 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData complexity measured by principal graphs
Paper and Code
Jan 02, 2013


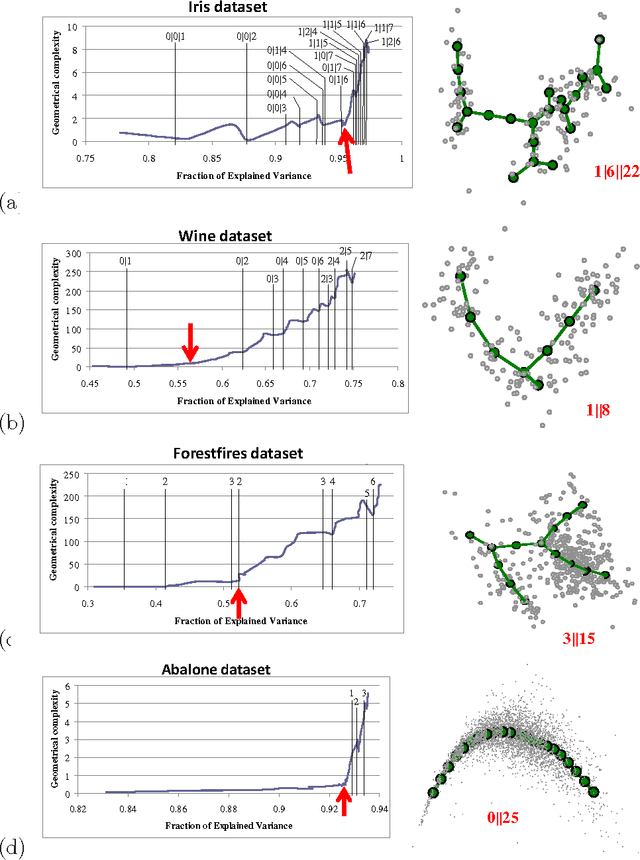
How to measure the complexity of a finite set of vectors embedded in a multidimensional space? This is a non-trivial question which can be approached in many different ways. Here we suggest a set of data complexity measures using universal approximators, principal cubic complexes. Principal cubic complexes generalise the notion of principal manifolds for datasets with non-trivial topologies. The type of the principal cubic complex is determined by its dimension and a grammar of elementary graph transformations. The simplest grammar produces principal trees. We introduce three natural types of data complexity: 1) geometric (deviation of the data's approximator from some "idealized" configuration, such as deviation from harmonicity); 2) structural (how many elements of a principal graph are needed to approximate the data), and 3) construction complexity (how many applications of elementary graph transformations are needed to construct the principal object starting from the simplest one). We compute these measures for several simulated and real-life data distributions and show them in the "accuracy-complexity" plots, helping to optimize the accuracy/complexity ratio. We discuss various issues connected with measuring data complexity. Software for computing data complexity measures from principal cubic complexes is provided as well.