 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
Jan 05, 2026Visual generation is dominated by three paradigms: AutoRegressive (AR), diffusion, and Visual AutoRegressive (VAR) models. Unlike AR and diffusion, VARs operate on heterogeneous input structures across their generation steps, which creates severe asynchronous policy conflicts. This issue becomes particularly acute in reinforcement learning (RL) scenarios, leading to unstable training and suboptimal alignment. To resolve this, we propose a novel framework to enhance Group Relative Policy Optimization (GRPO) by explicitly managing these conflicts. Our method integrates three synergistic components: 1) a stabilizing intermediate reward to guide early-stage generation; 2) a dynamic time-step reweighting scheme for precise credit assignment; and 3) a novel mask propagation algorithm, derived from principles of Reward Feedback Learning (ReFL), designed to isolate optimization effects both spatially and temporally. Our approach demonstrates significant improvements in sample quality and objective alignment over the vanilla GRPO baseline, enabling robust and effective optimization for VAR models.
Efficient Controllable Diffusion via Optimal Classifier Guidance
May 27, 2025The controllable generation of diffusion models aims to steer the model to generate samples that optimize some given objective functions. It is desirable for a variety of applications including image generation, molecule generation, and DNA/sequence generation. Reinforcement Learning (RL) based fine-tuning of the base model is a popular approach but it can overfit the reward function while requiring significant resources. We frame controllable generation as a problem of finding a distribution that optimizes a KL-regularized objective function. We present SLCD -- Supervised Learning based Controllable Diffusion, which iteratively generates online data and trains a small classifier to guide the generation of the diffusion model. Similar to the standard classifier-guided diffusion, SLCD's key computation primitive is classification and does not involve any complex concepts from RL or control. Via a reduction to no-regret online learning analysis, we show that under KL divergence, the output from SLCD provably converges to the optimal solution of the KL-regularized objective. Further, we empirically demonstrate that SLCD can generate high quality samples with nearly the same inference time as the base model in both image generation with continuous diffusion and biological sequence generation with discrete diffusion. Our code is available at https://github.com/Owen-Oertell/slcd
Dual-Flow: Transferable Multi-Target, Instance-Agnostic Attacks via In-the-wild Cascading Flow Optimization
Feb 05, 2025



Adversarial attacks are widely used to evaluate model robustness, and in black-box scenarios, the transferability of these attacks becomes crucial. Existing generator-based attacks have excellent generalization and transferability due to their instance-agnostic nature. However, when training generators for multi-target tasks, the success rate of transfer attacks is relatively low due to the limitations of the model's capacity. To address these challenges, we propose a novel Dual-Flow framework for multi-target instance-agnostic adversarial attacks, utilizing Cascading Distribution Shift Training to develop an adversarial velocity function. Extensive experiments demonstrate that Dual-Flow significantly improves transferability over previous multi-target generative attacks. For example, it increases the success rate from Inception-v3 to ResNet-152 by 34.58%. Furthermore, our attack method shows substantially stronger robustness against defense mechanisms, such as adversarially trained models.
Skinned Motion Retargeting with Dense Geometric Interaction Perception
Oct 28, 2024Capturing and maintaining geometric interactions among different body parts is crucial for successful motion retargeting in skinned characters. Existing approaches often overlook body geometries or add a geometry correction stage after skeletal motion retargeting. This results in conflicts between skeleton interaction and geometry correction, leading to issues such as jittery, interpenetration, and contact mismatches. To address these challenges, we introduce a new retargeting framework, MeshRet, which directly models the dense geometric interactions in motion retargeting. Initially, we establish dense mesh correspondences between characters using semantically consistent sensors (SCS), effective across diverse mesh topologies. Subsequently, we develop a novel spatio-temporal representation called the dense mesh interaction (DMI) field. This field, a collection of interacting SCS feature vectors, skillfully captures both contact and non-contact interactions between body geometries. By aligning the DMI field during retargeting, MeshRet not only preserves motion semantics but also prevents self-interpenetration and ensures contact preservation. Extensive experiments on the public Mixamo dataset and our newly-collected ScanRet dataset demonstrate that MeshRet achieves state-of-the-art performance. Code available at https://github.com/abcyzj/MeshRet.
PlacidDreamer: Advancing Harmony in Text-to-3D Generation
Jul 19, 2024Recently, text-to-3D generation has attracted significant attention, resulting in notable performance enhancements. Previous methods utilize end-to-end 3D generation models to initialize 3D Gaussians, multi-view diffusion models to enforce multi-view consistency, and text-to-image diffusion models to refine details with score distillation algorithms. However, these methods exhibit two limitations. Firstly, they encounter conflicts in generation directions since different models aim to produce diverse 3D assets. Secondly, the issue of over-saturation in score distillation has not been thoroughly investigated and solved. To address these limitations, we propose PlacidDreamer, a text-to-3D framework that harmonizes initialization, multi-view generation, and text-conditioned generation with a single multi-view diffusion model, while simultaneously employing a novel score distillation algorithm to achieve balanced saturation. To unify the generation direction, we introduce the Latent-Plane module, a training-friendly plug-in extension that enables multi-view diffusion models to provide fast geometry reconstruction for initialization and enhanced multi-view images to personalize the text-to-image diffusion model. To address the over-saturation problem, we propose to view score distillation as a multi-objective optimization problem and introduce the Balanced Score Distillation algorithm, which offers a Pareto Optimal solution that achieves both rich details and balanced saturation. Extensive experiments validate the outstanding capabilities of our PlacidDreamer. The code is available at \url{https://github.com/HansenHuang0823/PlacidDreamer}.
DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
Mar 20, 2024



