 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Robot Policy with Human Demonstration Video as a Prompt
May 27, 2025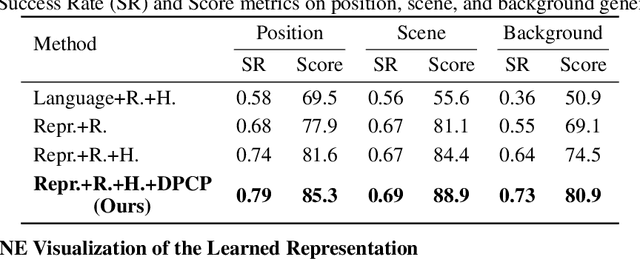

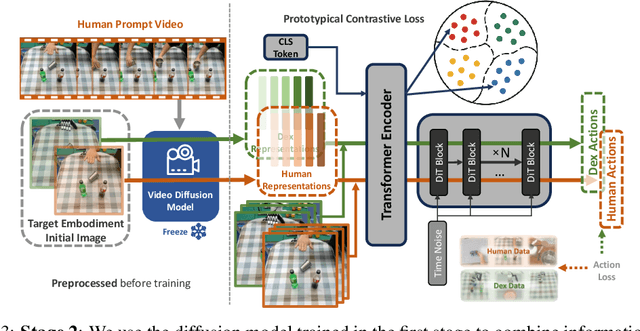
Recent robot learning methods commonly rely on imitation learning from massive robotic dataset collected with teleoperation. When facing a new task, such methods generally require collecting a set of new teleoperation data and finetuning the policy. Furthermore, the teleoperation data collection pipeline is also tedious and expensive. Instead, human is able to efficiently learn new tasks by just watching others do. In this paper, we introduce a novel two-stage framework that utilizes human demonstrations to learn a generalizable robot policy. Such policy can directly take human demonstration video as a prompt and perform new tasks without any new teleoperation data and model finetuning at all. In the first stage, we train video generation model that captures a joint representation for both the human and robot demonstration video data using cross-prediction. In the second stage, we fuse the learned representation with a shared action space between human and robot using a novel prototypical contrastive loss. Empirical evaluations on real-world dexterous manipulation tasks show the effectiveness and generalization capabilities of our proposed method.
High-Quality Spatial Reconstruction and Orthoimage Generation Using Efficient 2D Gaussian Splatting
Mar 25, 2025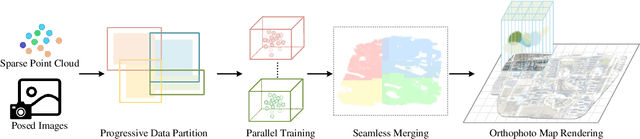
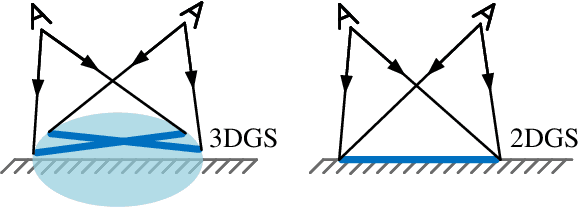
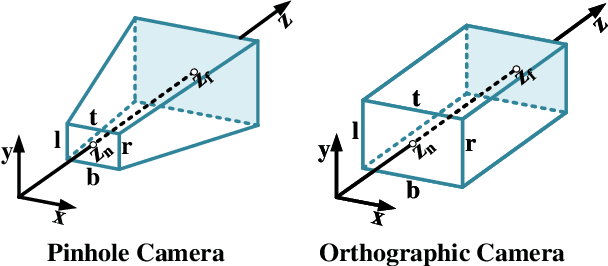
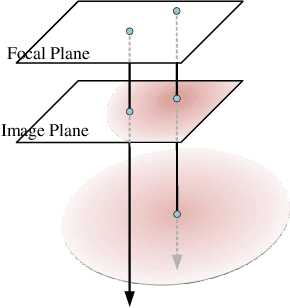
Highly accurate geometric precision and dense image features characterize True Digital Orthophoto Maps (TDOMs), which are in great demand for applications such as urban planning, infrastructure management, and environmental monitoring. Traditional TDOM generation methods need sophisticated processes, such as Digital Surface Models (DSM) and occlusion detection, which are computationally expensive and prone to errors. This work presents an alternative technique rooted in 2D Gaussian Splatting (2DGS), free of explicit DSM and occlusion detection. With depth map generation, spatial information for every pixel within the TDOM is retrieved and can reconstruct the scene with high precision. Divide-and-conquer strategy achieves excellent GS training and rendering with high-resolution TDOMs at a lower resource cost, which preserves higher quality of rendering on complex terrain and thin structure without a decrease in efficiency. Experimental results demonstrate the efficiency of large-scale scene reconstruction and high-precision terrain modeling. This approach provides accurate spatial data, which assists users in better planning and decision-making based on maps.
