 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Complex Dynamics to DynFormer: Rethinking Transformers for PDEs
Mar 03, 2026Partial differential equations (PDEs) are fundamental for modeling complex physical systems, yet classical numerical solvers face prohibitive computational costs in high-dimensional and multi-scale regimes. While Transformer-based neural operators have emerged as powerful data-driven alternatives, they conventionally treat all discretized spatial points as uniform, independent tokens. This monolithic approach ignores the intrinsic scale separation of physical fields, applying computationally prohibitive global attention that redundantly mixes smooth large-scale dynamics with high-frequency fluctuations. Rethinking Transformers through the lens of complex dynamics, we propose DynFormer, a novel dynamics-informed neural operator. Rather than applying a uniform attention mechanism across all scales, DynFormer explicitly assigns specialized network modules to distinct physical scales. It leverages a Spectral Embedding to isolate low-frequency modes, enabling a Kronecker-structured attention mechanism to efficiently capture large-scale global interactions with reduced complexity. Concurrently, we introduce a Local-Global-Mixing transformation. This module utilizes nonlinear multiplicative frequency mixing to implicitly reconstruct the small-scale, fast-varying turbulent cascades that are slaved to the macroscopic state, without incurring the cost of global attention. Integrating these modules into a hybrid evolutionary architecture ensures robust long-term temporal stability. Extensive memory-aligned evaluations across four PDE benchmarks demonstrate that DynFormer achieves up to a 95% reduction in relative error compared to state-of-the-art baselines, while significantly reducing GPU memory consumption. Our results establish that embedding first-principles physical dynamics into Transformer architectures yields a highly scalable, theoretically grounded blueprint for PDE surrogate modeling.
Recurrent Preference Memory for Efficient Long-Sequence Generative Recommendation
Feb 13, 2026Generative recommendation (GenRec) models typically model user behavior via full attention, but scaling to lifelong sequences is hindered by prohibitive computational costs and noise accumulation from stochastic interactions. To address these challenges, we introduce Rec2PM, a framework that compresses long user interaction histories into compact Preference Memory tokens. Unlike traditional recurrent methods that suffer from serial training, Rec2PM employs a novel self-referential teacher-forcing strategy: it leverages a global view of the history to generate reference memories, which serve as supervision targets for parallelized recurrent updates. This allows for fully parallel training while maintaining the capability for iterative updates during inference. Additionally, by representing memory as token embeddings rather than extensive KV caches, Rec2PM achieves extreme storage efficiency. Experiments on large-scale benchmarks show that Rec2PM significantly reduces inference latency and memory footprint while achieving superior accuracy compared to full-sequence models. Analysis reveals that the Preference Memory functions as a denoising Information Bottleneck, effectively filtering interaction noise to capture robust long-term interests.
Effective MoE-based LLM Compression by Exploiting Heterogeneous Inter-Group Experts Routing Frequency and Information Density
Feb 11, 2026Mixture-of-Experts (MoE) based Large Language Models (LLMs) have achieved superior performance, yet the massive memory overhead caused by storing multiple expert networks severely hinders their practical deployment. Singular Value Decomposition (SVD)-based compression has emerged as a promising post-training technique; however, most existing methods apply uniform rank allocation or rely solely on static weight properties. This overlooks the substantial heterogeneity in expert utilization observed in MoE models, where frequent routing patterns and intrinsic information density vary significantly across experts. In this work, we propose RFID-MoE, an effective framework for MoE compression by exploiting heterogeneous Routing Frequency and Information Density. We first introduce a fused metric that combines expert activation frequency with effective rank to measure expert importance, adaptively allocating higher ranks to critical expert groups under a fixed budget. Moreover, instead of discarding compression residuals, we reconstruct them via a parameter-efficient sparse projection mechanism to recover lost information with minimal parameter overhead. Extensive experiments on representative MoE LLMs (e.g., Qwen3, DeepSeekMoE) across multiple compression ratios demonstrate that RFID-MoE consistently outperforms state-of-the-art methods like MoBE and D2-MoE. Notably, RFID-MoE achieves a perplexity of 16.92 on PTB with the Qwen3-30B model at a 60% compression ratio, reducing perplexity by over 8.0 compared to baselines, and improves zero-shot accuracy on HellaSwag by approximately 8%.
