 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Mamba Reliable for Medical Imaging?
Feb 16, 2026State-space models like Mamba offer linear-time sequence processing and low memory, making them attractive for medical imaging. However, their robustness under realistic software and hardware threat models remains underexplored. This paper evaluates Mamba on multiple MedM-NIST classification benchmarks under input-level attacks, including white-box adversarial perturbations (FGSM/PGD), occlusion-based PatchDrop, and common acquisition corruptions (Gaussian noise and defocus blur) as well as hardware-inspired fault attacks emulated in software via targeted and random bit-flip injections into weights and activations. We profile vulnerabilities and quantify impacts on accuracy indicating that defenses are needed for deployment.
Pay Attention to Where You Look
Jan 26, 2026Novel view synthesis (NVS) has advanced with generative modeling, enabling photorealistic image generation. In few-shot NVS, where only a few input views are available, existing methods often assume equal importance for all input views relative to the target, leading to suboptimal results. We address this limitation by introducing a camera-weighting mechanism that adjusts the importance of source views based on their relevance to the target. We propose two approaches: a deterministic weighting scheme leveraging geometric properties like Euclidean distance and angular differences, and a cross-attention-based learning scheme that optimizes view weighting. Additionally, models can be further trained with our camera-weighting scheme to refine their understanding of view relevance and enhance synthesis quality. This mechanism is adaptable and can be integrated into various NVS algorithms, improving their ability to synthesize high-quality novel views. Our results demonstrate that adaptive view weighting enhances accuracy and realism, offering a promising direction for improving NVS.
* ICIP 2025 Workshop on Generative AI for World Simulations and Communications
Cascading Unknown Detection with Known Classification for Open Set Recognition
Jun 10, 2024Deep learners tend to perform well when trained under the closed set assumption but struggle when deployed under open set conditions. This motivates the field of Open Set Recognition in which we seek to give deep learners the ability to recognize whether a data sample belongs to the known classes trained on or comes from the surrounding infinite world. Existing open set recognition methods typically rely upon a single function for the dual task of distinguishing between knowns and unknowns as well as making known class distinction. This dual process leaves performance on the table as the function is not specialized for either task. In this work, we introduce Cascading Unknown Detection with Known Classification (Cas-DC), where we instead learn specialized functions in a cascading fashion for both known/unknown detection and fine class classification amongst the world of knowns. Our experiments and analysis demonstrate that Cas-DC handily outperforms modern methods in open set recognition when compared using AUROC scores and correct classification rate at various true positive rates.
Adapting Classifiers To Changing Class Priors During Deployment
Sep 04, 2023



Conventional classifiers are trained and evaluated using balanced data sets in which all classes are equally present. Classifiers are now trained on large data sets such as ImageNet, and are now able to classify hundreds (if not thousands) of different classes. On one hand, it is desirable to train such general-purpose classifier on a very large number of classes so that it performs well regardless of the settings in which it is deployed. On the other hand, it is unlikely that all classes known to the classifier will occur in every deployment scenario, or that they will occur with the same prior probability. In reality, only a relatively small subset of the known classes may be present in a particular setting or environment. For example, a classifier will encounter mostly animals if its deployed in a zoo or for monitoring wildlife, aircraft and service vehicles at an airport, or various types of automobiles and commercial vehicles if it is used for monitoring traffic. Furthermore, the exact class priors are generally unknown and can vary over time. In this paper, we explore different methods for estimating the class priors based on the output of the classifier itself. We then show that incorporating the estimated class priors in the overall decision scheme enables the classifier to increase its run-time accuracy in the context of its deployment scenario.
Improving Replay Sample Selection and Storage for Less Forgetting in Continual Learning
Aug 03, 2023



Continual learning seeks to enable deep learners to train on a series of tasks of unknown length without suffering from the catastrophic forgetting of previous tasks. One effective solution is replay, which involves storing few previous experiences in memory and replaying them when learning the current task. However, there is still room for improvement when it comes to selecting the most informative samples for storage and determining the optimal number of samples to be stored. This study aims to address these issues with a novel comparison of the commonly used reservoir sampling to various alternative population strategies and providing a novel detailed analysis of how to find the optimal number of stored samples.
