 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Dilemma of Performance and Index Size in Billion-Scale Vector Search and Breaking It with Second-Tier Memory
May 07, 2024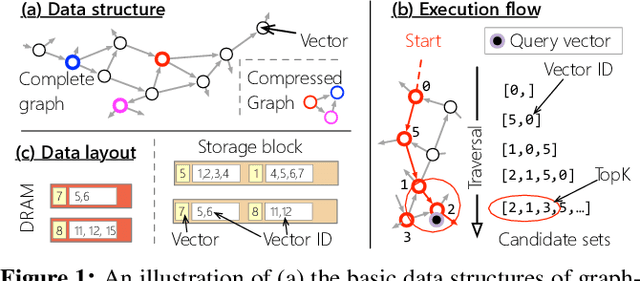

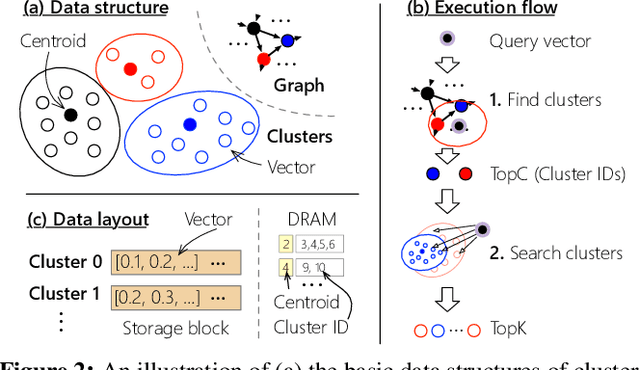

Vector searches on large-scale datasets are critical to modern online services like web search and RAG, which necessity storing the datasets and their index on the secondary storage like SSD. In this paper, we are the first to characterize the trade-off of performance and index size in existing SSD-based graph and cluster indexes: to improve throughput by 5.7$\times$ and 1.7$\times$, these indexes have to pay a 5.8$\times$ storage amplification and 7.7$\times$ with respect to the dataset size, respectively. The root cause is that the coarse-grained access of SSD mismatches the fine-grained random read required by vector indexes with small amplification. This paper argues that second-tier memory, such as remote DRAM/NVM connected via RDMA or CXL, is a powerful storage for addressing the problem from a system's perspective, thanks to its fine-grained access granularity. However, putting existing indexes -- primarily designed for SSD -- directly on second-tier memory cannot fully utilize its power. Meanwhile, second-tier memory still behaves more like storage, so using it as DRAM is also inefficient. To this end, we build a graph and cluster index that centers around the performance features of second-tier memory. With careful execution engine and index layout designs, we show that vector indexes can achieve optimal performance with orders of magnitude smaller index amplification, on a variety of second-tier memory devices. Based on our improved graph and vector indexes on second-tier memory, we further conduct a systematic study between them to facilitate developers choosing the right index for their workloads. Interestingly, the findings on the second-tier memory contradict the ones on SSDs.
Incorporating Domain Knowledge through Task Augmentation for Front-End JavaScript Code Generation
Aug 23, 2022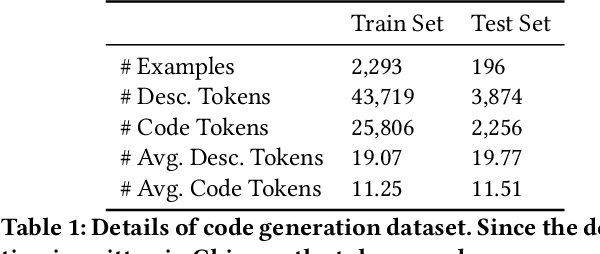

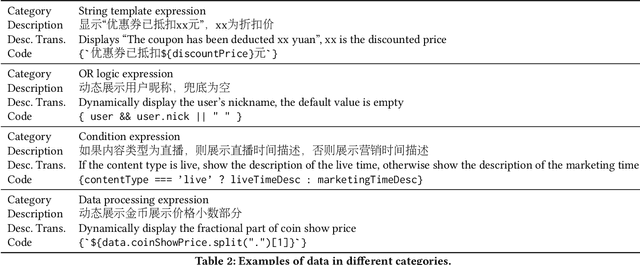
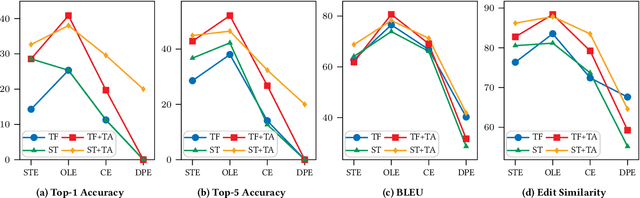
Code generation aims to generate a code snippet automatically from natural language descriptions. Generally, the mainstream code generation methods rely on a large amount of paired training data, including both the natural language description and the code. However, in some domain-specific scenarios, building such a large paired corpus for code generation is difficult because there is no directly available pairing data, and a lot of effort is required to manually write the code descriptions to construct a high-quality training dataset. Due to the limited training data, the generation model cannot be well trained and is likely to be overfitting, making the model's performance unsatisfactory for real-world use. To this end, in this paper, we propose a task augmentation method that incorporates domain knowledge into code generation models through auxiliary tasks and a Subtoken-TranX model by extending the original TranX model to support subtoken-level code generation. To verify our proposed approach, we collect a real-world code generation dataset and conduct experiments on it. Our experimental results demonstrate that the subtoken-level TranX model outperforms the original TranX model and the Transformer model on our dataset, and the exact match accuracy of Subtoken-TranX improves significantly by 12.75% with the help of our task augmentation method. The model performance on several code categories has satisfied the requirements for application in industrial systems. Our proposed approach has been adopted by Alibaba's BizCook platform. To the best of our knowledge, this is the first domain code generation system adopted in industrial development environments.
Towards Full-line Code Completion with Neural Language Models
Sep 18, 2020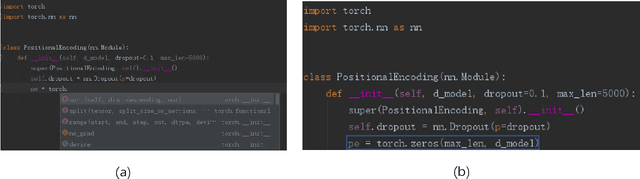



