 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusLLM: Scaling LLM's Context by Parallel Decoding
Paper and Code
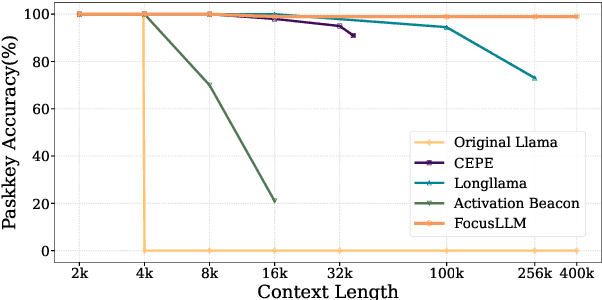

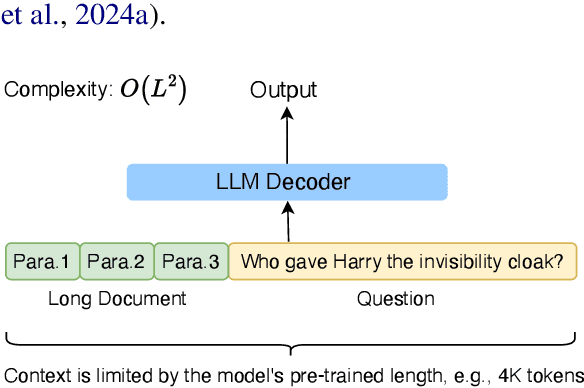

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.