 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
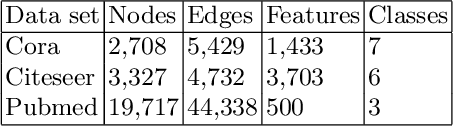
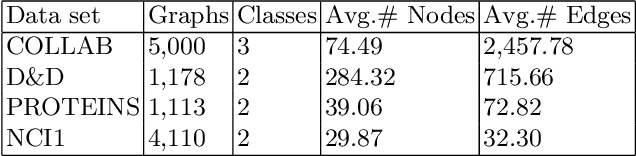
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
QoSBERT: An Uncertainty-Aware Approach based on Pre-trained Language Models for Service Quality Prediction
May 09, 2025Accurate prediction of Quality of Service (QoS) metrics is fundamental for selecting and managing cloud based services. Traditional QoS models rely on manual feature engineering and yield only point estimates, offering no insight into the confidence of their predictions. In this paper, we propose QoSBERT, the first framework that reformulates QoS prediction as a semantic regression task based on pre trained language models. Unlike previous approaches relying on sparse numerical features, QoSBERT automatically encodes user service metadata into natural language descriptions, enabling deep semantic understanding. Furthermore, we integrate a Monte Carlo Dropout based uncertainty estimation module, allowing for trustworthy and risk-aware service quality prediction, which is crucial yet underexplored in existing QoS models. QoSBERT applies attentive pooling over contextualized embeddings and a lightweight multilayer perceptron regressor, fine tuned jointly to minimize absolute error. We further exploit the resulting uncertainty estimates to select high quality training samples, improving robustness in low resource settings. On standard QoS benchmark datasets, QoSBERT achieves an average reduction of 11.7% in MAE and 6.7% in RMSE for response time prediction, and 6.9% in MAE for throughput prediction compared to the strongest baselines, while providing well calibrated confidence intervals for robust and trustworthy service quality estimation. Our approach not only advances the accuracy of service quality prediction but also delivers reliable uncertainty quantification, paving the way for more trustworthy, data driven service selection and optimization.
PO-GVINS: Tightly Coupled GNSS-Visual-Inertial Integration with Pose-Only Representation
Jan 16, 2025Accurate and reliable positioning is crucial for perception, decision-making, and other high-level applications in autonomous driving, unmanned aerial vehicles, and intelligent robots. Given the inherent limitations of standalone sensors, integrating heterogeneous sensors with complementary capabilities is one of the most effective approaches to achieving this goal. In this paper, we propose a filtering-based, tightly coupled global navigation satellite system (GNSS)-visual-inertial positioning framework with a pose-only formulation applied to the visual-inertial system (VINS), termed PO-GVINS. Specifically, multiple-view imaging used in current VINS requires a priori of 3D feature, then jointly estimate camera poses and 3D feature position, which inevitably introduces linearization error of the feature as well as facing dimensional explosion. However, the pose-only (PO) formulation, which is demonstrated to be equivalent to the multiple-view imaging and has been applied in visual reconstruction, represent feature depth using two camera poses and thus 3D feature position is removed from state vector avoiding aforementioned difficulties. Inspired by this, we first apply PO formulation in our VINS, i.e., PO-VINS. GNSS raw measurements are then incorporated with integer ambiguity resolved to achieve accurate and drift-free estimation. Extensive experiments demonstrate that the proposed PO-VINS significantly outperforms the multi-state constrained Kalman filter (MSCKF). By incorporating GNSS measurements, PO-GVINS achieves accurate, drift-free state estimation, making it a robust solution for positioning in challenging environments.
