 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpava: Accelerating Long-Video Understanding via Sequence-Parallelism-aware Approximate Attention
Jan 29, 2026The efficiency of long-video inference remains a critical bottleneck, mainly due to the dense computation in the prefill stage of Large Multimodal Models (LMMs). Existing methods either compress visual embeddings or apply sparse attention on a single GPU, yielding limited acceleration or degraded performance and restricting LMMs from handling longer, more complex videos. To overcome these issues, we propose Spava, a sequence-parallel framework with optimized attention that accelerates long-video inference across multiple GPUs. By distributing approximate attention, Spava reduces computation and increases parallelism, enabling efficient processing of more visual embeddings without compression and thereby improving task performance. System-level optimizations, such as load balancing and fused forward passes, further unleash the potential of Spava, delivering speedups of 12.72x, 1.70x, and 1.18x over FlashAttn, ZigZagRing, and APB, without notable performance loss. Code available at https://github.com/thunlp/APB
D$^2$GSLAM: 4D Dynamic Gaussian Splatting SLAM
Dec 10, 2025Recent advances in Dense Simultaneous Localization and Mapping (SLAM) have demonstrated remarkable performance in static environments. However, dense SLAM in dynamic environments remains challenging. Most methods directly remove dynamic objects and focus solely on static scene reconstruction, which ignores the motion information contained in these dynamic objects. In this paper, we present D$^2$GSLAM, a novel dynamic SLAM system utilizing Gaussian representation, which simultaneously performs accurate dynamic reconstruction and robust tracking within dynamic environments. Our system is composed of four key components: (i) We propose a geometric-prompt dynamic separation method to distinguish between static and dynamic elements of the scene. This approach leverages the geometric consistency of Gaussian representation and scene geometry to obtain coarse dynamic regions. The regions then serve as prompts to guide the refinement of the coarse mask for achieving accurate motion mask. (ii) To facilitate accurate and efficient mapping of the dynamic scene, we introduce dynamic-static composite representation that integrates static 3D Gaussians with dynamic 4D Gaussians. This representation allows for modeling the transitions between static and dynamic states of objects in the scene for composite mapping and optimization. (iii) We employ a progressive pose refinement strategy that leverages both the multi-view consistency of static scene geometry and motion information from dynamic objects to achieve accurate camera tracking. (iv) We introduce a motion consistency loss, which leverages the temporal continuity in object motions for accurate dynamic modeling. Our D$^2$GSLAM demonstrates superior performance on dynamic scenes in terms of mapping and tracking accuracy, while also showing capability in accurate dynamic modeling.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
FR-Spec: Accelerating Large-Vocabulary Language Models via Frequency-Ranked Speculative Sampling
Feb 20, 2025Speculative sampling has emerged as an important technique for accelerating the auto-regressive generation process of large language models (LLMs) by utilizing a draft-then-verify mechanism to produce multiple tokens per forward pass. While state-of-the-art speculative sampling methods use only a single layer and a language modeling (LM) head as the draft model to achieve impressive layer compression, their efficiency gains are substantially reduced for large-vocabulary LLMs, such as Llama-3-8B with a vocabulary of 128k tokens. To address this, we present FR-Spec, a frequency-ranked speculative sampling framework that optimizes draft candidate selection through vocabulary space compression. By constraining the draft search to a frequency-prioritized token subset, our method reduces LM Head computation overhead by 75% while ensuring the equivalence of the final output distribution. Experiments across multiple datasets demonstrate an average of 1.12$\times$ speedup over the state-of-the-art speculative sampling method EAGLE-2.
APB: Accelerating Distributed Long-Context Inference by Passing Compressed Context Blocks across GPUs
Feb 17, 2025While long-context inference is crucial for advancing large language model (LLM) applications, its prefill speed remains a significant bottleneck. Current approaches, including sequence parallelism strategies and compute reduction through approximate attention mechanisms, still fall short of delivering optimal inference efficiency. This hinders scaling the inputs to longer sequences and processing long-context queries in a timely manner. To address this, we introduce APB, an efficient long-context inference framework that leverages multi-host approximate attention to enhance prefill speed by reducing compute and enhancing parallelism simultaneously. APB introduces a communication mechanism for essential key-value pairs within a sequence parallelism framework, enabling a faster inference speed while maintaining task performance. We implement APB by incorporating a tailored FlashAttn kernel alongside optimized distribution strategies, supporting diverse models and parallelism configurations. APB achieves speedups of up to 9.2x, 4.2x, and 1.6x compared with FlashAttn, RingAttn, and StarAttn, respectively, without any observable task performance degradation. We provide the implementation and experiment code of APB in https://github.com/thunlp/APB.
