 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureV2X: An Efficient and Privacy-Preserving System for Vehicle-to-Everything (V2X) Applications
Aug 26, 2025Autonomous driving and V2X technologies have developed rapidly in the past decade, leading to improved safety and efficiency in modern transportation. These systems interact with extensive networks of vehicles, roadside infrastructure, and cloud resources to support their machine learning capabilities. However, the widespread use of machine learning in V2X systems raises issues over the privacy of the data involved. This is particularly concerning for smart-transit and driver safety applications which can implicitly reveal user locations or explicitly disclose medical data such as EEG signals. To resolve these issues, we propose SecureV2X, a scalable, multi-agent system for secure neural network inferences deployed between the server and each vehicle. Under this setting, we study two multi-agent V2X applications: secure drowsiness detection, and secure red-light violation detection. Our system achieves strong performance relative to baselines, and scales efficiently to support a large number of secure computation interactions simultaneously. For instance, SecureV2X is $9.4 \times$ faster, requires $143\times$ fewer computational rounds, and involves $16.6\times$ less communication on drowsiness detection compared to other secure systems. Moreover, it achieves a runtime nearly $100\times$ faster than state-of-the-art benchmarks in object detection tasks for red light violation detection.
Pragmatic Metacognitive Prompting Improves LLM Performance on Sarcasm Detection
Dec 04, 2024Sarcasm detection is a significant challenge in sentiment analysis due to the nuanced and context-dependent nature of verbiage. We introduce Pragmatic Metacognitive Prompting (PMP) to improve the performance of Large Language Models (LLMs) in sarcasm detection, which leverages principles from pragmatics and reflection helping LLMs interpret implied meanings, consider contextual cues, and reflect on discrepancies to identify