 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Works for 'Lost-in-the-Middle' in LLMs? A Study on GM-Extract and Mitigations
Nov 17, 2025



The diminishing ability of large language models (LLMs) to effectively utilize long-range context-the "lost-in-the-middle" phenomenon-poses a significant challenge in retrieval-based LLM applications. To study the impact of this phenomenon in a real-world application setting, we introduce GM-Extract, a novel benchmark dataset meticulously designed to evaluate LLM performance on retrieval of control variables. To accurately diagnose failure modes, we propose a simple yet elegant evaluation system using two distinct metrics: one for spatial retrieval capability (Document Metric) and the other for semantic retrieval capability (Variable Extraction Metric). We conduct a systematic evaluation of 7-8B parameter models on two multi-document tasks (key-value extraction and question-answering), demonstrating a significant change in retrieval performance simply by altering how the data is represented in the context window. While a distinct U-shaped curve was not consistently observed, our analysis reveals a clear pattern of performance across models, which we further correlate with perplexity scores. Furthermore, we perform a literature survey of mitigation methods, which we categorize into two distinct approaches: black-box and white-box methods. We then apply these techniques to our benchmark, finding that their efficacy is highly nuanced. Our evaluation highlights scenarios where these strategies successfully improve performance, as well as surprising cases where they lead to a negative impact, providing a comprehensive understanding of their utility in a practical context.
Ambient IoT: A missing link in 3GPP IoT Devices Landscape
Dec 11, 2023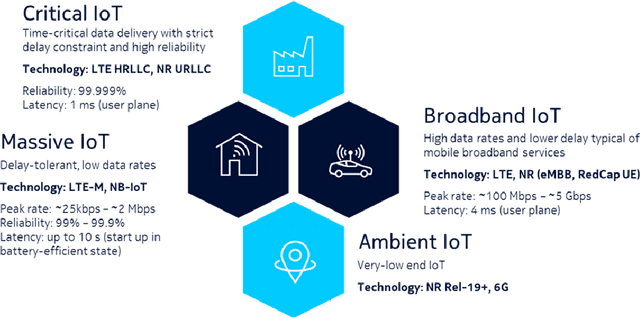
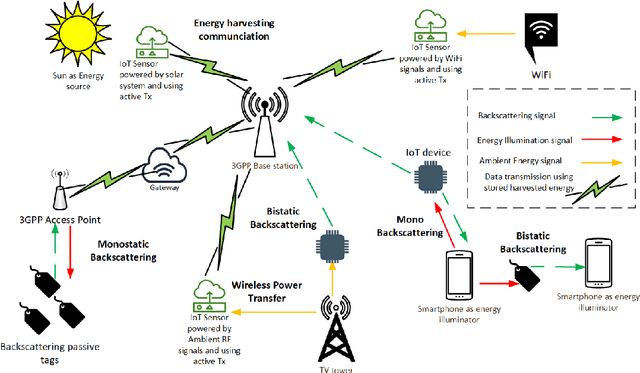
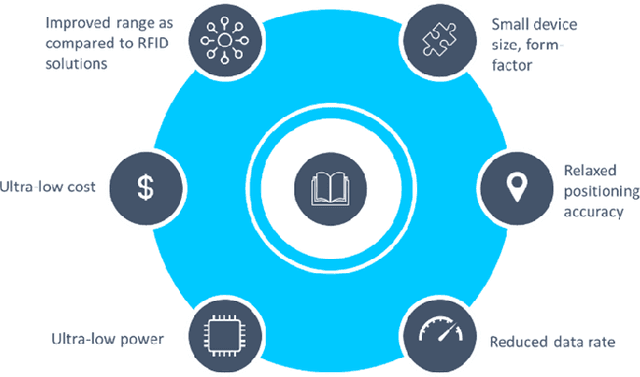
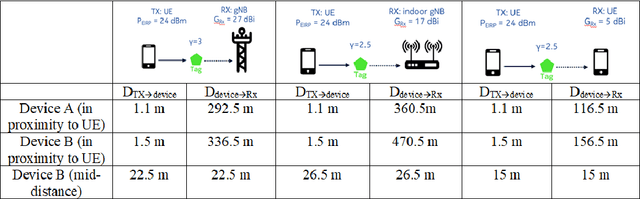
Ambient internet of things (IoT) is the network of devices which harvest energy from ambient sources for powering their communication. After decades of research on operation of these devices, Third Generation Partnership Project (3GPP) has started discussing energy harvesting technology in cellular networks to support massive deployment of IoT devices at low operational cost. This article provides a timely update on 3GPP studies on ambient energy harvesting devices including device types, use cases, key requirements, and related design challenges. Supported by link budget analysis for backscattering energy harvesting devices, which are a key component of this study, we provide insight on system design and show how this technology will require a new system design approach as compared to New Radio (NR) system design in 5G.