A code completion system suggests future code elements to developers given a partially-complete code snippet. Code completion is one of the most useful features in Integrated Development Environments (IDEs). Currently, most code completion techniques predict a single token at a time. In this paper, we take a further step and discuss the probability of directly completing a whole line of code instead of a single token. We believe suggesting longer code sequences can further improve the efficiency of developers. Recently neural language models have been adopted as a preferred approach for code completion, and we believe these models can still be applied to full-line code completion with a few improvements. We conduct our experiments on two real-world python corpora and evaluate existing neural models based on source code tokens or syntactical actions. The results show that neural language models can achieve acceptable results on our tasks, with significant room for improvements.
Self-adaptive Single and Multi-illuminant Estimation Framework based on Deep Learning
Feb 13, 2019
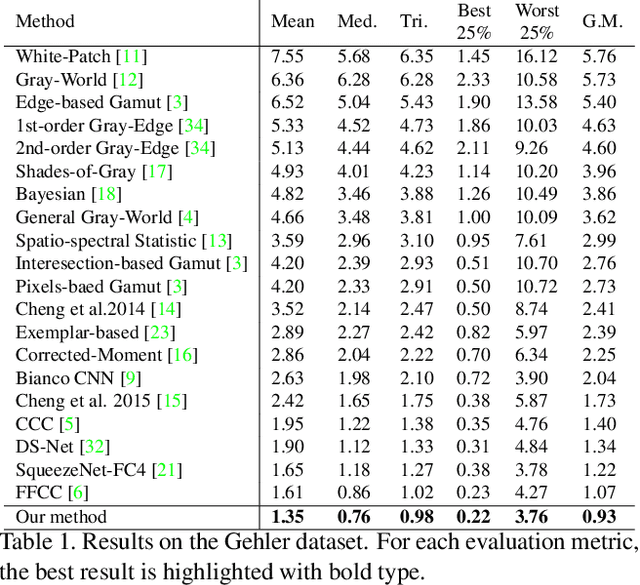
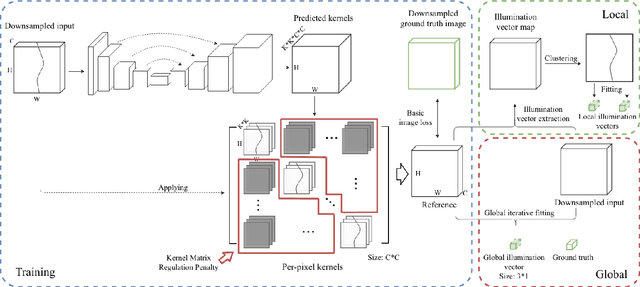
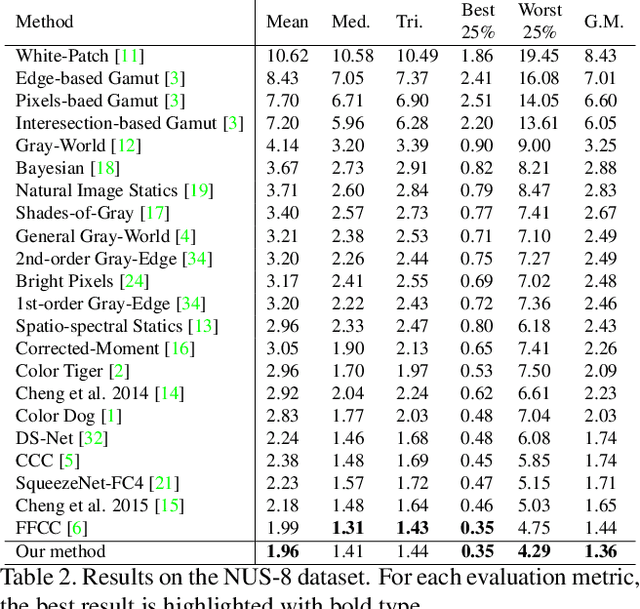
Illuminant estimation plays a key role in digital camera pipeline system, it aims at reducing color casting effect due to the influence of non-white illuminant. Recent researches handle this task by using Convolution Neural Network (CNN) as a mapping function from input image to a single illumination vector. However, global mapping approaches are difficult to deal with scenes under multi-light-sources. In this paper, we proposed a self-adaptive single and multi-illuminant estimation framework, which includes the following novelties: (1) Learning local self-adaptive kernels from the entire image for illuminant estimation with encoder-decoder CNN structure; (2) Providing confidence measurement for the prediction; (3) Clustering-based iterative fitting for computing single and multi-illumination vectors. The proposed global-to-local aggregation is able to predict multi-illuminant regionally by utilizing global information instead of training in patches, as well as brings significant improvement for single illuminant estimation. We outperform the state-of-the-art methods on standard benchmarks with the largest relative improvement of 16%. In addition, we collect a dataset contains over 13k images for illuminant estimation and evaluation. The code and dataset is available on https://github.com/LiamLYJ/KPF_WB