 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the impact of social stress on the adaptive dynamics of COVID-19: Typing the behavior of naïve populations faced with epidemics
Nov 23, 2023In the context of natural disasters, human responses inevitably intertwine with natural factors. The COVID-19 pandemic, as a significant stress factor, has brought to light profound variations among different countries in terms of their adaptive dynamics in addressing the spread of infection outbreaks across different regions. This emphasizes the crucial role of cultural characteristics in natural disaster analysis. The theoretical understanding of large-scale epidemics primarily relies on mean-field kinetic models. However, conventional SIR-like models failed to fully explain the observed phenomena at the onset of the COVID-19 outbreak. These phenomena included the unexpected cessation of exponential growth, the reaching of plateaus, and the occurrence of multi-wave dynamics. In situations where an outbreak of a highly virulent and unfamiliar infection arises, it becomes crucial to respond swiftly at a non-medical level to mitigate the negative socio-economic impact. Here we present a theoretical examination of the first wave of the epidemic based on a simple SIRSS model (SIR with Social Stress). We conduct an analysis of the socio-cultural features of na\"ive population behaviors across various countries worldwide. The unique characteristics of each country/territory are encapsulated in only a few constants within our model, derived from the fitted COVID-19 statistics. These constants also reflect the societal response dynamics to the external stress factor, underscoring the importance of studying the mutual behavior of humanity and natural factors during global social disasters. Based on these distinctive characteristics of specific regions, local authorities can optimize their strategies to effectively combat epidemics until vaccines are developed.
Agile gesture recognition for capacitive sensing devices: adapting on-the-job
May 12, 2023Automated hand gesture recognition has been a focus of the AI community for decades. Traditionally, work in this domain revolved largely around scenarios assuming the availability of the flow of images of the user hands. This has partly been due to the prevalence of camera-based devices and the wide availability of image data. However, there is growing demand for gesture recognition technology that can be implemented on low-power devices using limited sensor data instead of high-dimensional inputs like hand images. In this work, we demonstrate a hand gesture recognition system and method that uses signals from capacitive sensors embedded into the etee hand controller. The controller generates real-time signals from each of the wearer five fingers. We use a machine learning technique to analyse the time series signals and identify three features that can represent 5 fingers within 500 ms. The analysis is composed of a two stage training strategy, including dimension reduction through principal component analysis and classification with K nearest neighbour. Remarkably, we found that this combination showed a level of performance which was comparable to more advanced methods such as supervised variational