sarcasm. Using state-of-the-art LLMs such as LLaMA-3-8B, GPT-4o, and Claude 3.5 Sonnet, PMP achieves state-of-the-art performance on GPT-4o on MUStARD and SemEval2018. This study demonstrates that integrating pragmatic reasoning and metacognitive strategies into prompting significantly enhances LLMs' ability to detect sarcasm, offering a promising direction for future research in sentiment analysis.
RFRL Gym: A Reinforcement Learning Testbed for Cognitive Radio Applications
Dec 20, 2023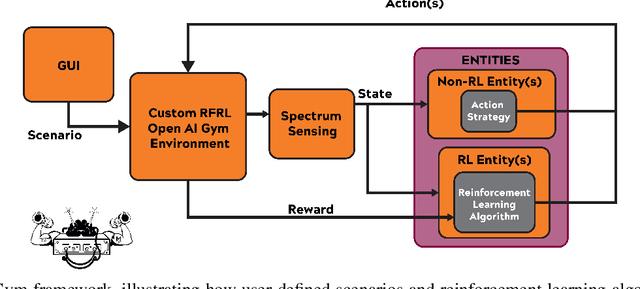
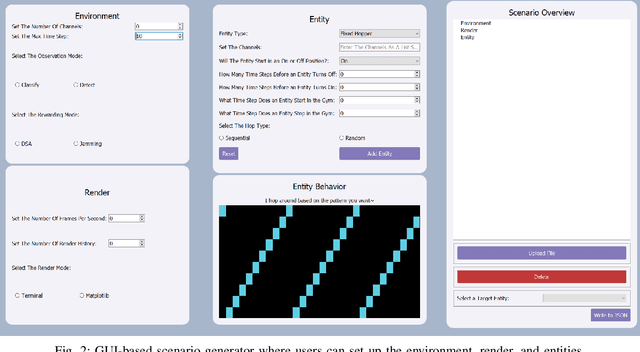
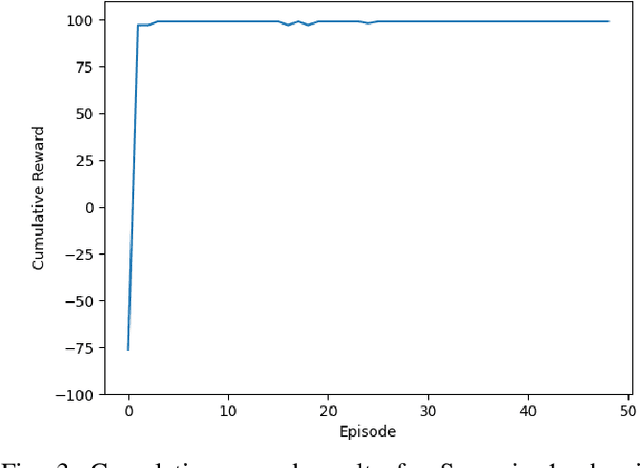
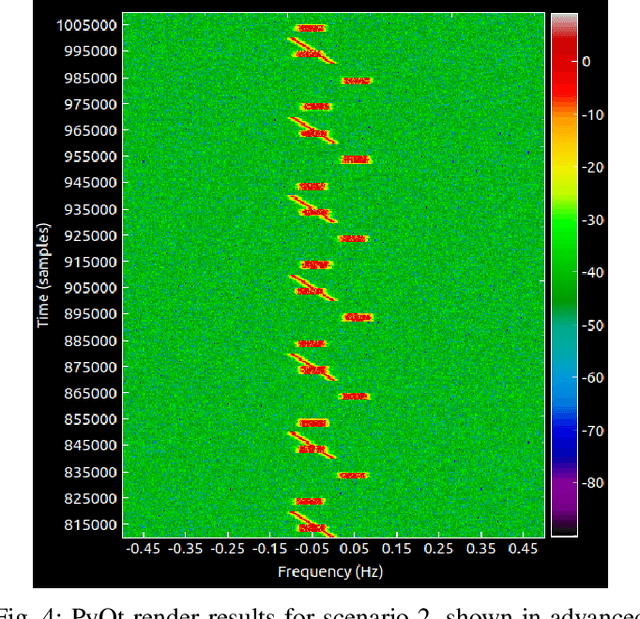
Radio Frequency Reinforcement Learning (RFRL) is anticipated to be a widely applicable technology in the next generation of wireless communication systems, particularly 6G and next-gen military communications. Given this, our research is focused on developing a tool to promote the development of RFRL techniques that leverage spectrum sensing. In particular, the tool was designed to address two cognitive radio applications, specifically dynamic spectrum access and jamming. In order to train and test reinforcement learning (RL) algorithms for these applications, a simulation environment is necessary to simulate the conditions that an agent will encounter within the Radio Frequency (RF) spectrum. In this paper, such an environment has been developed, herein referred to as the RFRL Gym. Through the RFRL Gym, users can design their own scenarios to model what an RL agent may encounter within the RF spectrum as well as experiment with different spectrum sensing techniques. Additionally, the RFRL Gym is a subclass of OpenAI gym, enabling the use of third-party ML/RL Libraries. We plan to open-source this codebase to enable other researchers to utilize the RFRL Gym to test their own scenarios and RL algorithms, ultimately leading to the advancement of RL research in the wireless communications domain. This paper describes in further detail the components of the Gym, results from example scenarios, and plans for future additions. Index Terms-machine learning, reinforcement learning, wireless communications, dynamic spectrum access, OpenAI gym
