis for Automated Evaluation of the Potential Impact of Research Articles
Apr 26, 2021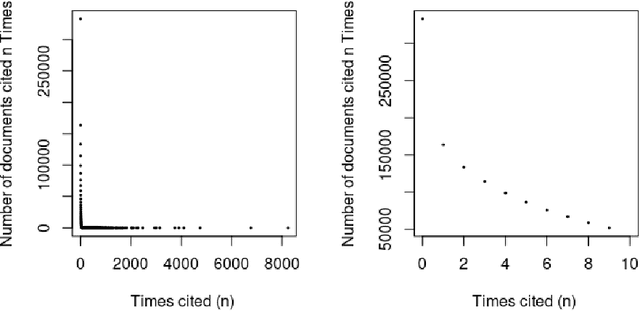
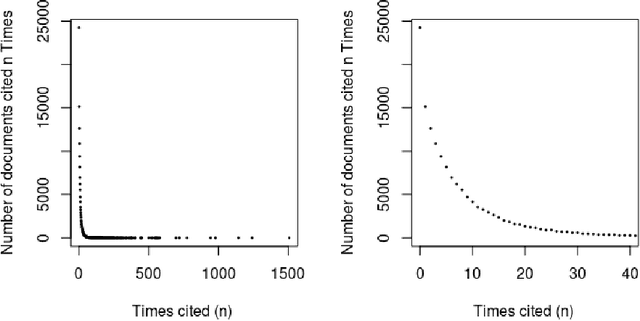
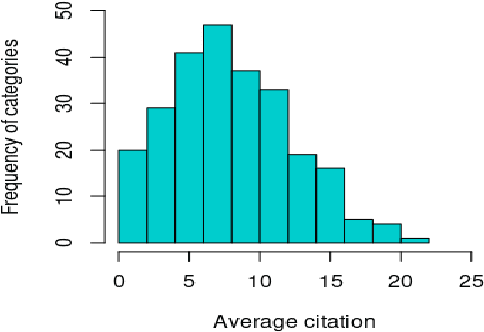
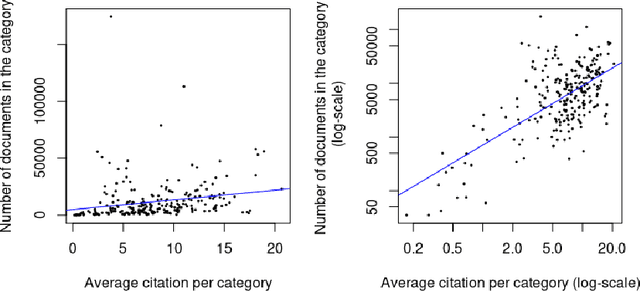
Can the analysis of the semantics of words used in the text of a scientific paper predict its future impact measured by citations? This study details examples of automated text classification that achieved 80% success rate in distinguishing between highly-cited and little-cited articles. Automated intelligent systems allow the identification of promising works that could become influential in the scientific community. The problems of quantifying the meaning of texts and representation of human language have been clear since the inception of Natural Language Processing. This paper presents a novel method for vector representation of text meaning based on information theory and show how this informational semantics is used for text classification on the basis of the Leicester Scientific Corpus. We describe the experimental framework used to evaluate the impact of scientific articles through their informational semantics. Our interest is in citation classification to discover how important semantics of texts are in predicting the citation count. We propose the semantics of texts as an important factor for citation prediction. For each article, our system extracts the abstract of paper, represents the words of the abstract as vectors in Meaning Space, automatically analyses the distribution of scientific categories (Web of Science categories) within the text of abstract, and then classifies papers according to citation counts (highly-cited, little-cited). We show that an informational approach to representing the meaning of a text has offered a way to effectively predict the scientific impact of research papers.
Principal Components of the Meaning
Sep 18, 2020In this paper we argue that (lexical) meaning in science can be represented in a 13 dimension Meaning Space. This space is constructed using principal component analysis (singular decomposition) on the matrix of word category relative information gains, where the categories are those used by the Web of Science, and the words are taken from a reduced word set from texts in the Web of Science. We show that this reduced word set plausibly represents all texts in the corpus, so that the principal component analysis has some objective meaning with respect to the corpus. We argue that 13 dimensions is adequate to describe the meaning of scientific texts, and hypothesise about the qualitative meaning of the principal components.