Locret: Enhancing Eviction in Long-Context LLM Inference with Trained Retaining Heads
Oct 02, 2024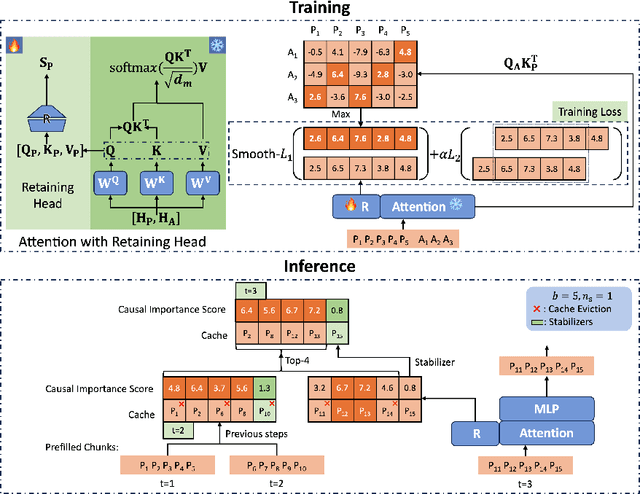
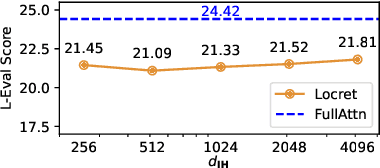
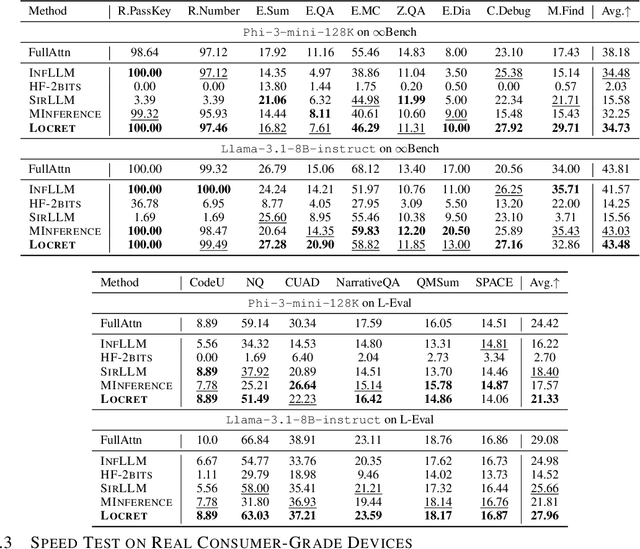
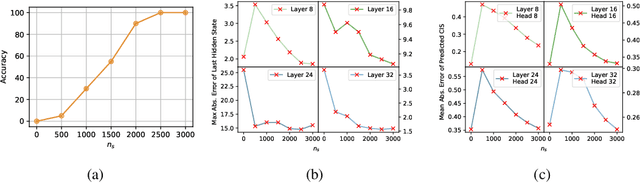
Large language models (LLMs) have shown remarkable advances in supporting long-context comprehension and processing tasks. However, scaling the generation inference of LLMs to such long contexts incurs significant additional computation load, and demands a substantial GPU memory footprint to maintain the key-value (KV) cache of transformer-based LLMs. Existing KV cache compression methods, such as quantization, face memory bottlenecks as context length increases, while static-sized caches, such as eviction, suffer from inefficient policies. These limitations restrict deployment on consumer-grade devices like a single Nvidia 4090 GPU. To overcome this, we propose Locret, a framework for long-context LLM inference that introduces retaining heads to evaluate the causal importance of KV cache units, allowing for more accurate eviction within a fixed cache size. Locret is fine-tuned on top of the frozen backbone LLM using a minimal amount of data from standard long-context SFT datasets. During inference, we evict low-importance cache units along with a chunked prefill pattern, significantly reducing peak GPU memory usage. We conduct an extensive empirical study to evaluate Locret, where the experimental results show that Locret outperforms the recent competitive approaches, including InfLLM, Quantization, SirLLM, and MInference, in terms of memory efficiency and the quality of generated contents -- Locret achieves over a 20x and 8x KV cache compression ratio compared to the full KV cache for Phi-3-mini-128K and Llama-3.1-8B-instruct. Additionally, Locret can be combined with other methods, such as quantization and token merging. To our knowledge, Locret is the first framework capable of deploying Llama-3.1-8B or similar models on a single Nvidia 4090 GPU, enabling 128K long-context inference without compromising generation quality, and requiring little additional system optimizations.
