 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlacidDreamer: Advancing Harmony in Text-to-3D Generation
Jul 19, 2024Recently, text-to-3D generation has attracted significant attention, resulting in notable performance enhancements. Previous methods utilize end-to-end 3D generation models to initialize 3D Gaussians, multi-view diffusion models to enforce multi-view consistency, and text-to-image diffusion models to refine details with score distillation algorithms. However, these methods exhibit two limitations. Firstly, they encounter conflicts in generation directions since different models aim to produce diverse 3D assets. Secondly, the issue of over-saturation in score distillation has not been thoroughly investigated and solved. To address these limitations, we propose PlacidDreamer, a text-to-3D framework that harmonizes initialization, multi-view generation, and text-conditioned generation with a single multi-view diffusion model, while simultaneously employing a novel score distillation algorithm to achieve balanced saturation. To unify the generation direction, we introduce the Latent-Plane module, a training-friendly plug-in extension that enables multi-view diffusion models to provide fast geometry reconstruction for initialization and enhanced multi-view images to personalize the text-to-image diffusion model. To address the over-saturation problem, we propose to view score distillation as a multi-objective optimization problem and introduce the Balanced Score Distillation algorithm, which offers a Pareto Optimal solution that achieves both rich details and balanced saturation. Extensive experiments validate the outstanding capabilities of our PlacidDreamer. The code is available at \url{https://github.com/HansenHuang0823/PlacidDreamer}.
MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image
Dec 06, 2021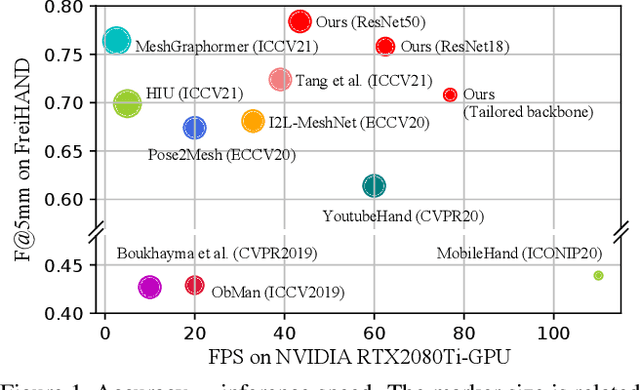
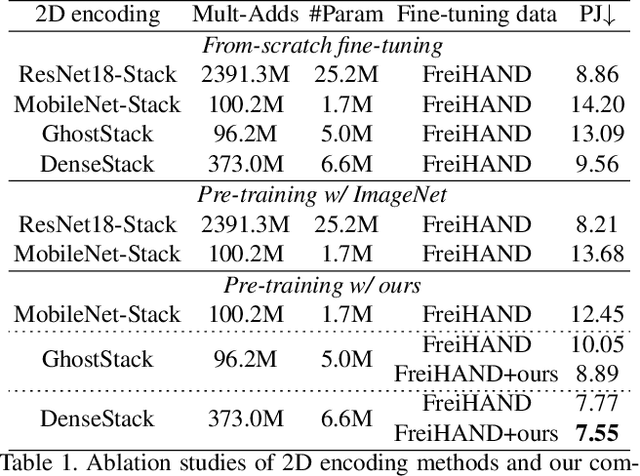


In this work, we propose a framework for single-view hand mesh reconstruction, which can simultaneously achieve high reconstruction accuracy, fast inference speed, and temporal coherence. Specifically, for 2D encoding, we propose lightweight yet effective stacked structures. Regarding 3D decoding, we provide an efficient graph operator, namely depth-separable spiral convolution. Moreover, we present a novel feature lifting module for bridging the gap between 2D and 3D representations. This module starts with a map-based position regression (MapReg) block to integrate the merits of both heatmap encoding and position regression paradigms to improve 2D accuracy and temporal coherence. Furthermore, MapReg is followed by pose pooling and pose-to-vertex lifting approaches, which transform 2D pose encodings to semantic features of 3D vertices. Overall, our hand reconstruction framework, called MobRecon, comprises affordable computational costs and miniature model size, which reaches a high inference speed of 83FPS on Apple A14 CPU. Extensive experiments on popular datasets such as FreiHAND, RHD, and HO3Dv2 demonstrate that our MobRecon achieves superior performance on reconstruction accuracy and temporal coherence. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.