Compressing Deep CNNs using Basis Representation and Spectral Fine-tuning
May 21, 2021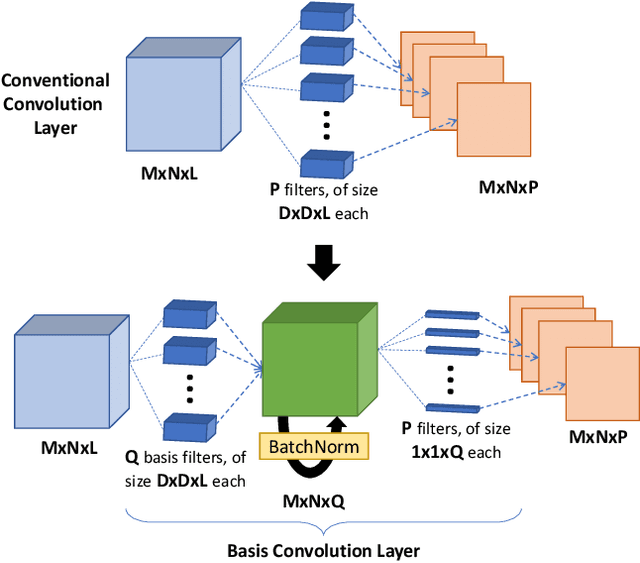
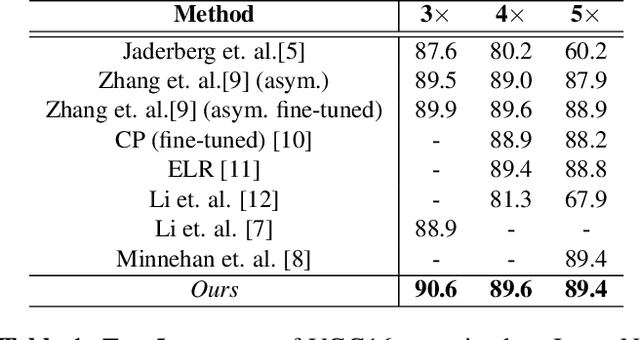
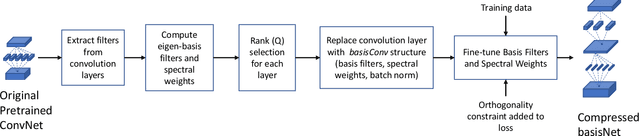

We propose an efficient and straightforward method for compressing deep convolutional neural networks (CNNs) that uses basis filters to represent the convolutional layers, and optimizes the performance of the compressed network directly in the basis space. Specifically, any spatial convolution layer of the CNN can be replaced by two successive convolution layers: the first is a set of three-dimensional orthonormal basis filters, followed by a layer of one-dimensional filters that represents the original spatial filters in the basis space. We jointly fine-tune both the basis and the filter representation to directly mitigate any performance loss due to the truncation. Generality of the proposed approach is demonstrated by applying it to several well known deep CNN architectures and data sets for image classification and object detection. We also present the execution time and power usage at different compression levels on the Xavier Jetson AGX processor.