DiffSeg: A Segmentation Model for Skin Lesions Based on Diffusion Difference
Apr 25, 2024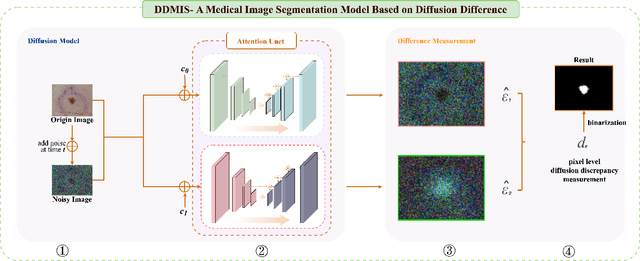
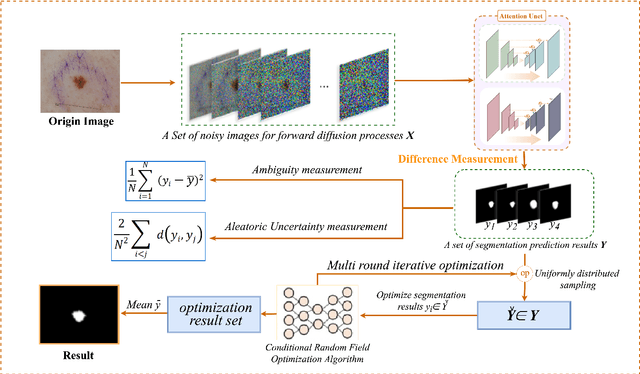
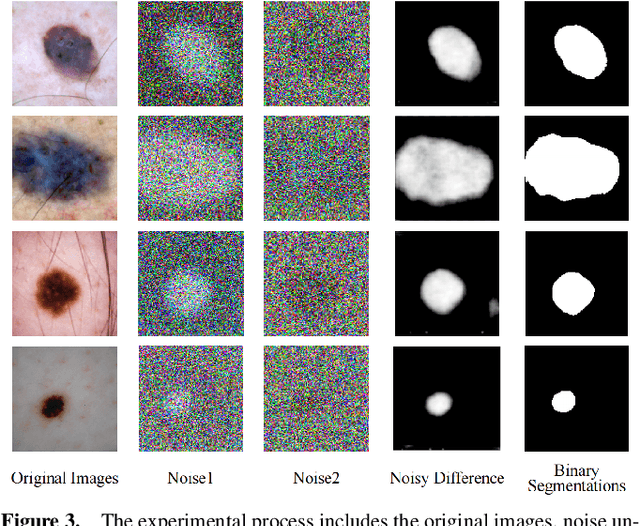

Weakly supervised medical image segmentation (MIS) using generative models is crucial for clinical diagnosis. However, the accuracy of the segmentation results is often limited by insufficient supervision and the complex nature of medical imaging. Existing models also only provide a single outcome, which does not allow for the measurement of uncertainty. In this paper, we introduce DiffSeg, a segmentation model for skin lesions based on diffusion difference which exploits diffusion model principles to ex-tract noise-based features from images with diverse semantic information. By discerning difference between these noise features, the model identifies diseased areas. Moreover, its multi-output capability mimics doctors' annotation behavior, facilitating the visualization of segmentation result consistency and ambiguity. Additionally, it quantifies output uncertainty using Generalized Energy Distance (GED), aiding interpretability and decision-making for physicians. Finally, the model integrates outputs through the Dense Conditional Random Field (DenseCRF) algorithm to refine the segmentation boundaries by considering inter-pixel correlations, which improves the accuracy and optimizes the segmentation results. We demonstrate the effectiveness of DiffSeg on the ISIC 2018 Challenge dataset, outperforming state-of-the-art U-Net-based methods.
On State Estimation in Multi-Sensor Fusion Navigation: Optimization and Filtering
Jan 11, 2024The essential of navigation, perception, and decision-making which are basic tasks for intelligent robots, is to estimate necessary system states. Among them, navigation is fundamental for other upper applications, providing precise position and orientation, by integrating measurements from multiple sensors. With observations of each sensor appropriately modelled, multi-sensor fusion tasks for navigation are reduced to the state estimation problem which can be solved by two approaches: optimization and filtering. Recent research has shown that optimization-based frameworks outperform filtering-based ones in terms of accuracy. However, both methods are based on maximum likelihood estimation (MLE) and should be theoretically equivalent with the same linearization points, observation model, measurements, and Gaussian noise assumption. In this paper, we deeply dig into the theories and existing strategies utilized in both optimization-based and filtering-based approaches. It is demonstrated that the two methods are equal theoretically, but this equivalence corrupts due to different strategies applied in real-time operation. By adjusting existing strategies of the filtering-based approaches, the Monte-Carlo simulation and vehicular ablation experiments based on visual odometry (VO) indicate that the strategy adjusted filtering strictly equals to optimization. Therefore, future research on sensor-fusion problems should concentrate on their own algorithms and strategies rather than state estimation approaches.