Background Invariant Classification on Infrared Imagery by Data Efficient Training and Reducing Bias in CNNs
Feb 09, 2022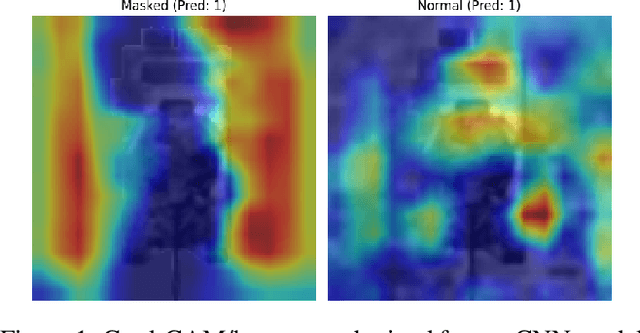

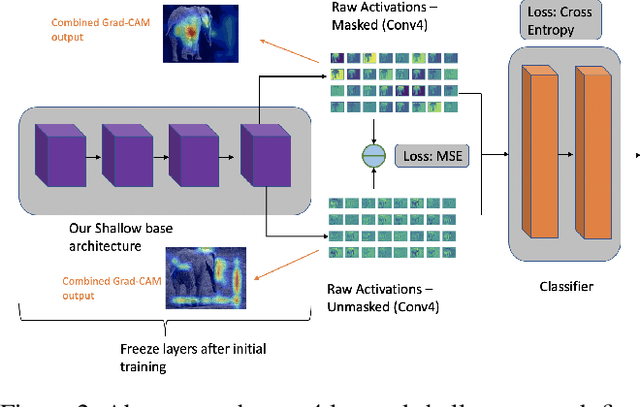

Even though convolutional neural networks can classify objects in images very accurately, it is well known that the attention of the network may not always be on the semantically important regions of the scene. It has been observed that networks often learn background textures which are not relevant to the object of interest. In turn this makes the networks susceptible to variations and changes in the background which negatively affect their performance. We propose a new two-step training procedure called split training to reduce this bias in CNNs on both Infrared imagery and RGB data. Our split training procedure has two steps: using MSE loss first train the layers of the network on images with background to match the activations of the same network when it is trained using images without background; then with these layers frozen, train the rest of the network with cross-entropy loss to classify the objects. Our training method outperforms the traditional training procedure in both a simple CNN architecture, and deep CNNs like VGG and Densenet which use lots of hardware resources, and learns to mimic human vision which focuses more on shape and structure than background with higher accuracy.
Compressing Deep CNNs using Basis Representation and Spectral Fine-tuning
May 21, 2021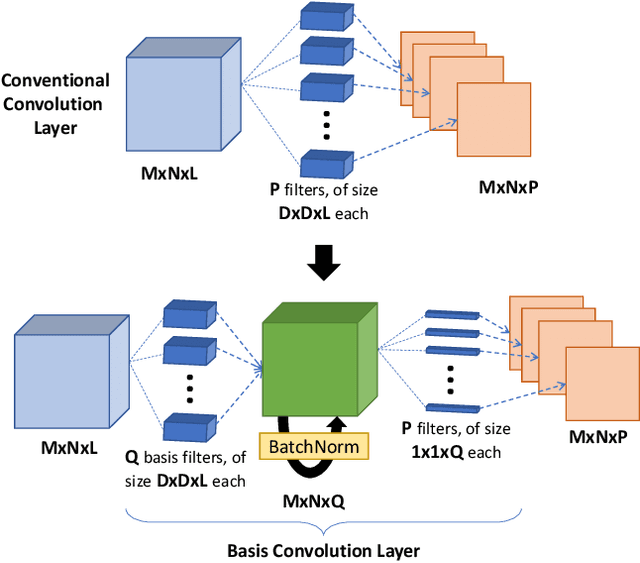
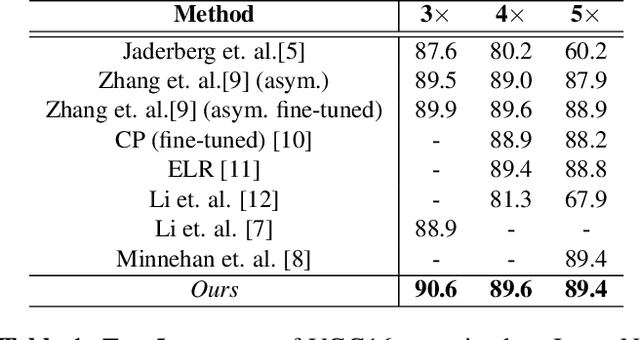
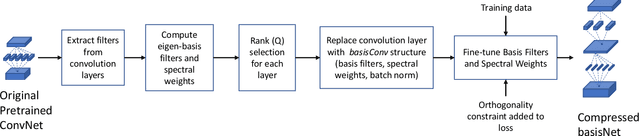

