 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVividMed: Vision Language Model with Versatile Visual Grounding for Medicine
Oct 16, 2024



Recent advancements in Vision Language Models (VLMs) have demonstrated remarkable promise in generating visually grounded responses. However, their application in the medical domain is hindered by unique challenges. For instance, most VLMs rely on a single method of visual grounding, whereas complex medical tasks demand more versatile approaches. Additionally, while most VLMs process only 2D images, a large portion of medical images are 3D. The lack of medical data further compounds these obstacles. To address these challenges, we present VividMed, a vision language model with versatile visual grounding for medicine. Our model supports generating both semantic segmentation masks and instance-level bounding boxes, and accommodates various imaging modalities, including both 2D and 3D data. We design a three-stage training procedure and an automatic data synthesis pipeline based on open datasets and models. Besides visual grounding tasks, VividMed also excels in other common downstream tasks, including Visual Question Answering (VQA) and report generation. Ablation studies empirically show that the integration of visual grounding ability leads to improved performance on these tasks. Our code is publicly available at https://github.com/function2-llx/MMMM.
FocusLLM: Scaling LLM's Context by Parallel Decoding
Aug 21, 2024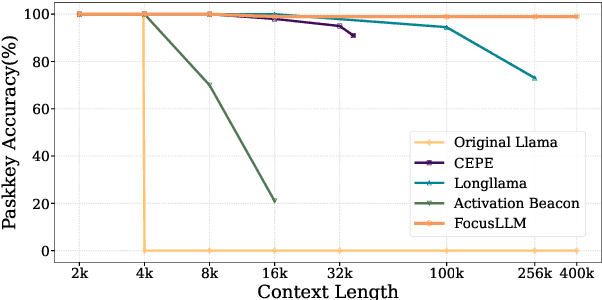

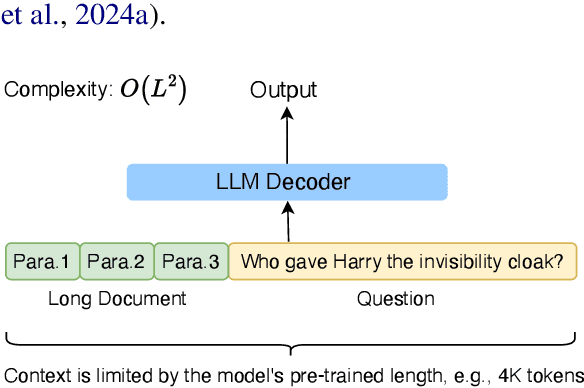

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.
HeMeNet: Heterogeneous Multichannel Equivariant Network for Protein Multitask Learning
Apr 02, 2024



Understanding and leveraging the 3D structures of proteins is central to a variety of biological and drug discovery tasks. While deep learning has been applied successfully for structure-based protein function prediction tasks, current methods usually employ distinct training for each task. However, each of the tasks is of small size, and such a single-task strategy hinders the models' performance and generalization ability. As some labeled 3D protein datasets are biologically related, combining multi-source datasets for larger-scale multi-task learning is one way to overcome this problem. In this paper, we propose a neural network model to address multiple tasks jointly upon the input of 3D protein structures. In particular, we first construct a standard structure-based multi-task benchmark called Protein-MT, consisting of 6 biologically relevant tasks, including affinity prediction and property prediction, integrated from 4 public datasets. Then, we develop a novel graph neural network for multi-task learning, dubbed Heterogeneous Multichannel Equivariant Network (HeMeNet), which is E(3) equivariant and able to capture heterogeneous relationships between different atoms. Besides, HeMeNet can achieve task-specific learning via the task-aware readout mechanism. Extensive evaluations on our benchmark verify the effectiveness of multi-task learning, and our model generally surpasses state-of-the-art models.
DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
Mar 20, 2024



