 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVEN: A Massive General Domain Event Detection Dataset
Apr 28, 2020
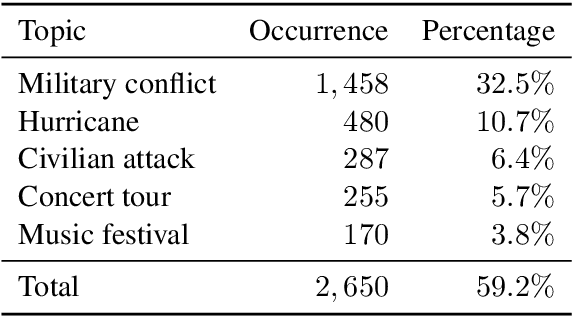
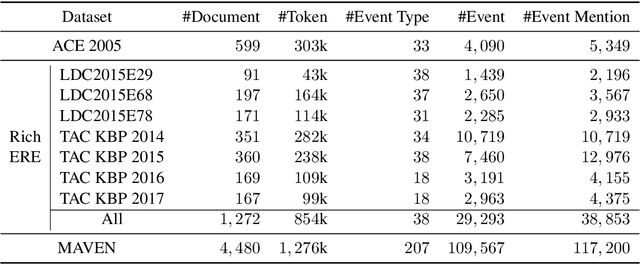
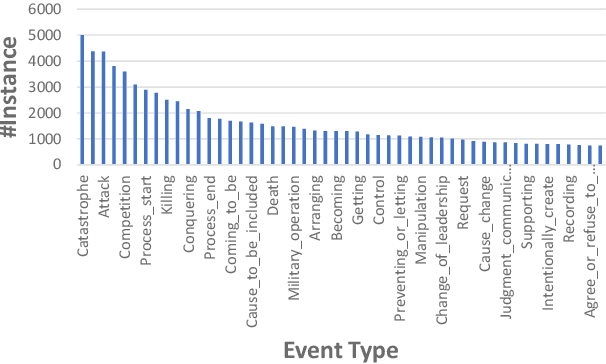
Event detection (ED), which identifies event trigger words and classifies event types according to contexts, is the first and most fundamental step for extracting event knowledge from plain text. Most existing datasets exhibit the following issues that limit further development of ED: (1) Small scale of existing datasets is not sufficient for training and stably benchmarking increasingly sophisticated modern neural methods. (2) Limited event types of existing datasets lead to the trained models cannot be easily adapted to general-domain scenarios. To alleviate these problems, we present a MAssive eVENt detection dataset (MAVEN), which contains 4,480 Wikipedia documents, 117,200 event mention instances, and 207 event types. MAVEN alleviates the lack of data problem and covers much more general event types. Besides the dataset, we reproduce the recent state-of-the-art ED models and conduct a thorough evaluation for these models on MAVEN. The experimental results and empirical analyses show that existing ED methods cannot achieve promising results as on the small datasets, which suggests ED in real world remains a challenging task and requires further research efforts. The dataset and baseline code will be released in the future to promote this field.