autoencoder. The base system can also be equipped with the capability to learn from occasional errors by providing it with an additional adaptive error correction mechanism. The results showed that the error corrector improve the classification performance in the base system without compromising its performance. The system requires no more than 1 ms of computing time per input sample, and is smaller than deep neural networks, demonstrating the feasibility of agile gesture recognition systems based on this technology.
Semantic Analysis for Automated Evaluation of the Potential Impact of Research Articles
Apr 26, 2021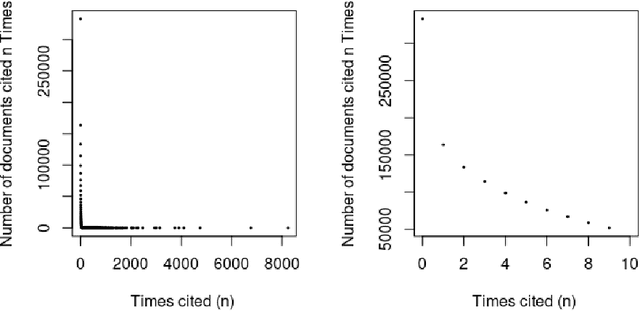
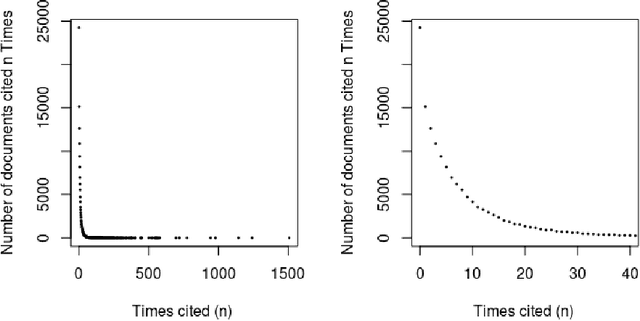
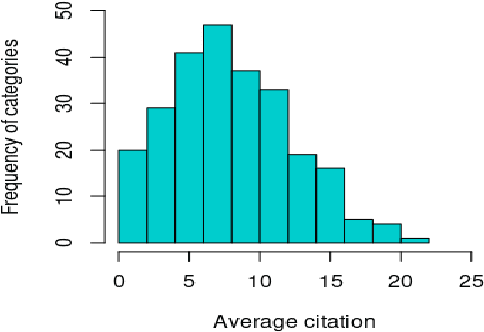
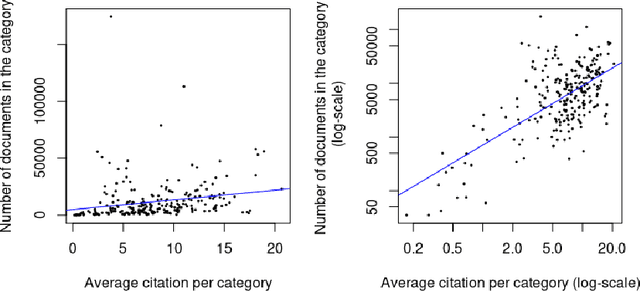
Can the analysis of the semantics of words used in the text of a scientific paper predict its future impact measured by citations? This study details examples of automated text classification that achieved 80% success rate in distinguishing between highly-cited and little-cited articles. Automated intelligent systems allow the identification of promising works that could become influential in the scientific community. The problems of quantifying the meaning of texts and representation of human language have been clear since the inception of Natural Language Processing. This paper presents a novel method for vector representation of text meaning based on information theory and show how this informational semantics is used for text classification on the basis of the Leicester Scientific Corpus. We describe the experimental framework used to evaluate the impact of scientific articles through their informational semantics. Our interest is in citation classification to discover how important semantics of texts are in predicting the citation count. We propose the semantics of texts as an important factor for citation prediction. For each article, our system extracts the abstract of paper, represents the words of the abstract as vectors in Meaning Space, automatically analyses the distribution of scientific categories (Web of Science categories) within the text of abstract, and then classifies papers according to citation counts (highly-cited, little-cited). We show that an informational approach to representing the meaning of a text has offered a way to effectively predict the scientific impact of research papers.
Principal Components of the Meaning
Sep 18, 2020In this paper we argue that (lexical) meaning in science can be represented in a 13 dimension Meaning Space. This space is constructed using principal component analysis (singular decomposition) on the matrix of word category relative information gains, where the categories are those used by the Web of Science, and the words are taken from a reduced word set from texts in the Web of Science. We show that this reduced word set plausibly represents all texts in the corpus, so that the principal component analysis has some objective meaning with respect to the corpus. We argue that 13 dimensions is adequate to describe the meaning of scientific texts, and hypothesise about the qualitative meaning of the principal components.
Automatic Short Answer Grading and Feedback Using Text Mining Methods