Video Super-Resolution: All You Need is a Video Diffusion Model
Mar 05, 2025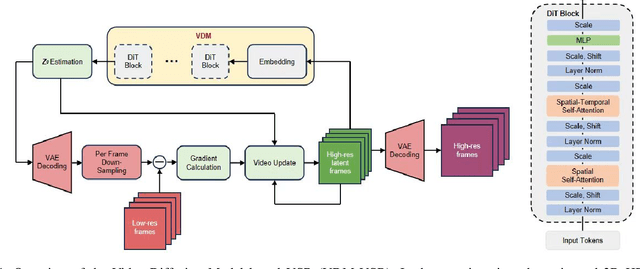


We present a generic video super-resolution algorithm in this paper, based on the Diffusion Posterior Sampling framework with an unconditional video generation model in latent space. The video generation model, a diffusion transformer, functions as a space-time model. We argue that a powerful model, which learns the physics of the real world, can easily handle various kinds of motion patterns as prior knowledge, thus eliminating the need for explicit estimation of optical flows or motion parameters for pixel alignment. Furthermore, a single instance of the proposed video diffusion transformer model can adapt to different sampling conditions without re-training. Due to limited computational resources and training data, our experiments provide empirical evidence of the algorithm's strong super-resolution capabilities using synthetic data.
A Multi-Sensor Fusion Approach for Rapid Orthoimage Generation in Large-Scale UAV Mapping
Mar 05, 2025Rapid generation of large-scale orthoimages from Unmanned Aerial Vehicles (UAVs) has been a long-standing focus of research in the field of aerial mapping. A multi-sensor UAV system, integrating the Global Positioning System (GPS), Inertial Measurement Unit (IMU), 4D millimeter-wave radar and camera, can provide an effective solution to this problem. In this paper, we utilize multi-sensor data to overcome the limitations of conventional orthoimage generation methods in terms of temporal performance, system robustness, and geographic reference accuracy. A prior-pose-optimized feature matching method is introduced to enhance matching speed and accuracy, reducing the number of required features and providing precise references for the Structure from Motion (SfM) process. The proposed method exhibits robustness in low-texture scenes like farmlands, where feature matching is difficult. Experiments show that our approach achieves accurate feature matching orthoimage generation in a short time. The proposed drone system effectively aids in farmland detection and management.
UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
Jan 31, 2025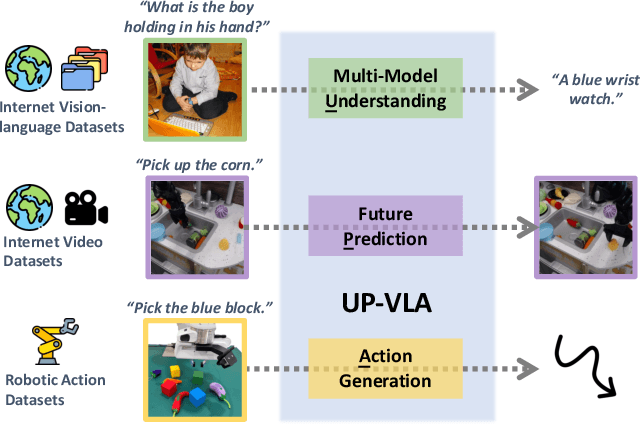
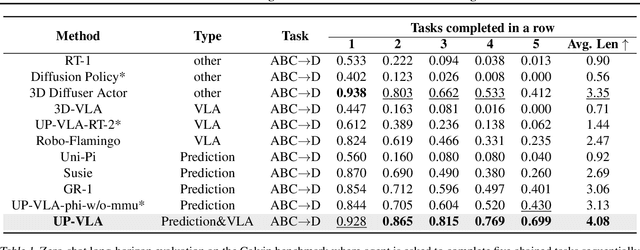
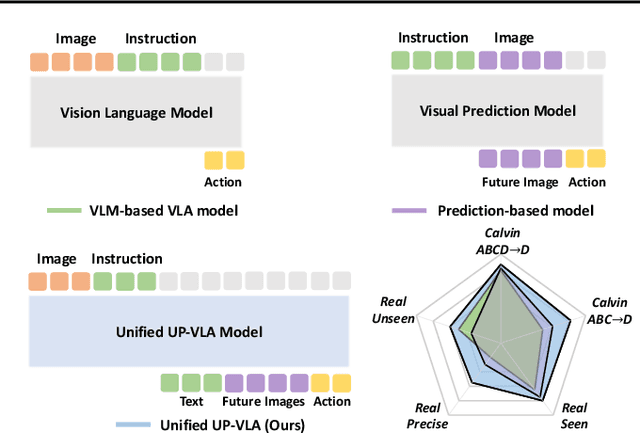
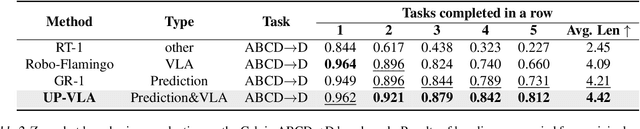
Recent advancements in Vision-Language-Action (VLA) models have leveraged pre-trained Vision-Language Models (VLMs) to improve the generalization capabilities. VLMs, typically pre-trained on vision-language understanding tasks, provide rich semantic knowledge and reasoning abilities. However, prior research has shown that VLMs often focus on high-level semantic content and neglect low-level features, limiting their ability to capture detailed spatial information and understand physical dynamics. These aspects, which are crucial for embodied control tasks, remain underexplored in existing pre-training paradigms. In this paper, we investigate the training paradigm for VLAs, and introduce \textbf{UP-VLA}, a \textbf{U}nified VLA model training with both multi-modal \textbf{U}nderstanding and future \textbf{P}rediction objectives, enhancing both high-level semantic comprehension and low-level spatial understanding. Experimental results show that UP-VLA achieves a 33% improvement on the Calvin ABC-D benchmark compared to the previous state-of-the-art method. Additionally, UP-VLA demonstrates improved success rates in real-world manipulation tasks, particularly those requiring precise spatial information.
Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Aug 26, 2024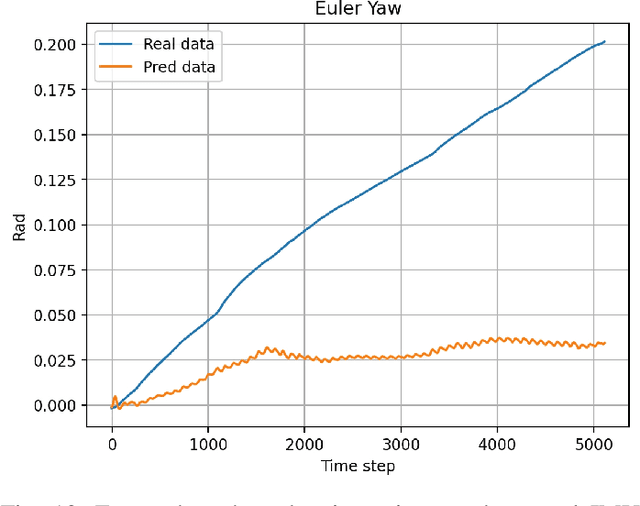
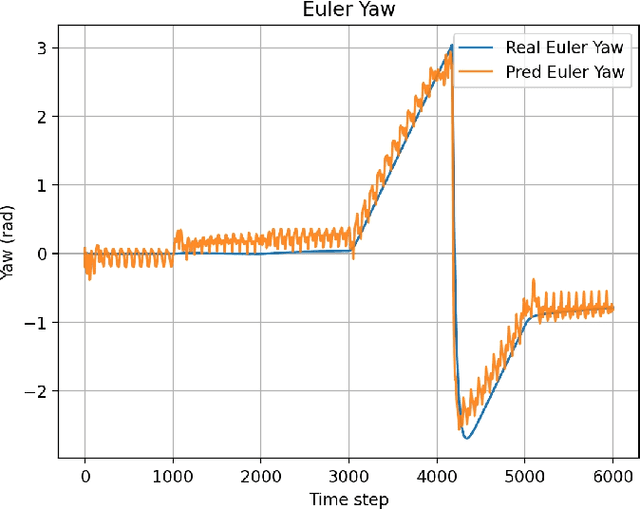
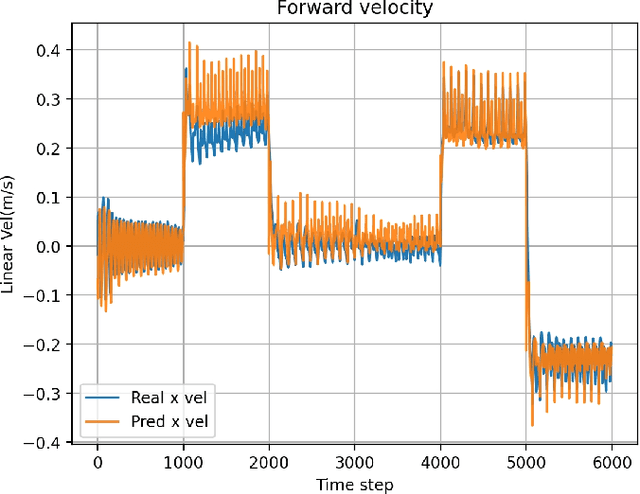
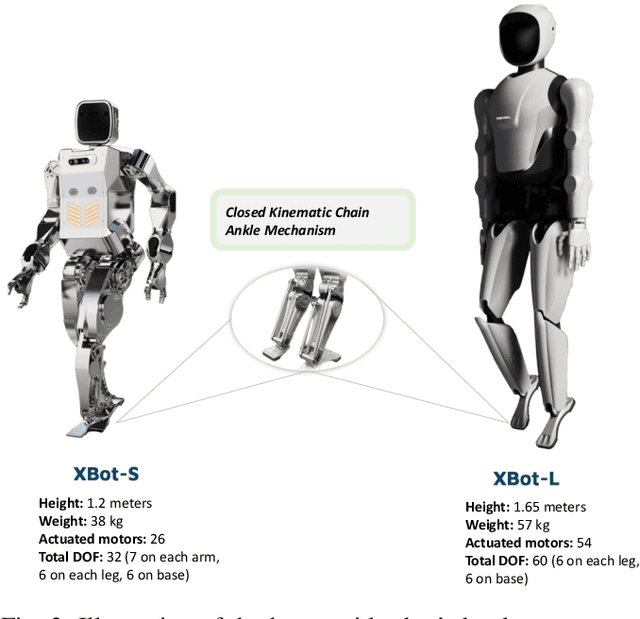
Humanoid robots, with their human-like skeletal structure, are especially suited for tasks in human-centric environments. However, this structure is accompanied by additional challenges in locomotion controller design, especially in complex real-world environments. As a result, existing humanoid robots are limited to relatively simple terrains, either with model-based control or model-free reinforcement learning. In this work, we introduce Denoising World Model Learning (DWL), an end-to-end reinforcement learning framework for humanoid locomotion control, which demonstrates the world's first humanoid robot to master real-world challenging terrains such as snowy and inclined land in the wild, up and down stairs, and extremely uneven terrains. All scenarios run the same learned neural network with zero-shot sim-to-real transfer, indicating the superior robustness and generalization capability of the proposed method.