Dense Monocular Motion Segmentation Using Optical Flow and Pseudo Depth Map: A Zero-Shot Approach
Jun 27, 2024



Motion segmentation from a single moving camera presents a significant challenge in the field of computer vision. This challenge is compounded by the unknown camera movements and the lack of depth information of the scene. While deep learning has shown impressive capabilities in addressing these issues, supervised models require extensive training on massive annotated datasets, and unsupervised models also require training on large volumes of unannotated data, presenting significant barriers for both. In contrast, traditional methods based on optical flow do not require training data, however, they often fail to capture object-level information, leading to over-segmentation or under-segmentation. In addition, they also struggle in complex scenes with substantial depth variations and non-rigid motion, due to the overreliance of optical flow. To overcome these challenges, we propose an innovative hybrid approach that leverages the advantages of both deep learning methods and traditional optical flow based methods to perform dense motion segmentation without requiring any training. Our method initiates by automatically generating object proposals for each frame using foundation models. These proposals are then clustered into distinct motion groups using both optical flow and relative depth maps as motion cues. The integration of depth maps derived from state-of-the-art monocular depth estimation models significantly enhances the motion cues provided by optical flow, particularly in handling motion parallax issues. Our method is evaluated on the DAVIS-Moving and YTVOS-Moving datasets, and the results demonstrate that our method outperforms the best unsupervised method and closely matches with the state-of-theart supervised methods.
* For the offical publication, see https://crv.pubpub.org/pub/iunjzl55
Zero-Shot Monocular Motion Segmentation in the Wild by Combining Deep Learning with Geometric Motion Model Fusion
May 02, 2024Detecting and segmenting moving objects from a moving monocular camera is challenging in the presence of unknown camera motion, diverse object motions and complex scene structures. Most existing methods rely on a single motion cue to perform motion segmentation, which is usually insufficient when facing different complex environments. While a few recent deep learning based methods are able to combine multiple motion cues to achieve improved accuracy, they depend heavily on vast datasets and extensive annotations, making them less adaptable to new scenarios. To address these limitations, we propose a novel monocular dense segmentation method that achieves state-of-the-art motion segmentation results in a zero-shot manner. The proposed method synergestically combines the strengths of deep learning and geometric model fusion methods by performing geometric model fusion on object proposals. Experiments show that our method achieves competitive results on several motion segmentation datasets and even surpasses some state-of-the-art supervised methods on certain benchmarks, while not being trained on any data. We also present an ablation study to show the effectiveness of combining different geometric models together for motion segmentation, highlighting the value of our geometric model fusion strategy.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024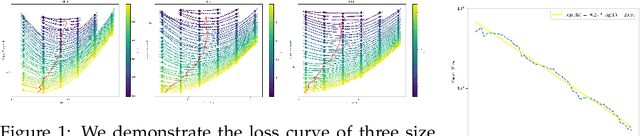


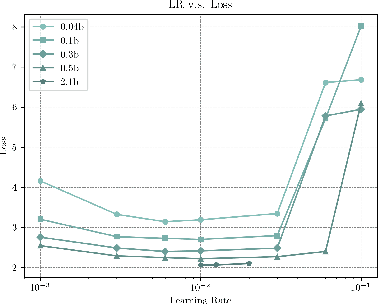
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
A Unified Model Selection Technique for Spectral Clustering Based Motion Segmentation
Mar 03, 2024Motion segmentation is a fundamental problem in computer vision and is crucial in various applications such as robotics, autonomous driving and action recognition. Recently, spectral clustering based methods have shown impressive results on motion segmentation in dynamic environments. These methods perform spectral clustering on motion affinity matrices to cluster objects or point trajectories in the scene into different motion groups. However, existing methods often need the number of motions present in the scene to be known, which significantly reduces their practicality. In this paper, we propose a unified model selection technique to automatically infer the number of motion groups for spectral clustering based motion segmentation methods by combining different existing model selection techniques together. We evaluate our method on the KT3DMoSeg dataset and achieve competitve results comparing to the baseline where the number of clusters is given as ground truth information.