A Dual Latent State Learning Approach: Exploiting Regional Network Similarities for QoS Prediction
Oct 07, 2023



Individual objects, whether users or services, within a specific region often exhibit similar network states due to their shared origin from the same city or autonomous system (AS). Despite this regional network similarity, many existing techniques overlook its potential, resulting in subpar performance arising from challenges such as data sparsity and label imbalance. In this paper, we introduce the regional-based dual latent state learning network(R2SL), a novel deep learning framework designed to overcome the pitfalls of traditional individual object-based prediction techniques in Quality of Service (QoS) prediction. Unlike its predecessors, R2SL captures the nuances of regional network behavior by deriving two distinct regional network latent states: the city-network latent state and the AS-network latent state. These states are constructed utilizing aggregated data from common regions rather than individual object data. Furthermore, R2SL adopts an enhanced Huber loss function that adjusts its linear loss component, providing a remedy for prevalent label imbalance issues. To cap off the prediction process, a multi-scale perception network is leveraged to interpret the integrated feature map, a fusion of regional network latent features and other pertinent information, ultimately accomplishing the QoS prediction. Through rigorous testing on real-world QoS datasets, R2SL demonstrates superior performance compared to prevailing state-of-the-art methods. Our R2SL approach ushers in an innovative avenue for precise QoS predictions by fully harnessing the regional network similarities inherent in objects.
Probabilistic Deep Supervision Network: A Noise-Resilient Approach for QoS Prediction
Aug 03, 2023



Quality of Service (QoS) prediction is an essential task in recommendation systems, where accurately predicting unknown QoS values can improve user satisfaction. However, existing QoS prediction techniques may perform poorly in the presence of noise data, such as fake location information or virtual gateways. In this paper, we propose the Probabilistic Deep Supervision Network (PDS-Net), a novel framework for QoS prediction that addresses this issue. PDS-Net utilizes a Gaussian-based probabilistic space to supervise intermediate layers and learns probability spaces for both known features and true labels. Moreover, PDS-Net employs a condition-based multitasking loss function to identify objects with noise data and applies supervision directly to deep features sampled from the probability space by optimizing the Kullback-Leibler distance between the probability space of these objects and the real-label probability space. Thus, PDS-Net effectively reduces errors resulting from the propagation of corrupted data, leading to more accurate QoS predictions. Experimental evaluations on two real-world QoS datasets demonstrate that the proposed PDS-Net outperforms state-of-the-art baselines, validating the effectiveness of our approach.
Unsupervised Hierarchical Graph Representation Learning by Mutual Information Maximization
Apr 02, 2020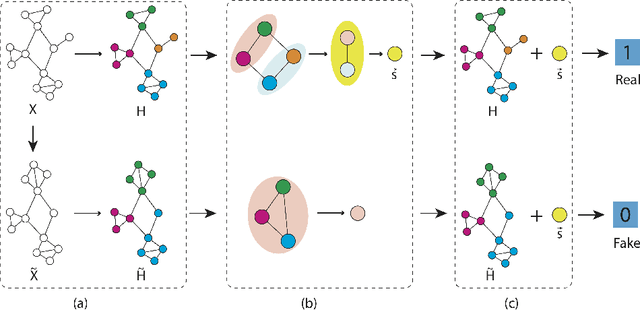
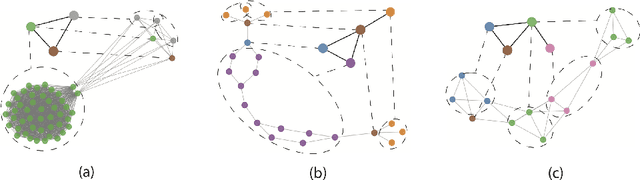
Graph representation learning based on graph neural networks (GNNs) can greatly improve the performance of downstream tasks, such as node and graph classification. However, the general GNN models do not aggregate node information in a hierarchical manner, and can miss key higher-order structural features of many graphs. The hierarchical aggregation also enables the graph representations to be explainable. In addition, supervised graph representation learning requires labeled data, which is expensive and error-prone. To address these issues, we present an unsupervised graph representation learning method, Unsupervised Hierarchical Graph Representation (UHGR), which can generate hierarchical representations of graphs. Our method focuses on maximizing mutual information between "local" and high-level "global" representations, which enables us to learn the node embeddings and graph embeddings without any labeled data. To demonstrate the effectiveness of the proposed method, we perform the node and graph classification using the learned node and graph embeddings. The results show that the proposed method achieves comparable results to state-of-the-art supervised methods on several benchmarks. In addition, our visualization of hierarchical representations indicates that our method can capture meaningful and interpretable clusters.