Biosensors and Machine Learning for Enhanced Detection, Stratification, and Classification of Cells: A Review
Jan 06, 2021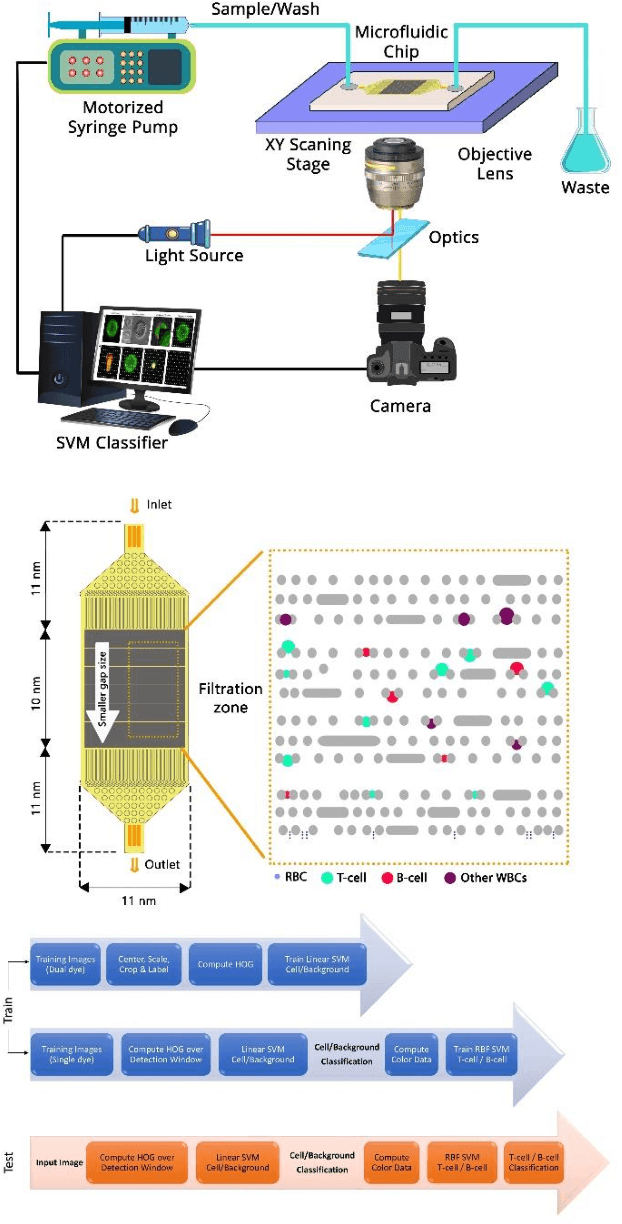
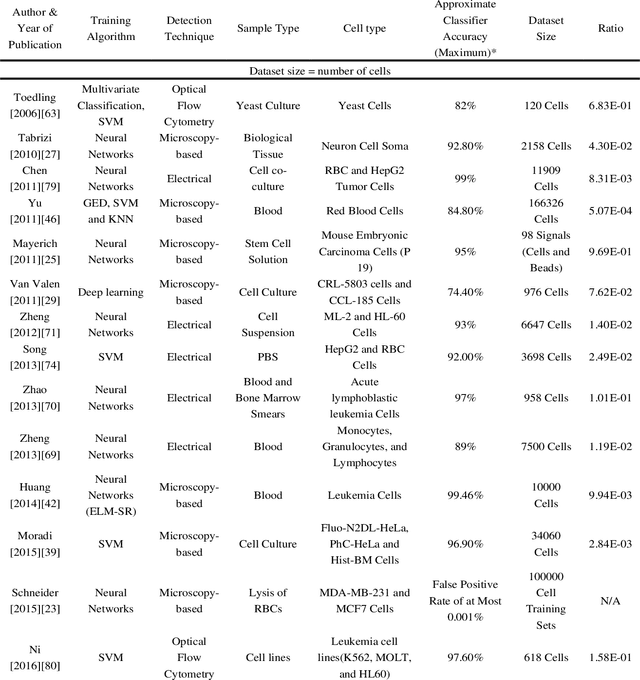
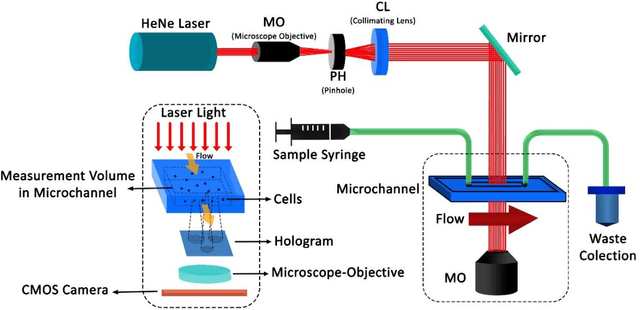
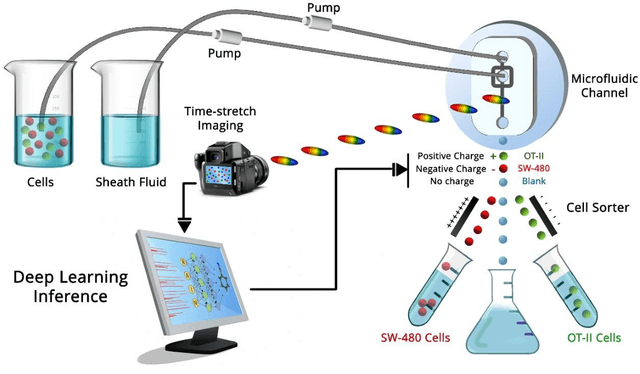
Biological cells, by definition, are the basic units which contain the fundamental molecules of life of which all living things are composed. Understanding how they function and differentiating cells from one another therefore is of paramount importance for disease diagnostics as well as therapeutics. Sensors focusing on the detection and stratification of cells have gained popularity as technological advancements have allowed for the miniaturization of various components inching us closer to Point-of-Care (POC) solutions with each passing day. Furthermore, Machine Learning has allowed for enhancement in analytical capabilities of these various biosensing modalities, especially the challenging task of classification of cells into various categories using a data-driven approach rather than physics-driven. In this review, we provide an account of how Machine Learning has been applied explicitly to sensors that detect and classify cells. We also provide a comparison of how different sensing modalities and algorithms affect the classifier accuracy and the dataset size required.
BasisConv: A method for compressed representation and learning in CNNs
Jun 11, 2019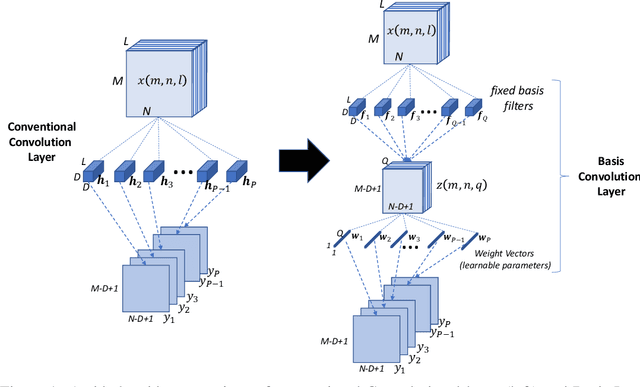
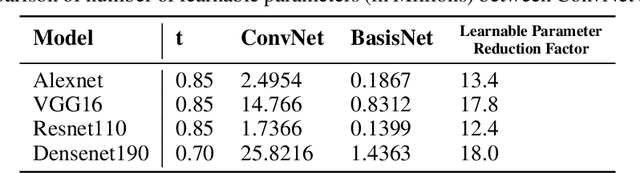
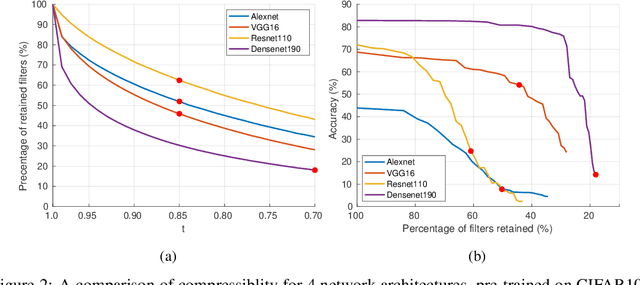
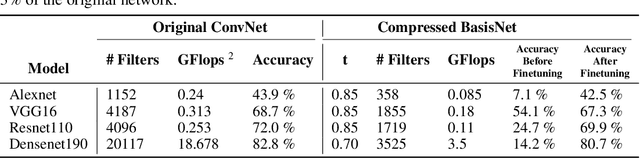
