 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Classifiers To Changing Class Priors During Deployment
Sep 04, 2023



Conventional classifiers are trained and evaluated using balanced data sets in which all classes are equally present. Classifiers are now trained on large data sets such as ImageNet, and are now able to classify hundreds (if not thousands) of different classes. On one hand, it is desirable to train such general-purpose classifier on a very large number of classes so that it performs well regardless of the settings in which it is deployed. On the other hand, it is unlikely that all classes known to the classifier will occur in every deployment scenario, or that they will occur with the same prior probability. In reality, only a relatively small subset of the known classes may be present in a particular setting or environment. For example, a classifier will encounter mostly animals if its deployed in a zoo or for monitoring wildlife, aircraft and service vehicles at an airport, or various types of automobiles and commercial vehicles if it is used for monitoring traffic. Furthermore, the exact class priors are generally unknown and can vary over time. In this paper, we explore different methods for estimating the class priors based on the output of the classifier itself. We then show that incorporating the estimated class priors in the overall decision scheme enables the classifier to increase its run-time accuracy in the context of its deployment scenario.
Multi-modal Capsule Routing for Actor and Action Video Segmentation Conditioned on Natural Language Queries
Dec 02, 2018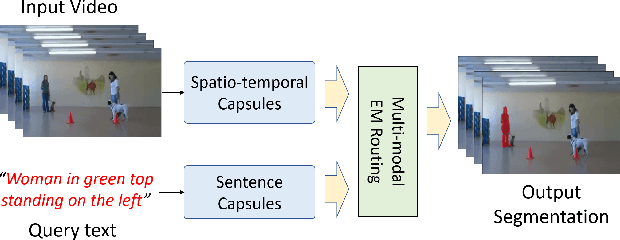
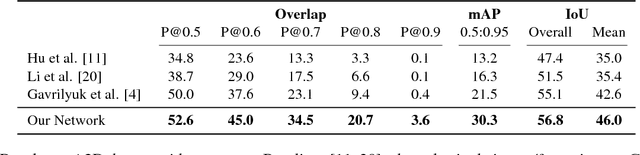
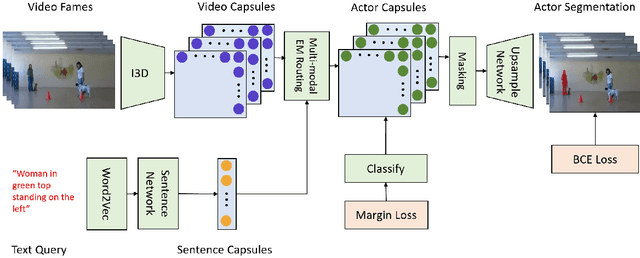

In this paper, we propose an end-to-end capsule network for pixel level localization of actors and actions present in a video. The localization is performed based on a natural language query through which an actor and action are specified. We propose to encode both the video as well as textual input in the form of capsules, which provide more effective representation in comparison with standard convolution based features. We introduce a novel capsule based attention mechanism for fusion of video and text capsules for text selected video segmentation. The attention mechanism is performed via joint EM routing over video and text capsules for text selected actor and action localization. The existing works on actor-action localization are mainly focused on localization in a single frame instead of the full video. Different from existing works, we propose to perform the localization on all frames of the video. To validate the potential of the proposed network for actor and action localization on all the frames of a video, we extend an existing actor-action dataset (A2D) with annotations for all the frames. The experimental evaluation demonstrates the effectiveness of the proposed capsule network for text selective actor and action localization in videos, and it also improves upon the performance of the existing state-of-the art works on single frame-based localization.