 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning without Memorizing
Paper and Code
Nov 20, 2018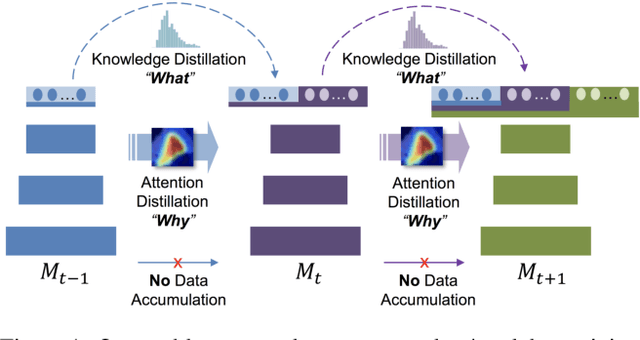


Incremental learning (IL) is an important task aimed to increase the capability of a trained model, in terms of the number of classes recognizable by the model. The key problem in this task is the requirement of storing data (e.g. images) associated with existing classes, while training the classifier to learn new classes. However, this is impractical as it increases the memory requirement at every incremental step, which makes it impossible to implement IL algorithms on the edge devices with limited memory. Hence, we propose a novel approach, called "Learning without Memorizing (LwM)", to preserve the information with respect to existing (base) classes, without storing any of their data, while making the classifier progressively learn the new classes. In LwM, we present an information preserving penalty: Attention Distillation Loss, and demonstrate that penalizing the changes in classifiers' attention maps helps to retain information of the base classes, as new classes are added. We show that adding Attention Distillation Loss to the distillation loss which is an existing information preserving loss consistently outperforms the state-of-the-art performance in the iILSVRC-small and iCIFAR-100 datasets in terms of the overall accuracy of base and incrementally learned classes.