 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Domain Knowledge through Task Augmentation for Front-End JavaScript Code Generation
Paper and Code
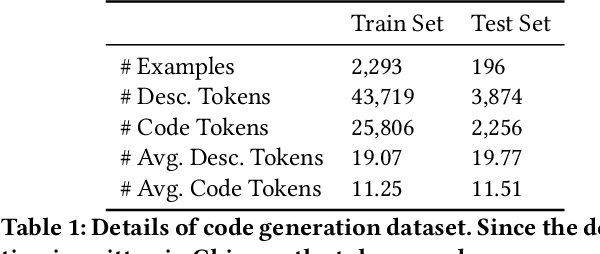

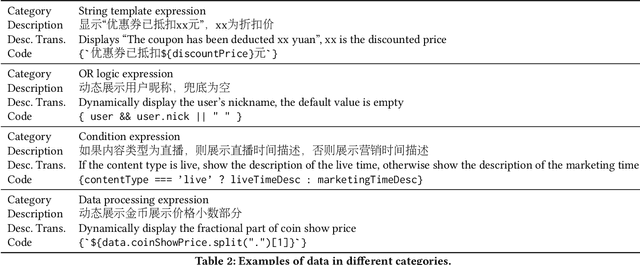
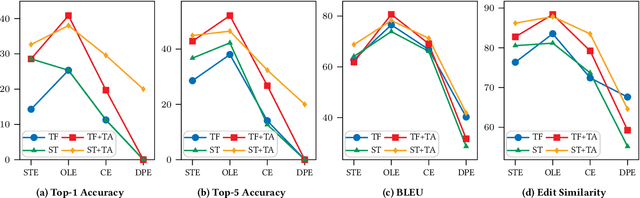
Code generation aims to generate a code snippet automatically from natural language descriptions. Generally, the mainstream code generation methods rely on a large amount of paired training data, including both the natural language description and the code. However, in some domain-specific scenarios, building such a large paired corpus for code generation is difficult because there is no directly available pairing data, and a lot of effort is required to manually write the code descriptions to construct a high-quality training dataset. Due to the limited training data, the generation model cannot be well trained and is likely to be overfitting, making the model's performance unsatisfactory for real-world use. To this end, in this paper, we propose a task augmentation method that incorporates domain knowledge into code generation models through auxiliary tasks and a Subtoken-TranX model by extending the original TranX model to support subtoken-level code generation. To verify our proposed approach, we collect a real-world code generation dataset and conduct experiments on it. Our experimental results demonstrate that the subtoken-level TranX model outperforms the original TranX model and the Transformer model on our dataset, and the exact match accuracy of Subtoken-TranX improves significantly by 12.75% with the help of our task augmentation method. The model performance on several code categories has satisfied the requirements for application in industrial systems. Our proposed approach has been adopted by Alibaba's BizCook platform. To the best of our knowledge, this is the first domain code generation system adopted in industrial development environments.