RCDM: Enabling Robustness for Conditional Diffusion Model
Aug 05, 2024
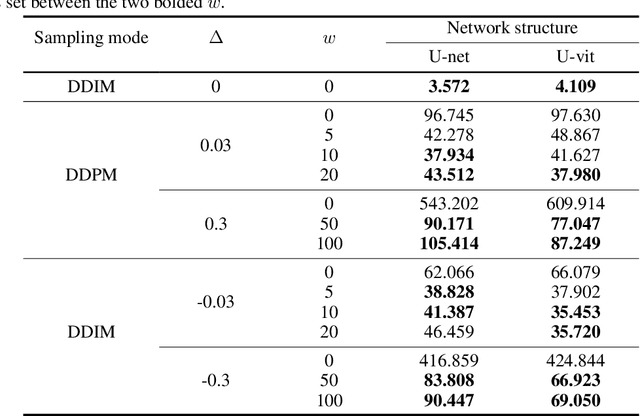
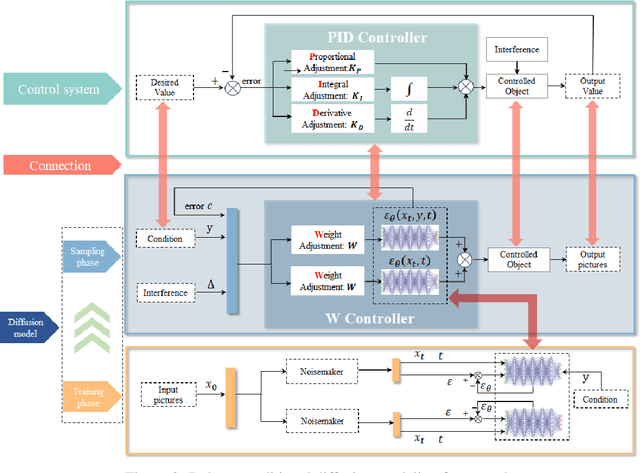
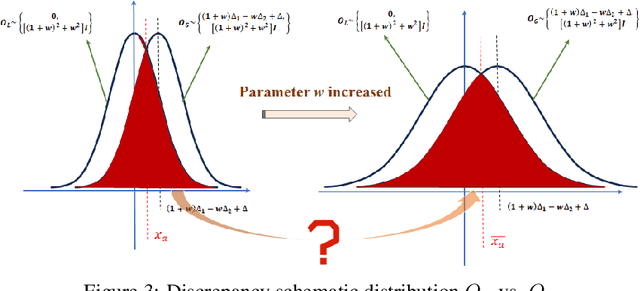
The conditional diffusion model (CDM) enhances the standard diffusion model by providing more control, improving the quality and relevance of the outputs, and making the model adaptable to a wider range of complex tasks. However, inaccurate conditional inputs in the inverse process of CDM can easily lead to generating fixed errors in the neural network, which diminishes the adaptability of a well-trained model. The existing methods like data augmentation, adversarial training, robust optimization can improve the robustness, while they often face challenges such as high computational complexity, limited applicability to unknown perturbations, and increased training difficulty. In this paper, we propose a lightweight solution, the Robust Conditional Diffusion Model (RCDM), based on control theory to dynamically reduce the impact of noise and significantly enhance the model's robustness. RCDM leverages the collaborative interaction between two neural networks, along with optimal control strategies derived from control theory, to optimize the weights of two networks during the sampling process. Unlike conventional techniques, RCDM establishes a mathematical relationship between fixed errors and the weights of the two neural networks without incurring additional computational overhead. Extensive experiments were conducted on MNIST and CIFAR-10 datasets, and the results demonstrate the effectiveness and adaptability of our proposed model.
Feature Re-Embedding: Towards Foundation Model-Level Performance in Computational Pathology
Feb 27, 2024Multiple instance learning (MIL) is the most widely used framework in computational pathology, encompassing sub-typing, diagnosis, prognosis, and more. However, the existing MIL paradigm typically requires an offline instance feature extractor, such as a pre-trained ResNet or a foundation model. This approach lacks the capability for feature fine-tuning within the specific downstream tasks, limiting its adaptability and performance. To address this issue, we propose a Re-embedded Regional Transformer (R$^2$T) for re-embedding the instance features online, which captures fine-grained local features and establishes connections across different regions. Unlike existing works that focus on pre-training powerful feature extractor or designing sophisticated instance aggregator, R$^2$T is tailored to re-embed instance features online. It serves as a portable module that can seamlessly integrate into mainstream MIL models. Extensive experimental results on common computational pathology tasks validate that: 1) feature re-embedding improves the performance of MIL models based on ResNet-50 features to the level of foundation model features, and further enhances the performance of foundation model features; 2) the R$^2$T can introduce more significant performance improvements to various MIL models; 3) R$^2$T-MIL, as an R$^2$T-enhanced AB-MIL, outperforms other latest methods by a large margin. The code is available at:~\href{https://github.com/DearCaat/RRT-MIL}{https://github.com/DearCaat/RRT-MIL}.