Jul 27, 2018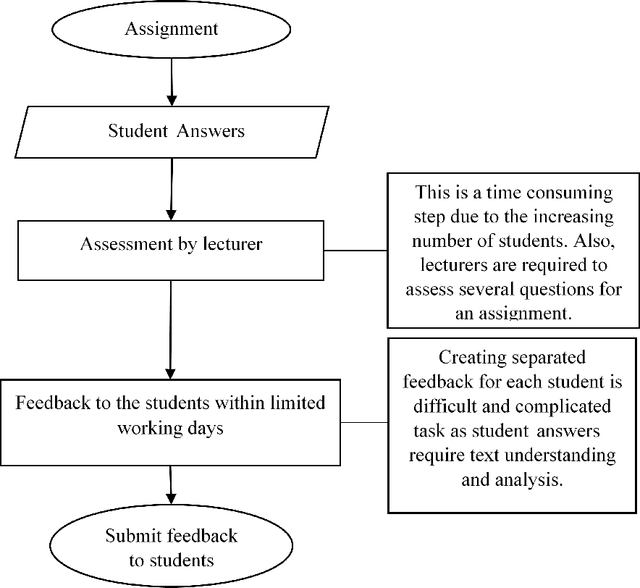


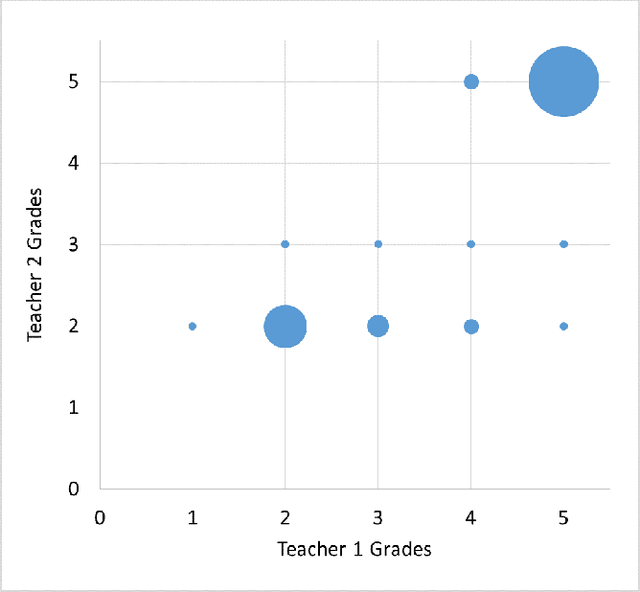
Automatic grading is not a new approach but the need to adapt the latest technology to automatic grading has become very important. As the technology has rapidly became more powerful on scoring exams and es- says, especially after the 1990s, partially or wholly automated grading systems using computational methods have evolved and have become a major area of research. In particular, the demand of scoring of natural language responses has created a need for tools that can be applied to automatically grade these responses. In this paper, we focus on the concept of automatic grading of short answer questions such as are typical in the UK GCSE system, and providing useful feedback on their answers to students. We present experimental results on a dataset provided from the introductory computer science class in the Uni- versity of North Texas. We first apply standard data mining techniques to the corpus of student answers for the purpose of measuring similarity between the student answers and the model answer. This is based on the number of common words. We then evaluate the relation between these similarities and marks awarded by scorers. We then consider a clustering approach that groups student answers into clusters. Each cluster would be awarded the same mark, and the same feedback given to each answer in a cluster. In this manner, we demonstrate that clusters indicate the groups of students who are awarded the same or the similar scores. Words in each cluster are compared to show that clusters are constructed based on how many and which words of the model answer have been used. The main novelty in this paper is that we design a model to predict marks based on the similarities between the student answers and the model answer.
Data complexity measured by principal graphs
Jan 02, 2013


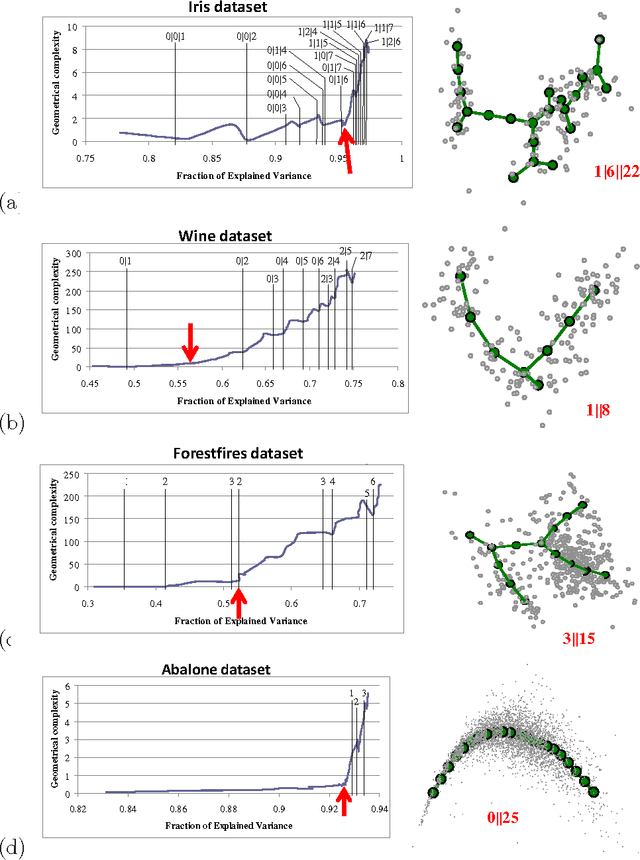
How to measure the complexity of a finite set of vectors embedded in a multidimensional space? This is a non-trivial question which can be approached in many different ways. Here we suggest a set of data complexity measures using universal approximators, principal cubic complexes. Principal cubic complexes generalise the notion of principal manifolds for datasets with non-trivial topologies. The type of the principal cubic complex is determined by its dimension and a grammar of elementary graph transformations. The simplest grammar produces principal trees. We introduce three natural types of data complexity: 1) geometric (deviation of the data's approximator from some "idealized" configuration, such as deviation from harmonicity); 2) structural (how many elements of a principal graph are needed to approximate the data), and 3) construction complexity (how many applications of elementary graph transformations are needed to construct the principal object starting from the simplest one). We compute these measures for several simulated and real-life data distributions and show them in the "accuracy-complexity" plots, helping to optimize the accuracy/complexity ratio. We discuss various issues connected with measuring data complexity. Software for computing data complexity measures from principal cubic complexes is provided as well.