Choreographers determine what the dances look like, while cameramen determine the final presentation of dances. Recently, various methods and datasets have showcased the feasibility of dance synthesis. However, camera movement synthesis with music and dance remains an unsolved challenging problem due to the scarcity of paired data. Thus, we present DCM, a new multi-modal 3D dataset, which for the first time combines camera movement with dance motion and music audio. This dataset encompasses 108 dance sequences (3.2 hours) of paired dance-camera-music data from the anime community, covering 4 music genres. With this dataset, we uncover that dance camera movement is multifaceted and human-centric, and possesses multiple influencing factors, making dance camera synthesis a more challenging task compared to camera or dance synthesis alone. To overcome these difficulties, we propose DanceCamera3D, a transformer-based diffusion model that incorporates a novel body attention loss and a condition separation strategy. For evaluation, we devise new metrics measuring camera movement quality, diversity, and dancer fidelity. Utilizing these metrics, we conduct extensive experiments on our DCM dataset, providing both quantitative and qualitative evidence showcasing the effectiveness of our DanceCamera3D model. Code and video demos are available at https://github.com/Carmenw1203/DanceCamera3D-Official.
Pre-trained Universal Medical Image Transformer
Dec 12, 2023Self-supervised learning has emerged as a viable method to leverage the abundance of unlabeled medical imaging data, addressing the challenge of labeled data scarcity in medical image analysis. In particular, masked image modeling (MIM) with visual token reconstruction has shown promising results in the general computer vision (CV) domain and serves as a candidate for medical image analysis. However, the presence of heterogeneous 2D and 3D medical images often limits the volume and diversity of training data that can be effectively used for a single model structure. In this work, we propose a spatially adaptive convolution (SAC) module, which adaptively adjusts convolution parameters based on the voxel spacing of the input images. Employing this SAC module, we build a universal visual tokenizer and a universal Vision Transformer (ViT) capable of effectively processing a wide range of medical images with various imaging modalities and spatial properties. Moreover, in order to enhance the robustness of the visual tokenizer's reconstruction objective for MIM, we suggest to generalize the discrete token output of the visual tokenizer to a probabilistic soft token. We show that the generalized soft token representation can be effectively integrated with the prior distribution regularization through a constructive interpretation. As a result, we pre-train a universal visual tokenizer followed by a universal ViT via visual token reconstruction on 55 public medical image datasets, comprising over 9 million 2D slices (including over 48,000 3D images). This represents the largest, most comprehensive, and diverse dataset for pre-training 3D medical image models to our knowledge. Experimental results on downstream medical image classification and segmentation tasks demonstrate the superior performance of our model and improved label efficiency.
Feature Extraction, Modulation and Recognition of Mixed Signal Based on SVM
Jul 28, 2022



This paper introduces likelihood-based and feature-based modulation recognition methods. In the feature-based modulation simulation part, instantaneous feature, cyclic spectrum, high-order cumulants, and wavelet transform features are used as the entry point, and six digital signals including 2ASK, 4ASK, BPSK, QPSK, 2FSK and 4FSK are simulated, showing the difference of signals in multiple dimensions
MAVEN: A Massive General Domain Event Detection Dataset
Apr 28, 2020
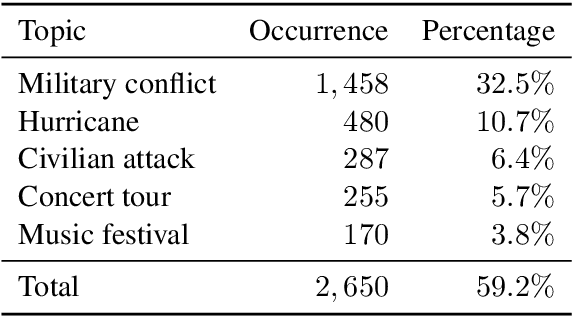
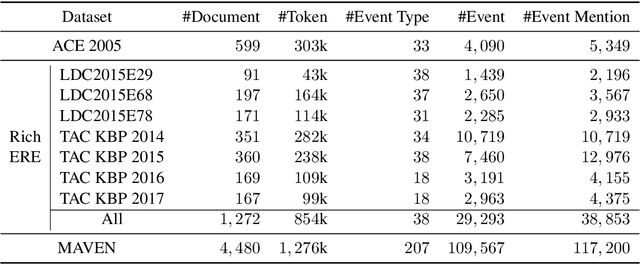
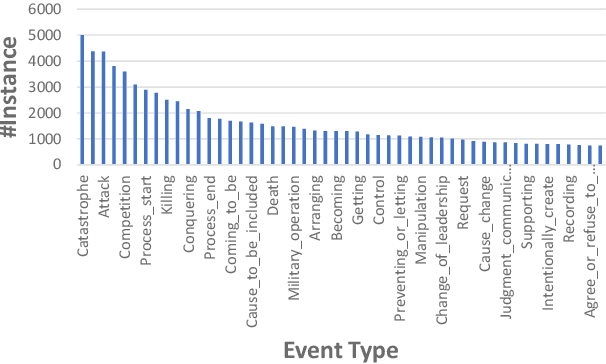
Event detection (ED), which identifies event trigger words and classifies event types according to contexts, is the first and most fundamental step for extracting event knowledge from plain text. Most existing datasets exhibit the following issues that limit further development of ED: (1) Small scale of existing datasets is not sufficient for training and stably benchmarking increasingly sophisticated modern neural methods. (2) Limited event types of existing datasets lead to the trained models cannot be easily adapted to general-domain scenarios. To alleviate these problems, we present a MAssive eVENt detection dataset (MAVEN), which contains 4,480 Wikipedia documents, 117,200 event mention instances, and 207 event types. MAVEN alleviates the lack of data problem and covers much more general event types. Besides the dataset, we reproduce the recent state-of-the-art ED models and conduct a thorough evaluation for these models on MAVEN. The experimental results and empirical analyses show that existing ED methods cannot achieve promising results as on the small datasets, which suggests ED in real world remains a challenging task and requires further research efforts. The dataset and baseline code will be released in the future to promote this field.