 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunServe: Elastic and Efficient Large Language Model Serving with Parameter-centric Memory Management
Dec 24, 2024The stateful nature of large language model (LLM) servingcan easily throttle precious GPU memory under load burstor long-generation requests like chain-of-thought reasoning,causing latency spikes due to queuing incoming requests. However, state-of-the-art KVCache centric approaches handleload spikes by dropping, migrating, or swapping KVCache,which faces an essential tradeoff between the performance ofongoing vs. incoming requests and thus still severely violatesSLO.This paper makes a key observation such that model param-eters are independent of the requests and are replicated acrossGPUs, and thus proposes a parameter-centric approach byselectively dropping replicated parameters to leave preciousmemory for requests. However, LLM requires KVCache tobe saved in bound with model parameters and thus droppingparameters can cause either huge computation waste or longnetwork delay, affecting all ongoing requests. Based on the ob-servation that attention operators can be decoupled from otheroperators, this paper further proposes a novel remote attentionmechanism through pipeline parallelism so as to serve up-coming requests with the additional memory borrowed fromparameters on remote GPUs. This paper further addresses sev-eral other challenges including lively exchanging KVCachewith incomplete parameters, generating an appropriate planthat balances memory requirements with cooperative exe-cution overhead, and seamlessly restoring parameters whenthe throttling has gone. Evaluations show thatKUNSERVEreduces the tail TTFT of requests under throttling by up to 27.3x compared to the state-of-the-art.
Characterizing the Dilemma of Performance and Index Size in Billion-Scale Vector Search and Breaking It with Second-Tier Memory
May 07, 2024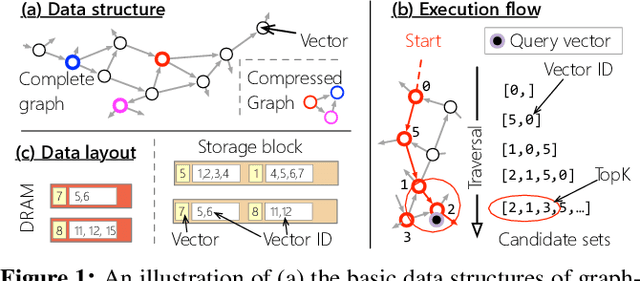

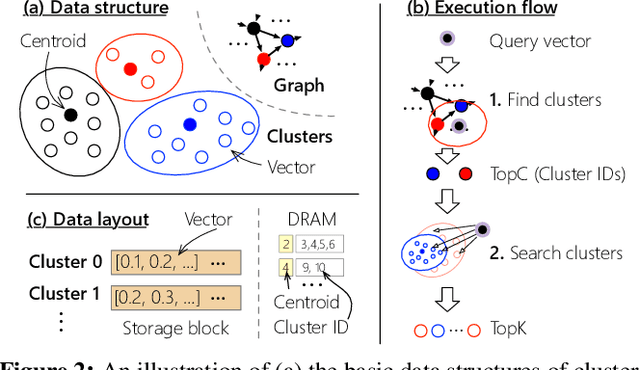

Vector searches on large-scale datasets are critical to modern online services like web search and RAG, which necessity storing the datasets and their index on the secondary storage like SSD. In this paper, we are the first to characterize the trade-off of performance and index size in existing SSD-based graph and cluster indexes: to improve throughput by 5.7$\times$ and 1.7$\times$, these indexes have to pay a 5.8$\times$ storage amplification and 7.7$\times$ with respect to the dataset size, respectively. The root cause is that the coarse-grained access of SSD mismatches the fine-grained random read required by vector indexes with small amplification. This paper argues that second-tier memory, such as remote DRAM/NVM connected via RDMA or CXL, is a powerful storage for addressing the problem from a system's perspective, thanks to its fine-grained access granularity. However, putting existing indexes -- primarily designed for SSD -- directly on second-tier memory cannot fully utilize its power. Meanwhile, second-tier memory still behaves more like storage, so using it as DRAM is also inefficient. To this end, we build a graph and cluster index that centers around the performance features of second-tier memory. With careful execution engine and index layout designs, we show that vector indexes can achieve optimal performance with orders of magnitude smaller index amplification, on a variety of second-tier memory devices. Based on our improved graph and vector indexes on second-tier memory, we further conduct a systematic study between them to facilitate developers choosing the right index for their workloads. Interestingly, the findings on the second-tier memory contradict the ones on SSDs.