 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMM:Concentrated Margin Maximization for Robust Document-Level Relation Extraction
Mar 18, 2025
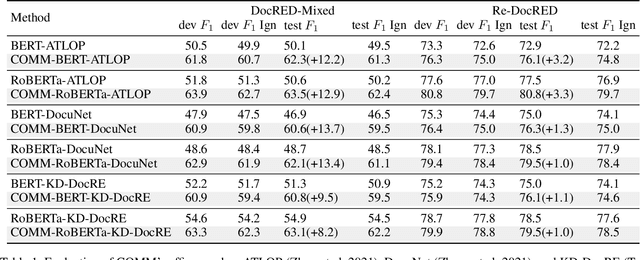
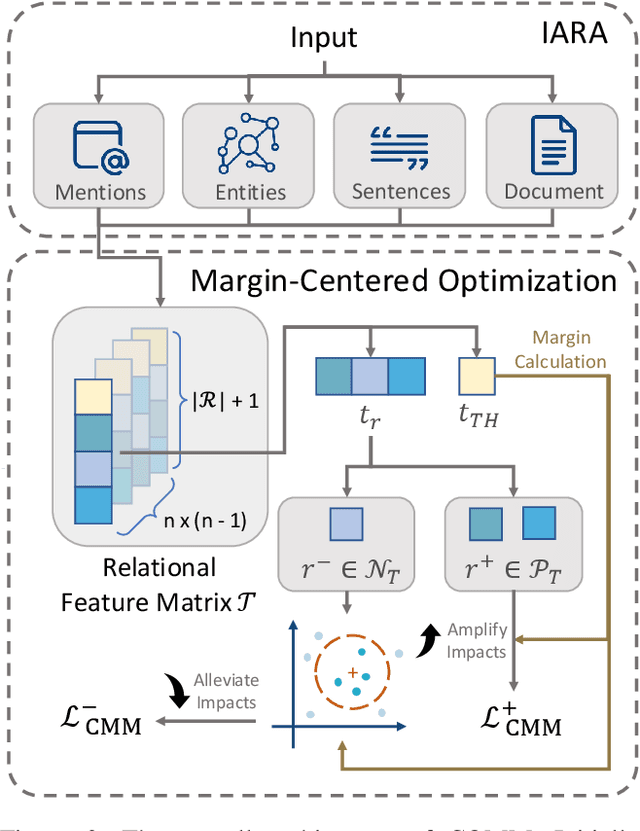

Document-level relation extraction (DocRE) is the process of identifying and extracting relations between entities that span multiple sentences within a document. Due to its realistic settings, DocRE has garnered increasing research attention in recent years. Previous research has mostly focused on developing sophisticated encoding models to better capture the intricate patterns between entity pairs. While these advancements are undoubtedly crucial, an even more foundational challenge lies in the data itself. The complexity inherent in DocRE makes the labeling process prone to errors, compounded by the extreme sparsity of positive relation samples, which is driven by both the limited availability of positive instances and the broad diversity of positive relation types. These factors can lead to biased optimization processes, further complicating the task of accurate relation extraction. Recognizing these challenges, we have developed a robust framework called \textit{\textbf{COMM}} to better solve DocRE. \textit{\textbf{COMM}} operates by initially employing an instance-aware reasoning method to dynamically capture pertinent information of entity pairs within the document and extract relational features. Following this, \textit{\textbf{COMM}} takes into account the distribution of relations and the difficulty of samples to dynamically adjust the margins between prediction logits and the decision threshold, a process we call Concentrated Margin Maximization. In this way, \textit{\textbf{COMM}} not only enhances the extraction of relevant relational features but also boosts DocRE performance by addressing the specific challenges posed by the data. Extensive experiments and analysis demonstrate the versatility and effectiveness of \textit{\textbf{COMM}}, especially its robustness when trained on low-quality data (achieves \textgreater 10\% performance gains).
FR-Spec: Accelerating Large-Vocabulary Language Models via Frequency-Ranked Speculative Sampling
Feb 20, 2025Speculative sampling has emerged as an important technique for accelerating the auto-regressive generation process of large language models (LLMs) by utilizing a draft-then-verify mechanism to produce multiple tokens per forward pass. While state-of-the-art speculative sampling methods use only a single layer and a language modeling (LM) head as the draft model to achieve impressive layer compression, their efficiency gains are substantially reduced for large-vocabulary LLMs, such as Llama-3-8B with a vocabulary of 128k tokens. To address this, we present FR-Spec, a frequency-ranked speculative sampling framework that optimizes draft candidate selection through vocabulary space compression. By constraining the draft search to a frequency-prioritized token subset, our method reduces LM Head computation overhead by 75% while ensuring the equivalence of the final output distribution. Experiments across multiple datasets demonstrate an average of 1.12$\times$ speedup over the state-of-the-art speculative sampling method EAGLE-2.
FocusLLM: Scaling LLM's Context by Parallel Decoding
Aug 21, 2024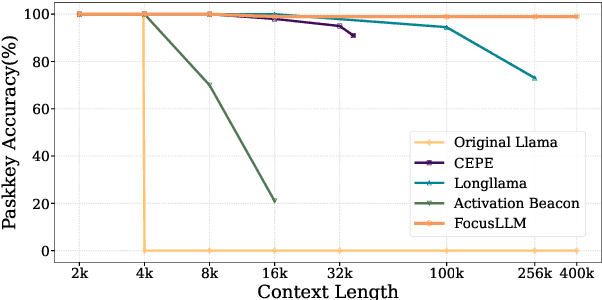

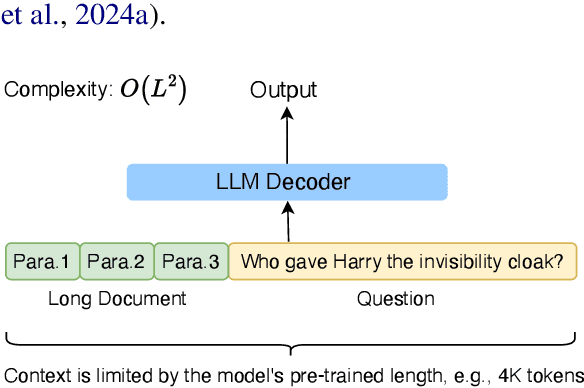

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.