 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEBULA: Neural Empirical Bayes Under Latent Representations for Efficient and Controllable Design of Molecular Libraries
Jul 03, 2024We present NEBULA, the first latent 3D generative model for scalable generation of large molecular libraries around a seed compound of interest. Such libraries are crucial for scientific discovery, but it remains challenging to generate large numbers of high quality samples efficiently. 3D-voxel-based methods have recently shown great promise for generating high quality samples de novo from random noise (Pinheiro et al., 2023). However, sampling in 3D-voxel space is computationally expensive and use in library generation is prohibitively slow. Here, we instead perform neural empirical Bayes sampling (Saremi & Hyvarinen, 2019) in the learned latent space of a vector-quantized variational autoencoder. NEBULA generates large molecular libraries nearly an order of magnitude faster than existing methods without sacrificing sample quality. Moreover, NEBULA generalizes better to unseen drug-like molecules, as demonstrated on two public datasets and multiple recently released drugs. We expect the approach herein to be highly enabling for machine learning-based drug discovery. The code is available at https://github.com/prescient-design/nebula
Where in the World is this Image? Transformer-based Geo-localization in the Wild
Apr 29, 2022
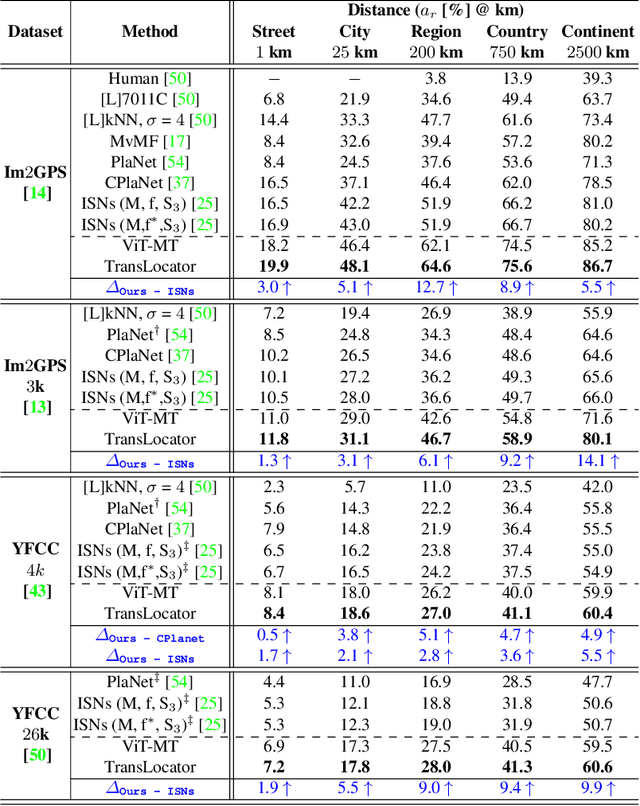
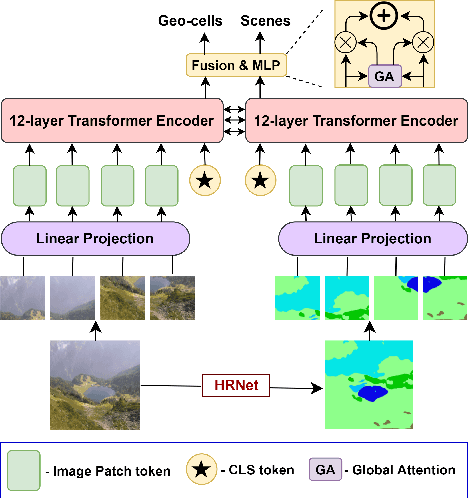
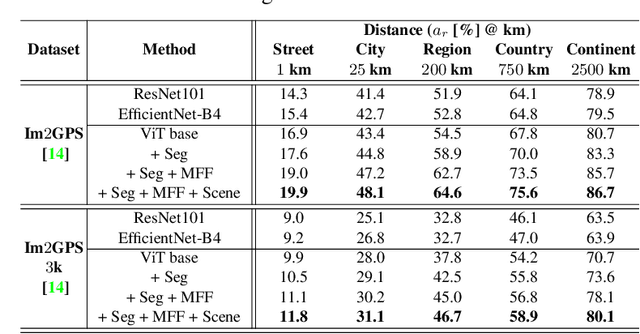
Predicting the geographic location (geo-localization) from a single ground-level RGB image taken anywhere in the world is a very challenging problem. The challenges include huge diversity of images due to different environmental scenarios, drastic variation in the appearance of the same location depending on the time of the day, weather, season, and more importantly, the prediction is made from a single image possibly having only a few geo-locating cues. For these reasons, most existing works are restricted to specific cities, imagery, or worldwide landmarks. In this work, we focus on developing an efficient solution to planet-scale single-image geo-localization. To this end, we propose TransLocator, a unified dual-branch transformer network that attends to tiny details over the entire image and produces robust feature representation under extreme appearance variations. TransLocator takes an RGB image and its semantic segmentation map as inputs, interacts between its two parallel branches after each transformer layer, and simultaneously performs geo-localization and scene recognition in a multi-task fashion. We evaluate TransLocator on four benchmark datasets - Im2GPS, Im2GPS3k, YFCC4k, YFCC26k and obtain 5.5%, 14.1%, 4.9%, 9.9% continent-level accuracy improvement over the state-of-the-art. TransLocator is also validated on real-world test images and found to be more effective than previous methods.