AInsteinBench: Benchmarking Coding Agents on Scientific Repositories
Dec 24, 2025We introduce AInsteinBench, a large-scale benchmark for evaluating whether large language model (LLM) agents can operate as scientific computing development agents within real research software ecosystems. Unlike existing scientific reasoning benchmarks which focus on conceptual knowledge, or software engineering benchmarks that emphasize generic feature implementation and issue resolving, AInsteinBench evaluates models in end-to-end scientific development settings grounded in production-grade scientific repositories. The benchmark consists of tasks derived from maintainer-authored pull requests across six widely used scientific codebases, spanning quantum chemistry, quantum computing, molecular dynamics, numerical relativity, fluid dynamics, and cheminformatics. All benchmark tasks are carefully curated through multi-stage filtering and expert review to ensure scientific challenge, adequate test coverage, and well-calibrated difficulty. By leveraging evaluation in executable environments, scientifically meaningful failure modes, and test-driven verification, AInsteinBench measures a model's ability to move beyond surface-level code generation toward the core competencies required for computational scientific research.
Context-Aware Autoregressive Models for Multi-Conditional Image Generation
May 18, 2025Autoregressive transformers have recently shown impressive image generation quality and efficiency on par with state-of-the-art diffusion models. Unlike diffusion architectures, autoregressive models can naturally incorporate arbitrary modalities into a single, unified token sequence--offering a concise solution for multi-conditional image generation tasks. In this work, we propose $\textbf{ContextAR}$, a flexible and effective framework for multi-conditional image generation. ContextAR embeds diverse conditions (e.g., canny edges, depth maps, poses) directly into the token sequence, preserving modality-specific semantics. To maintain spatial alignment while enhancing discrimination among different condition types, we introduce hybrid positional encodings that fuse Rotary Position Embedding with Learnable Positional Embedding. We design Conditional Context-aware Attention to reduces computational complexity while preserving effective intra-condition perception. Without any fine-tuning, ContextAR supports arbitrary combinations of conditions during inference time. Experimental results demonstrate the powerful controllability and versatility of our approach, and show that the competitive perpormance than diffusion-based multi-conditional control approaches the existing autoregressive baseline across diverse multi-condition driven scenarios. Project page: $\href{https://context-ar.github.io/}{https://context-ar.github.io/.}$