We propose an efficient and straightforward method for compressing deep convolutional neural networks (CNNs) that uses basis filters to represent the convolutional layers, and optimizes the performance of the compressed network directly in the basis space. Specifically, any spatial convolution layer of the CNN can be replaced by two successive convolution layers: the first is a set of three-dimensional orthonormal basis filters, followed by a layer of one-dimensional filters that represents the original spatial filters in the basis space. We jointly fine-tune both the basis and the filter representation to directly mitigate any performance loss due to the truncation. Generality of the proposed approach is demonstrated by applying it to several well known deep CNN architectures and data sets for image classification and object detection. We also present the execution time and power usage at different compression levels on the Xavier Jetson AGX processor.
Multiple View Generation and Classification of Mid-wave Infrared Images using Deep Learning
Aug 18, 2020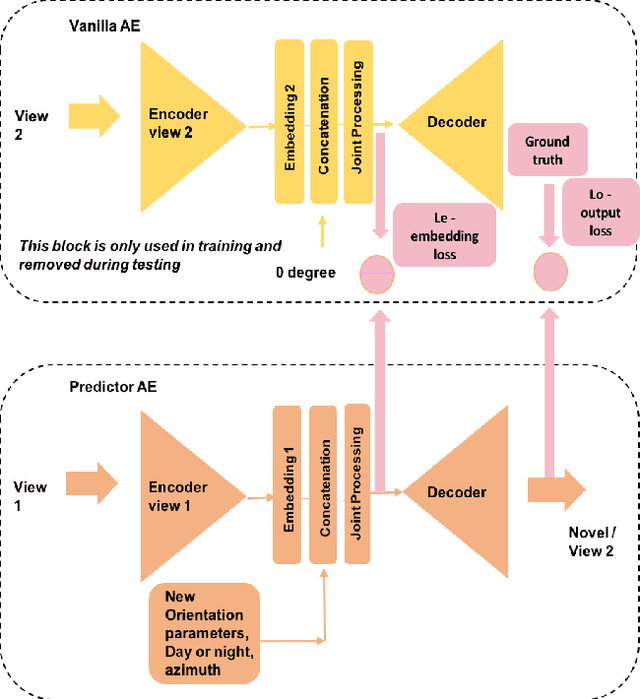
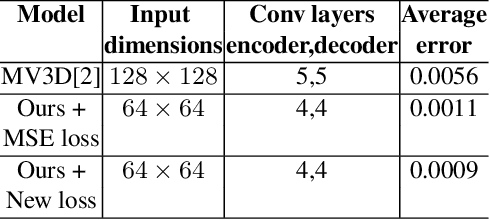
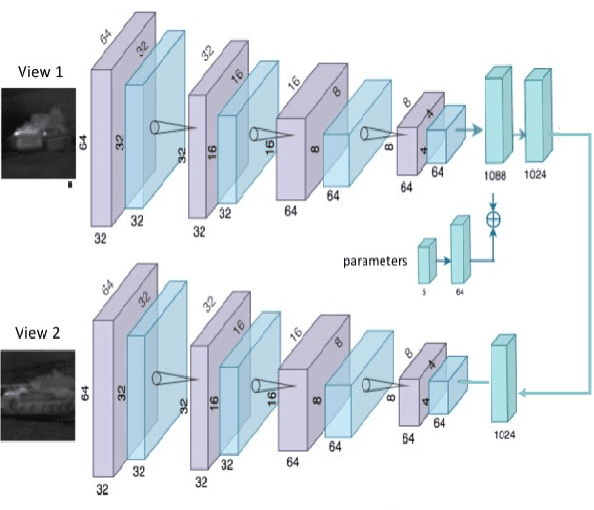

We propose a novel study of generating unseen arbitrary viewpoints for infrared imagery in the non-linear feature subspace . Current methods use synthetic images and often result in blurry and distorted outputs. Our approach on the contrary understands the semantic information in natural images and encapsulates it such that our predicted unseen views possess good 3D representations. We further explore the non-linear feature subspace and conclude that our network does not operate in the Euclidean subspace but rather in the Riemannian subspace. It does not learn the geometric transformation for predicting the position of the pixel in the new image but rather learns the manifold. To this end, we use t-SNE visualisations to conduct a detailed analysis of our network and perform classification of generated images as a low-shot learning task.
