 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicT: A Slim Weakly Supervised Vision Transformer for Pavement Distress Classification
Paper and Code
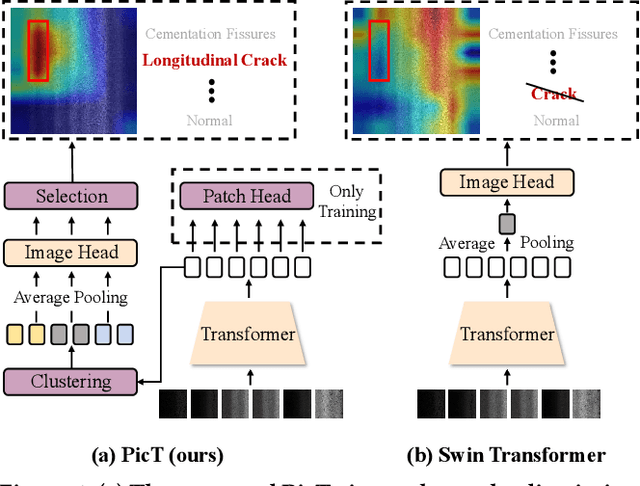
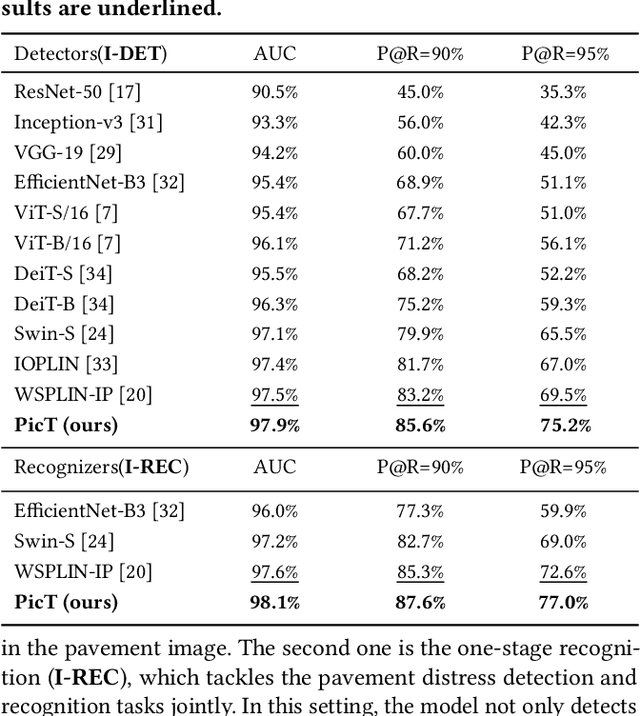
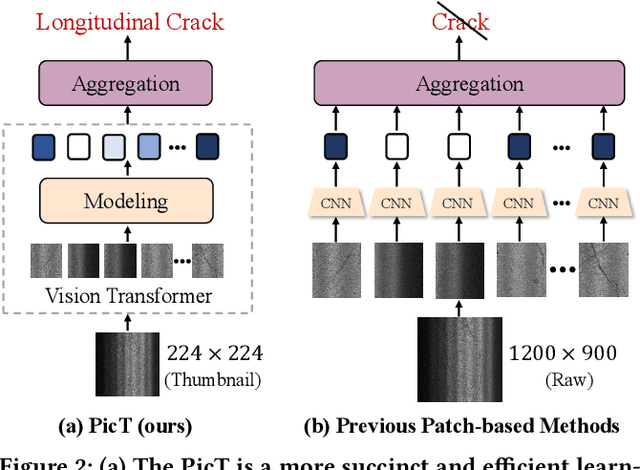
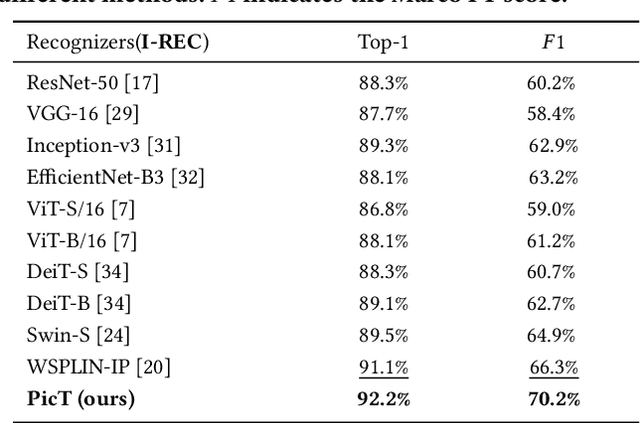
Automatic pavement distress classification facilitates improving the efficiency of pavement maintenance and reducing the cost of labor and resources. A recently influential branch of this task divides the pavement image into patches and addresses these issues from the perspective of multi-instance learning. However, these methods neglect the correlation between patches and suffer from a low efficiency in the model optimization and inference. Meanwhile, Swin Transformer is able to address both of these issues with its unique strengths. Built upon Swin Transformer, we present a vision Transformer named \textbf{P}avement \textbf{I}mage \textbf{C}lassification \textbf{T}ransformer (\textbf{PicT}) for pavement distress classification. In order to better exploit the discriminative information of pavement images at the patch level, the \textit{Patch Labeling Teacher} is proposed to leverage a teacher model to dynamically generate pseudo labels of patches from image labels during each iteration, and guides the model to learn the discriminative features of patches. The broad classification head of Swin Transformer may dilute the discriminative features of distressed patches in the feature aggregation step due to the small distressed area ratio of the pavement image. To overcome this drawback, we present a \textit{Patch Refiner} to cluster patches into different groups and only select the highest distress-risk group to yield a slim head for the final image classification. We evaluate our method on CQU-BPDD. Extensive results show that \textbf{PicT} outperforms the second-best performed model by a large margin of $+2.4\%$ in P@R on detection task, $+3.9\%$ in $F1$ on recognition task, and 1.8x throughput, while enjoying 7x faster training speed using the same computing resources. Our codes and models have been released on \href{https://github.com/DearCaat/PicT}{https://github.com/DearCaat/PicT}.