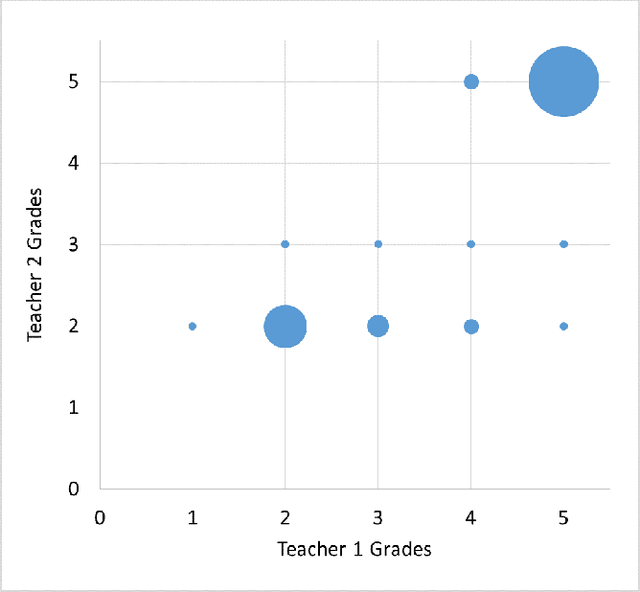
Automatic Short Answer Grading and Feedback Using Text Mining Methods
Jul 27, 2018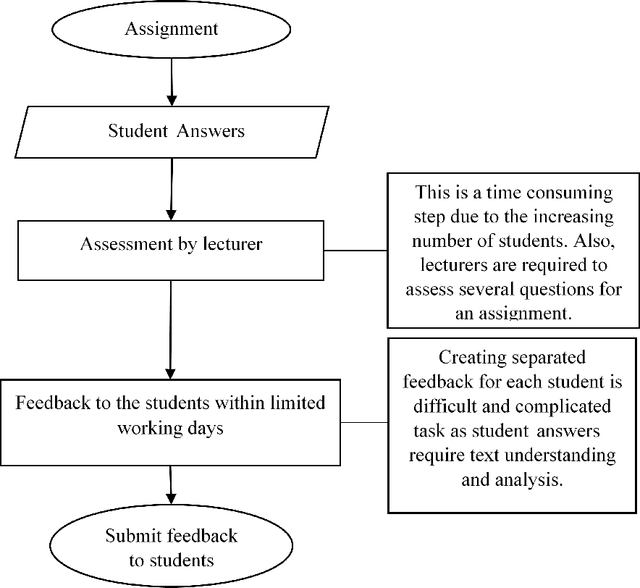


Automatic grading is not a new approach but the need to adapt the latest technology to automatic grading has become very important. As the technology has rapidly became more powerful on scoring exams and es- says, especially after the 1990s, partially or wholly automated grading systems using computational methods have evolved and have become a major area of research. In particular, the demand of scoring of natural language responses has created a need for tools that can be applied to automatically grade these responses. In this paper, we focus on the concept of automatic grading of short answer questions such as are typical in the UK GCSE system, and providing useful feedback on their answers to students. We present experimental results on a dataset provided from the introductory computer science class in the Uni- versity of North Texas. We first apply standard data mining techniques to the corpus of student answers for the purpose of measuring similarity between the student answers and the model answer. This is based on the number of common words. We then evaluate the relation between these similarities and marks awarded by scorers. We then consider a clustering approach that groups student answers into clusters. Each cluster would be awarded the same mark, and the same feedback given to each answer in a cluster. In this manner, we demonstrate that clusters indicate the groups of students who are awarded the same or the similar scores. Words in each cluster are compared to show that clusters are constructed based on how many and which words of the model answer have been used. The main novelty in this paper is that we design a model to predict marks based on the similarities between the student answers and the model answer.