It is well known that Convolutional Neural Networks (CNNs) have significant redundancy in their filter weights. Various methods have been proposed in the literature to compress trained CNNs. These include techniques like pruning weights, filter quantization and representing filters in terms of a basis functions. Our approach falls in this latter class of strategies, but is distinct in that that we show both compressed learning and representation can be achieved without significant modifications of popular CNN architectures. Specifically, any convolution layer of the CNN is easily replaced by two successive convolution layers: the first is a set of fixed filters (that represent the knowledge space of the entire layer and do not change), which is followed by a layer of one-dimensional filters (that represent the learned knowledge in this space). For the pre-trained networks, the fixed layer is just the truncated eigen-decompositions of the original filters. The 1D filters are initialized as the weights of linear combination, but are fine-tuned to recover any performance loss due to the truncation. For training networks from scratch, we use a set of random orthogonal fixed filters (that never change), and learn the 1D weight vector directly from the labeled data. Our method substantially reduces i) the number of learnable parameters during training, and ii) the number of multiplication operations and filter storage requirements during implementation. It does so without requiring any special operators in the convolution layer, and extends to all known popular CNN architectures. We apply our method to four well known network architectures trained with three different data sets. Results show a consistent reduction in i) the number of operations by up to a factor of 5, and ii) number of learnable parameters by up to a factor of 18, with less than 3% drop in performance on the CIFAR100 dataset.
Towards a Crowd Analytic Framework For Crowd Management in Majid-al-Haram
Sep 14, 2017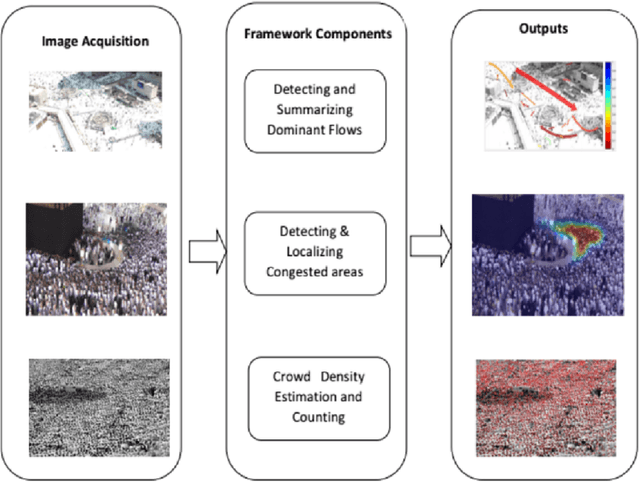


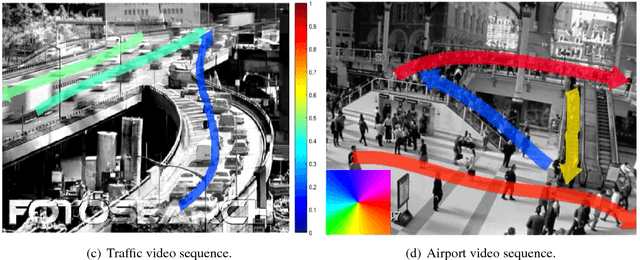
The scared cities of Makkah Al Mukarramah and Madina Al Munawarah host millions of pilgrims every year. During Hajj, the movement of large number of people has a unique spatial and temporal constraints, which makes Hajj one of toughest challenges for crowd management. In this paper, we propose a computer vision based framework that automatically analyses video sequence and computes important measurements which include estimation of crowd density, identification of dominant patterns, detection and localization of congestion. In addition, we analyze helpful statistics of the crowd like speed, and direction, that could provide support to crowd management personnel. The framework presented in this paper indicate that new advances in computer vision and machine learning can be leveraged effectively for challenging and high density crowd management applications. However, significant customization of existing approaches is required to apply them to the challenging crowd management situations in Masjid Al Haram. Our results paint a promising picture for deployment of computer vision technologies to assist in quantitative measurement of crowd size, density and congestion.