A Maximal Correlation Approach to Imposing Fairness in Machine Learning
Dec 30, 2020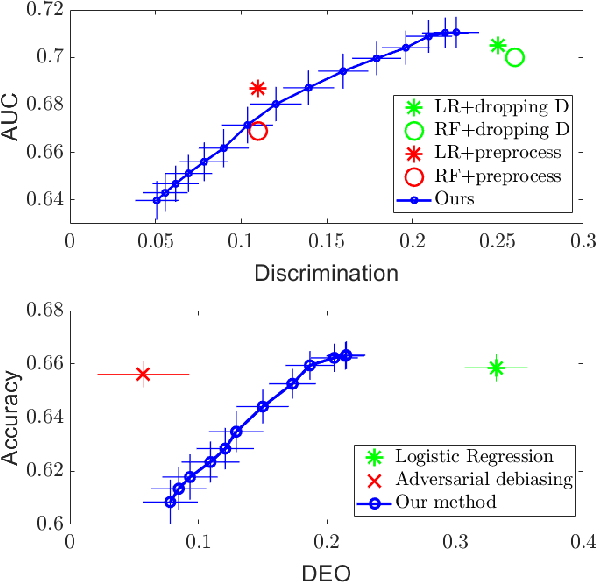
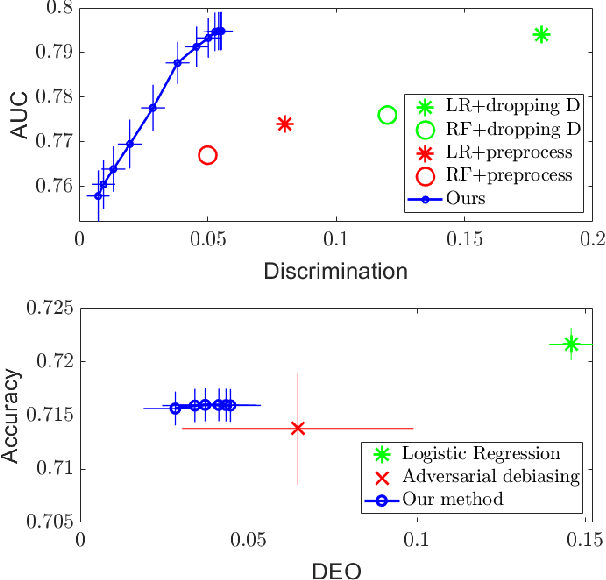
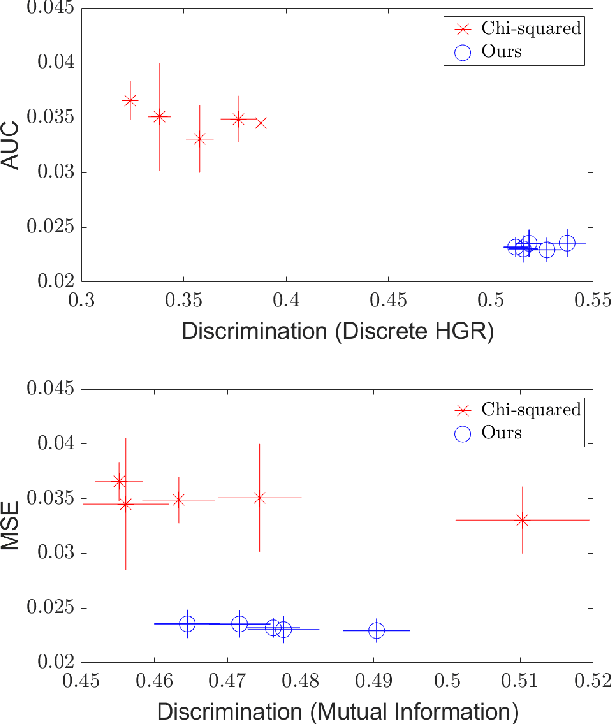
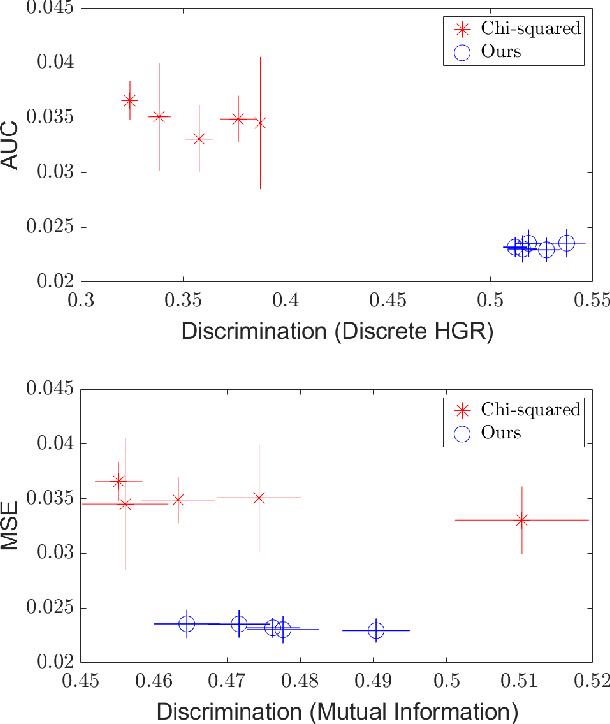
As machine learning algorithms grow in popularity and diversify to many industries, ethical and legal concerns regarding their fairness have become increasingly relevant. We explore the problem of algorithmic fairness, taking an information-theoretic view. The maximal correlation framework is introduced for expressing fairness constraints and shown to be capable of being used to derive regularizers that enforce independence and separation-based fairness criteria, which admit optimization algorithms for both discrete and continuous variables which are more computationally efficient than existing algorithms. We show that these algorithms provide smooth performance-fairness tradeoff curves and perform competitively with state-of-the-art methods on both discrete datasets (COMPAS, Adult) and continuous datasets (Communities and Crimes).
Getting to Know One Another: Calibrating Intent, Capabilities and Trust for Human-Robot Collaboration
Aug 03, 2020
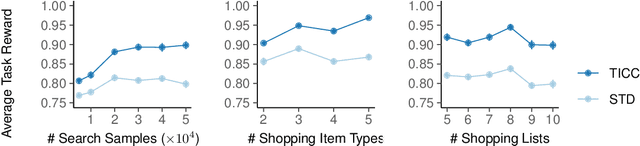
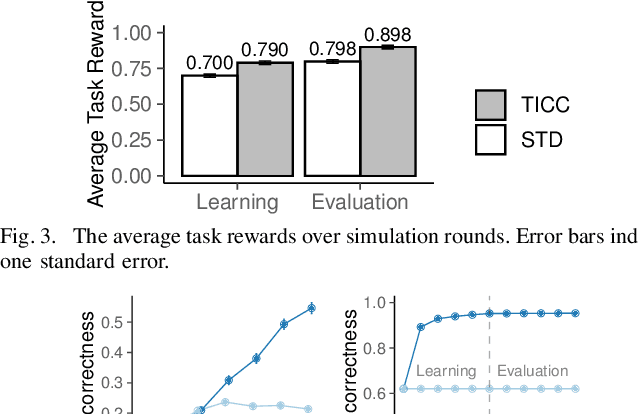

Common experience suggests that agents who know each other well are better able to work together. In this work, we address the problem of calibrating intention and capabilities in human-robot collaboration. In particular, we focus on scenarios where the robot is attempting to assist a human who is unable to directly communicate her intent. Moreover, both agents may have differing capabilities that are unknown to one another. We adopt a decision-theoretic approach and propose the TICC-POMDP for modeling this setting, with an associated online solver. Experiments show our approach leads to better team performance both in simulation and in a real-world study with human subjects.