 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Informational Space Based Semantic Analysis for Scientific Texts
Paper and Code
May 31, 2022
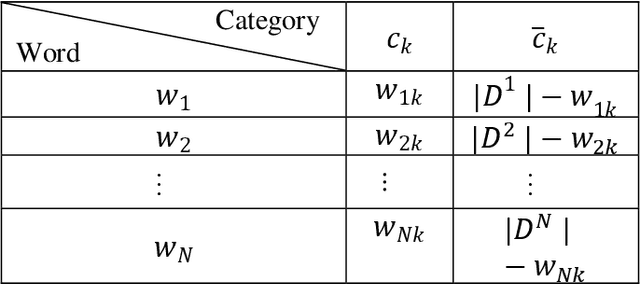
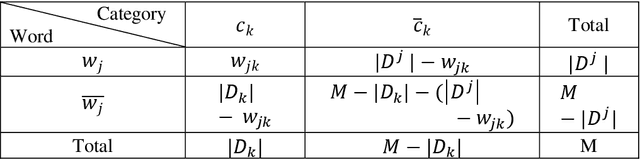

One major problem in Natural Language Processing is the automatic analysis and representation of human language. Human language is ambiguous and deeper understanding of semantics and creating human-to-machine interaction have required an effort in creating the schemes for act of communication and building common-sense knowledge bases for the 'meaning' in texts. This paper introduces computational methods for semantic analysis and the quantifying the meaning of short scientific texts. Computational methods extracting semantic feature are used to analyse the relations between texts of messages and 'representations of situations' for a newly created large collection of scientific texts, Leicester Scientific Corpus. The representation of scientific-specific meaning is standardised by replacing the situation representations, rather than psychological properties, with the vectors of some attributes: a list of scientific subject categories that the text belongs to. First, this paper introduces 'Meaning Space' in which the informational representation of the meaning is extracted from the occurrence of the word in texts across the scientific categories, i.e., the meaning of a word is represented by a vector of Relative Information Gain about the subject categories. Then, the meaning space is statistically analysed for Leicester Scientific Dictionary-Core and we investigate 'Principal Components of the Meaning' to describe the adequate dimensions of the meaning. The research in this paper conducts the base for the geometric representation of the meaning of texts.