Regression-based Hypergraph Learning for Image Clustering and Classification
Mar 14, 2016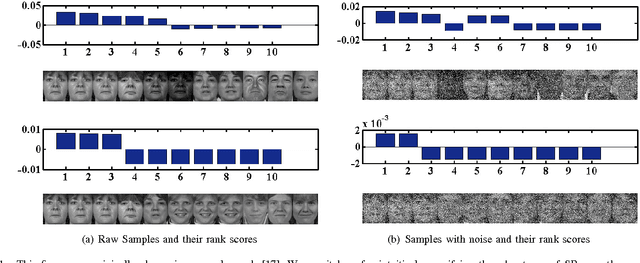


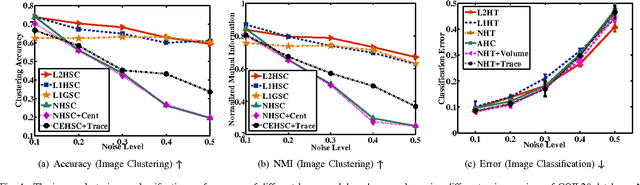
Inspired by the recently remarkable successes of Sparse Representation (SR), Collaborative Representation (CR) and sparse graph, we present a novel hypergraph model named Regression-based Hypergraph (RH) which utilizes the regression models to construct the high quality hypergraphs. Moreover, we plug RH into two conventional hypergraph learning frameworks, namely hypergraph spectral clustering and hypergraph transduction, to present Regression-based Hypergraph Spectral Clustering (RHSC) and Regression-based Hypergraph Transduction (RHT) models for addressing the image clustering and classification issues. Sparse Representation and Collaborative Representation are employed to instantiate two RH instances and their RHSC and RHT algorithms. The experimental results on six popular image databases demonstrate that the proposed RH learning algorithms achieve promising image clustering and classification performances, and also validate that RH can inherit the desirable properties from both hypergraph models and regression models.
Sparse Graph-based Transduction for Image Classification
Dec 12, 2014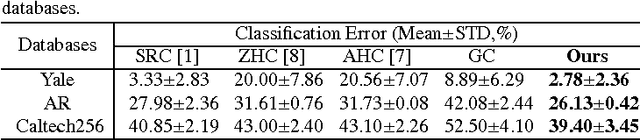
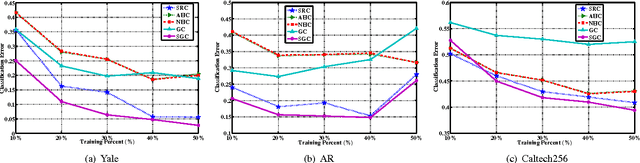
Motivated by the remarkable successes of Graph-based Transduction (GT) and Sparse Representation (SR), we present a novel Classifier named Sparse Graph-based Classifier (SGC) for image classification. In SGC, SR is leveraged to measure the correlation (similarity) of each two samples and a graph is constructed for encoding these correlations. Then the Laplacian eigenmapping is adopted for deriving the graph Laplacian of the graph. Finally, SGC can be obtained by plugging the graph Laplacian into the conventional GT framework. In the image classification procedure, SGC utilizes the correlations, which are encoded in the learned graph Laplacian, to infer the labels of unlabeled images. SGC inherits the merits of both GT and SR. Compared to SR, SGC improves the robustness and the discriminating power of GT. Compared to GT, SGC sufficiently exploits the whole data. Therefore it alleviates the undercomplete dictionary issue suffered by SR. Four popular image databases are employed for evaluation. The results demonstrate that SGC can achieve a promising performance in comparison with the state-of-the-art classifiers, particularly in the small training sample size case and the noisy sample case.