Choreographers determine what the dances look like, while cameramen determine the final presentation of dances. Recently, various methods and datasets have showcased the feasibility of dance synthesis. However, camera movement synthesis with music and dance remains an unsolved challenging problem due to the scarcity of paired data. Thus, we present DCM, a new multi-modal 3D dataset, which for the first time combines camera movement with dance motion and music audio. This dataset encompasses 108 dance sequences (3.2 hours) of paired dance-camera-music data from the anime community, covering 4 music genres. With this dataset, we uncover that dance camera movement is multifaceted and human-centric, and possesses multiple influencing factors, making dance camera synthesis a more challenging task compared to camera or dance synthesis alone. To overcome these difficulties, we propose DanceCamera3D, a transformer-based diffusion model that incorporates a novel body attention loss and a condition separation strategy. For evaluation, we devise new metrics measuring camera movement quality, diversity, and dancer fidelity. Utilizing these metrics, we conduct extensive experiments on our DCM dataset, providing both quantitative and qualitative evidence showcasing the effectiveness of our DanceCamera3D model. Code and video demos are available at https://github.com/Carmenw1203/DanceCamera3D-Official.
SDDM: Score-Decomposed Diffusion Models on Manifolds for Unpaired Image-to-Image Translation
Aug 04, 2023
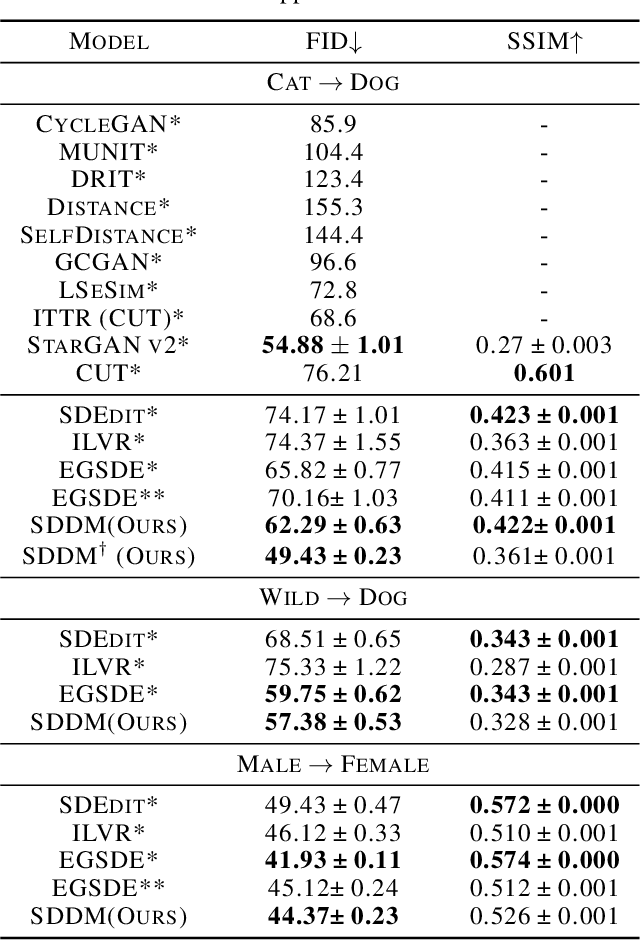


Recent score-based diffusion models (SBDMs) show promising results in unpaired image-to-image translation (I2I). However, existing methods, either energy-based or statistically-based, provide no explicit form of the interfered intermediate generative distributions. This work presents a new score-decomposed diffusion model (SDDM) on manifolds to explicitly optimize the tangled distributions during image generation. SDDM derives manifolds to make the distributions of adjacent time steps separable and decompose the score function or energy guidance into an image ``denoising" part and a content ``refinement" part. To refine the image in the same noise level, we equalize the refinement parts of the score function and energy guidance, which permits multi-objective optimization on the manifold. We also leverage the block adaptive instance normalization module to construct manifolds with lower dimensions but still concentrated with the perturbed reference image. SDDM outperforms existing SBDM-based methods with much fewer diffusion steps on several I2I benchmarks.