 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground Invariant Classification on Infrared Imagery by Data Efficient Training and Reducing Bias in CNNs
Feb 09, 2022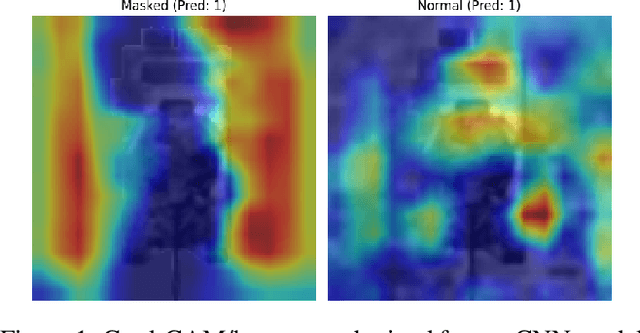

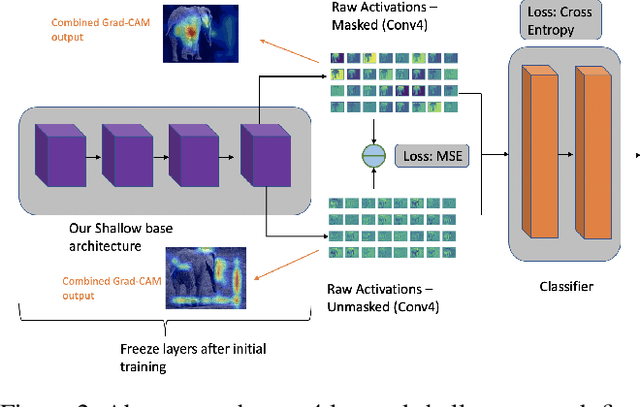

Even though convolutional neural networks can classify objects in images very accurately, it is well known that the attention of the network may not always be on the semantically important regions of the scene. It has been observed that networks often learn background textures which are not relevant to the object of interest. In turn this makes the networks susceptible to variations and changes in the background which negatively affect their performance. We propose a new two-step training procedure called split training to reduce this bias in CNNs on both Infrared imagery and RGB data. Our split training procedure has two steps: using MSE loss first train the layers of the network on images with background to match the activations of the same network when it is trained using images without background; then with these layers frozen, train the rest of the network with cross-entropy loss to classify the objects. Our training method outperforms the traditional training procedure in both a simple CNN architecture, and deep CNNs like VGG and Densenet which use lots of hardware resources, and learns to mimic human vision which focuses more on shape and structure than background with higher accuracy.