Stylized Table Tennis Robots Skill Learning with Incomplete Human Demonstrations
Sep 16, 2023In recent years, Reinforcement Learning (RL) is becoming a popular technique for training controllers for robots. However, for complex dynamic robot control tasks, RL-based method often produces controllers with unrealistic styles. In contrast, humans can learn well-stylized skills under supervisions. For example, people learn table tennis skills by imitating the motions of coaches. Such reference motions are often incomplete, e.g. without the presence of an actual ball. Inspired by this, we propose an RL-based algorithm to train a robot that can learn the playing style from such incomplete human demonstrations. We collect data through the teaching-and-dragging method. We also propose data augmentation techniques to enable our robot to adapt to balls of different velocities. We finally evaluate our policy in different simulators with varying dynamics.
Incorporating Domain Knowledge through Task Augmentation for Front-End JavaScript Code Generation
Aug 23, 2022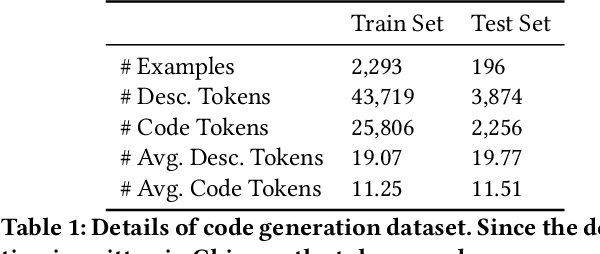

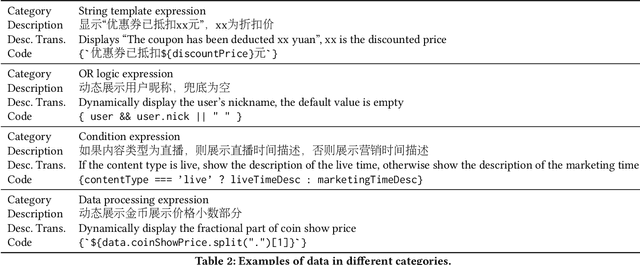
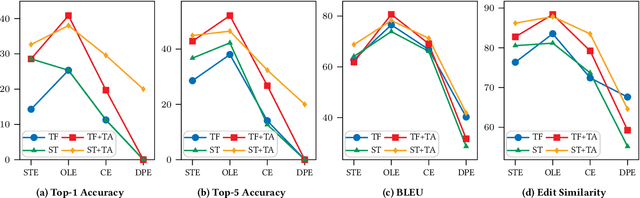
Code generation aims to generate a code snippet automatically from natural language descriptions. Generally, the mainstream code generation methods rely on a large amount of paired training data, including both the natural language description and the code. However, in some domain-specific scenarios, building such a large paired corpus for code generation is difficult because there is no directly available pairing data, and a lot of effort is required to manually write the code descriptions to construct a high-quality training dataset. Due to the limited training data, the generation model cannot be well trained and is likely to be overfitting, making the model's performance unsatisfactory for real-world use. To this end, in this paper, we propose a task augmentation method that incorporates domain knowledge into code generation models through auxiliary tasks and a Subtoken-TranX model by extending the original TranX model to support subtoken-level code generation. To verify our proposed approach, we collect a real-world code generation dataset and conduct experiments on it. Our experimental results demonstrate that the subtoken-level TranX model outperforms the original TranX model and the Transformer model on our dataset, and the exact match accuracy of Subtoken-TranX improves significantly by 12.75% with the help of our task augmentation method. The model performance on several code categories has satisfied the requirements for application in industrial systems. Our proposed approach has been adopted by Alibaba's BizCook platform. To the best of our knowledge, this is the first domain code generation system adopted in industrial development environments.