Performance Analysis of Deep Learning Models for Femur Segmentation in MRI Scan
Apr 05, 2025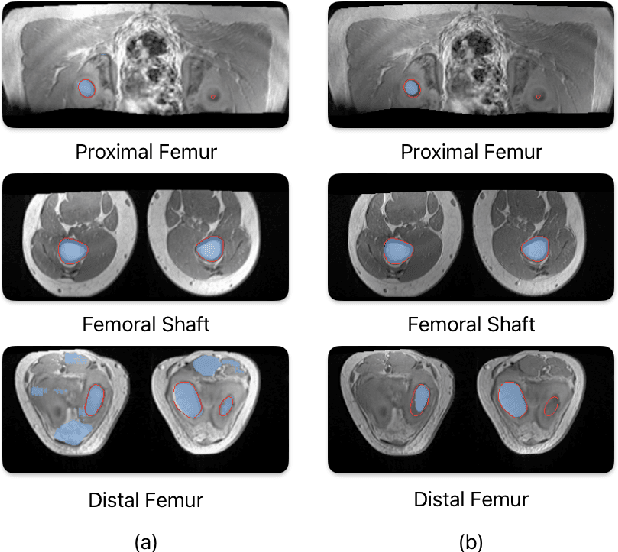
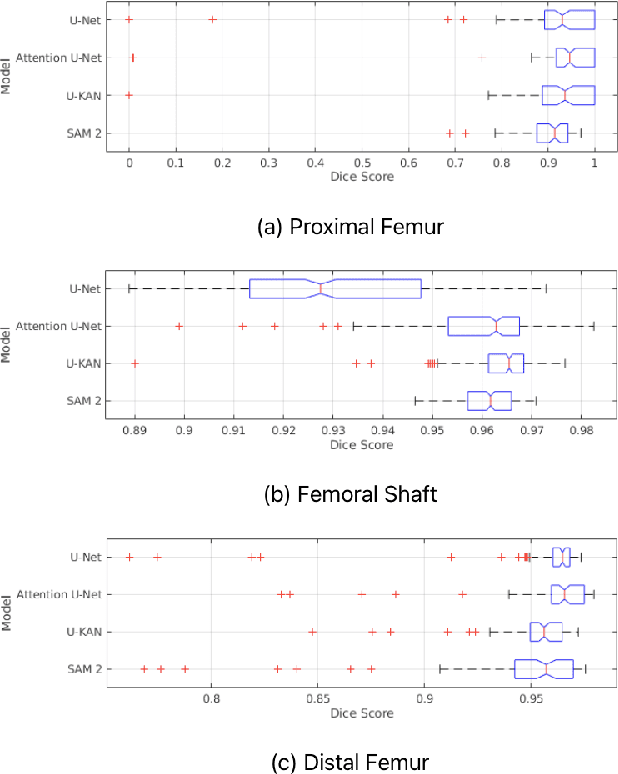
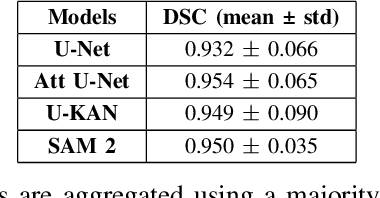
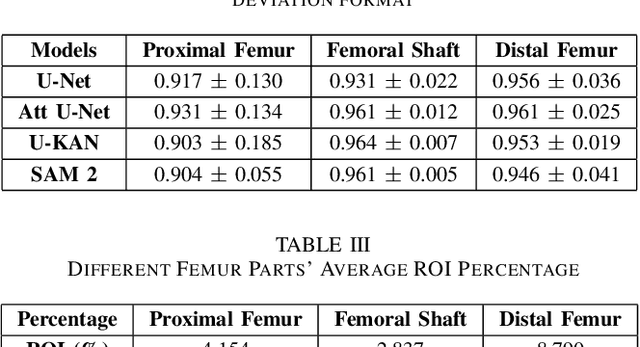
Convolutional neural networks like U-Net excel in medical image segmentation, while attention mechanisms and KAN enhance feature extraction. Meta's SAM 2 uses Vision Transformers for prompt-based segmentation without fine-tuning. However, biases in these models impact generalization with limited data. In this study, we systematically evaluate and compare the performance of three CNN-based models, i.e., U-Net, Attention U-Net, and U-KAN, and one transformer-based model, i.e., SAM 2 for segmenting femur bone structures in MRI scan. The dataset comprises 11,164 MRI scans with detailed annotations of femoral regions. Performance is assessed using the Dice Similarity Coefficient, which ranges from 0.932 to 0.954. Attention U-Net achieves the highest overall scores, while U-KAN demonstrated superior performance in anatomical regions with a smaller region of interest, leveraging its enhanced learning capacity to improve segmentation accuracy.
STGA: Selective-Training Gaussian Head Avatars
Mar 07, 2025We propose selective-training Gaussian head avatars (STGA) to enhance the details of dynamic head Gaussian. The dynamic head Gaussian model is trained based on the FLAME parameterized model. Each Gaussian splat is embedded within the FLAME mesh to achieve mesh-based animation of the Gaussian model. Before training, our selection strategy calculates the 3D Gaussian splat to be optimized in each frame. The parameters of these 3D Gaussian splats are optimized in the training of each frame, while those of the other splats are frozen. This means that the splats participating in the optimization process differ in each frame, to improve the realism of fine details. Compared with network-based methods, our method achieves better results with shorter training time. Compared with mesh-based methods, our method produces more realistic details within the same training time. Additionally, the ablation experiment confirms that our method effectively enhances the quality of details.
RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers
Feb 21, 2025



Recent advancements in video generation have enabled models to synthesize high-quality, minute-long videos. However, generating even longer videos with temporal coherence remains a major challenge, and existing length extrapolation methods lead to temporal repetition or motion deceleration. In this work, we systematically analyze the role of frequency components in positional embeddings and identify an intrinsic frequency that primarily governs extrapolation behavior. Based on this insight, we propose RIFLEx, a minimal yet effective approach that reduces the intrinsic frequency to suppress repetition while preserving motion consistency, without requiring any additional modifications. RIFLEx offers a true free lunch--achieving high-quality $2\times$ extrapolation on state-of-the-art video diffusion transformers in a completely training-free manner. Moreover, it enhances quality and enables $3\times$ extrapolation by minimal fine-tuning without long videos. Project page and codes: \href{https://riflex-video.github.io/}{https://riflex-video.github.io/.}
Dual-Flow: Transferable Multi-Target, Instance-Agnostic Attacks via In-the-wild Cascading Flow Optimization
Feb 05, 2025



Adversarial attacks are widely used to evaluate model robustness, and in black-box scenarios, the transferability of these attacks becomes crucial. Existing generator-based attacks have excellent generalization and transferability due to their instance-agnostic nature. However, when training generators for multi-target tasks, the success rate of transfer attacks is relatively low due to the limitations of the model's capacity. To address these challenges, we propose a novel Dual-Flow framework for multi-target instance-agnostic adversarial attacks, utilizing Cascading Distribution Shift Training to develop an adversarial velocity function. Extensive experiments demonstrate that Dual-Flow significantly improves transferability over previous multi-target generative attacks. For example, it increases the success rate from Inception-v3 to ResNet-152 by 34.58%. Furthermore, our attack method shows substantially stronger robustness against defense mechanisms, such as adversarially trained models.
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing
Feb 04, 2025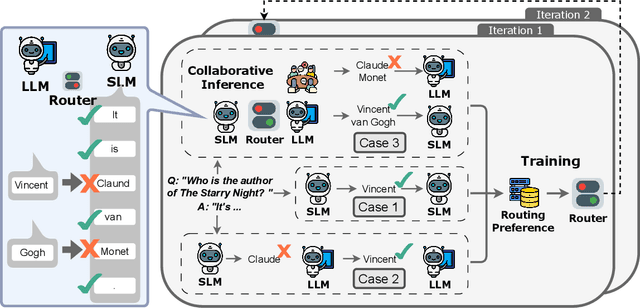
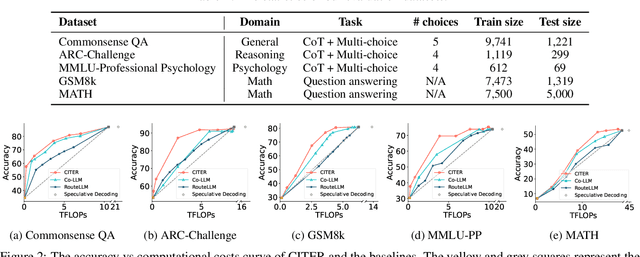
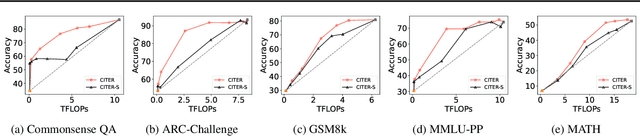
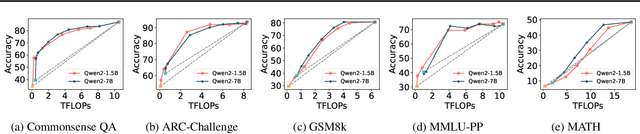
Large language models have achieved remarkable success in various tasks but suffer from high computational costs during inference, limiting their deployment in resource-constrained applications. To address this issue, we propose a novel CITER (\textbf{C}ollaborative \textbf{I}nference with \textbf{T}oken-l\textbf{E}vel \textbf{R}outing) framework that enables efficient collaboration between small and large language models (SLMs & LLMs) through a token-level routing strategy. Specifically, CITER routes non-critical tokens to an SLM for efficiency and routes critical tokens to an LLM for generalization quality. We formulate router training as a policy optimization, where the router receives rewards based on both the quality of predictions and the inference costs of generation. This allows the router to learn to predict token-level routing scores and make routing decisions based on both the current token and the future impact of its decisions. To further accelerate the reward evaluation process, we introduce a shortcut which significantly reduces the costs of the reward estimation and improving the practicality of our approach. Extensive experiments on five benchmark datasets demonstrate that CITER reduces the inference costs while preserving high-quality generation, offering a promising solution for real-time and resource-constrained applications.