Attention Guided Anomaly Detection and Localization in Images
Nov 19, 2019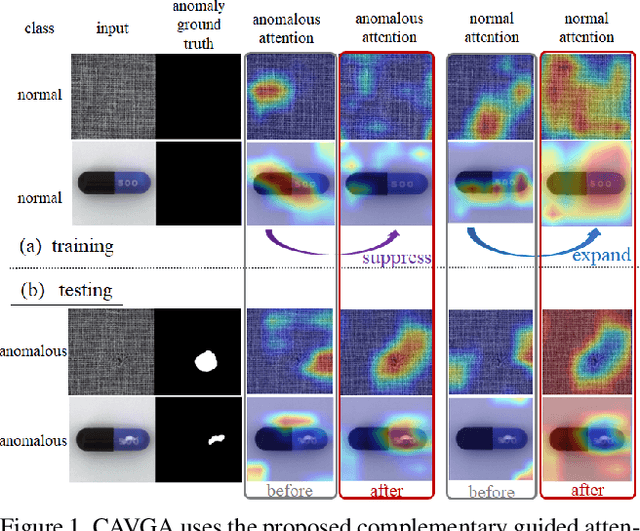

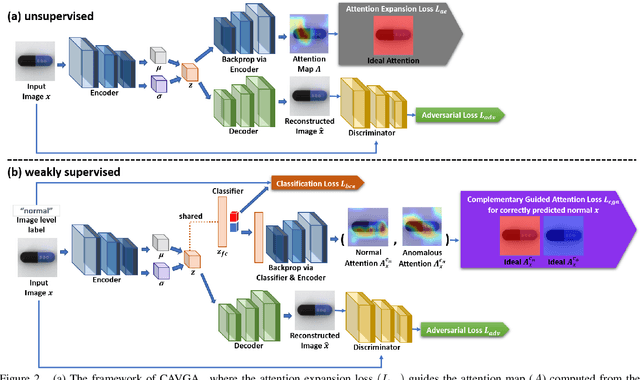
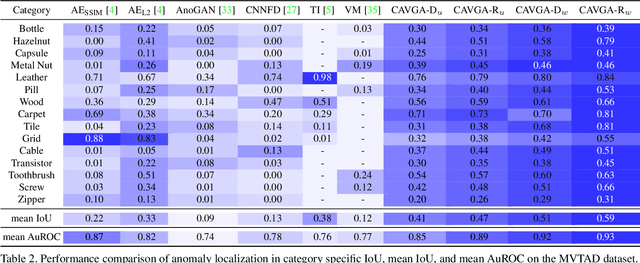
Anomaly detection and localization is a popular computer vision problem involving detecting anomalous images and localizing anomalies within them. However, this task is challenging due to the small sample size and pixel coverage of the anomaly in real-world scenarios. Prior works need to use anomalous training images to compute a threshold to detect and localize anomalies. To remove this need, we propose Convolutional Adversarial Variational autoencoder with Guided Attention (CAVGA), which localizes the anomaly with a convolutional latent variable to preserve the spatial information. In the unsupervised setting, we propose an attention expansion loss, where we encourage CAVGA to focus on all normal regions in the image without using any anomalous training image. Furthermore, using only 2% anomalous images in the weakly supervised setting we propose a complementary guided attention loss, where we encourage the normal attention to focus on all normal regions while minimizing the regions covered by the anomalous attention in the normal image. CAVGA outperforms the state-of-the-art (SOTA) anomaly detection methods on the MNIST, CIFAR-10, Fashion-MNIST, MVTec Anomaly Detection (MVTAD), and modified ShanghaiTech Campus (mSTC) datasets. CAVGA also outperforms the SOTA anomaly localization methods on the MVTAD and mSTC datasets.
BasisConv: A method for compressed representation and learning in CNNs
Jun 11, 2019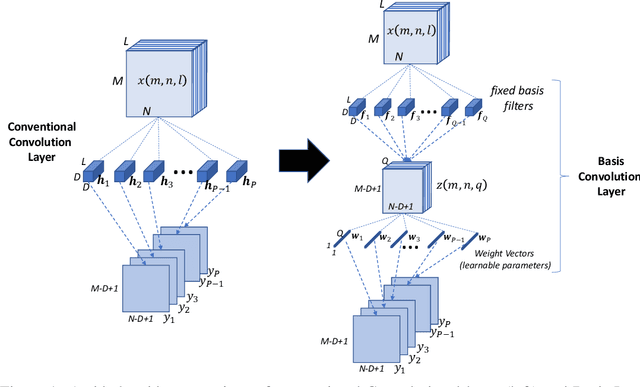
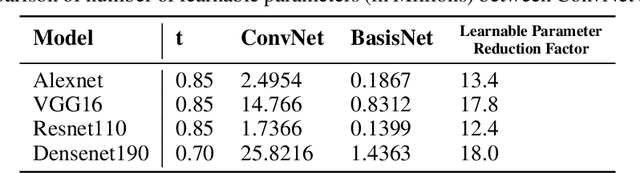
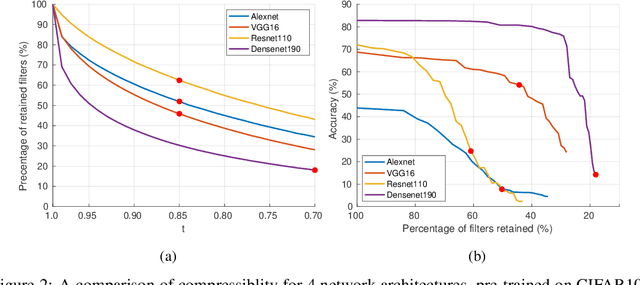
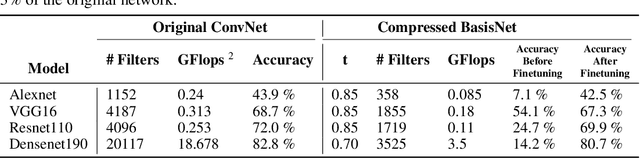
It is well known that Convolutional Neural Networks (CNNs) have significant redundancy in their filter weights. Various methods have been proposed in the literature to compress trained CNNs. These include techniques like pruning weights, filter quantization and representing filters in terms of a basis functions. Our approach falls in this latter class of strategies, but is distinct in that that we show both compressed learning and representation can be achieved without significant modifications of popular CNN architectures. Specifically, any convolution layer of the CNN is easily replaced by two successive convolution layers: the first is a set of fixed filters (that represent the knowledge space of the entire layer and do not change), which is followed by a layer of one-dimensional filters (that represent the learned knowledge in this space). For the pre-trained networks, the fixed layer is just the truncated eigen-decompositions of the original filters. The 1D filters are initialized as the weights of linear combination, but are fine-tuned to recover any performance loss due to the truncation. For training networks from scratch, we use a set of random orthogonal fixed filters (that never change), and learn the 1D weight vector directly from the labeled data. Our method substantially reduces i) the number of learnable parameters during training, and ii) the number of multiplication operations and filter storage requirements during implementation. It does so without requiring any special operators in the convolution layer, and extends to all known popular CNN architectures. We apply our method to four well known network architectures trained with three different data sets. Results show a consistent reduction in i) the number of operations by up to a factor of 5, and ii) number of learnable parameters by up to a factor of 18, with less than 3% drop in performance on the CIFAR100 dataset.