 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyTopo: Dynamic Topology Routing for Multi-Agent Reasoning via Semantic Matching
Feb 05, 2026Multi-agent systems built from prompted large language models can improve multi-round reasoning, yet most existing pipelines rely on fixed, trajectory-wide communication patterns that are poorly matched to the stage-dependent needs of iterative problem solving. We introduce DyTopo, a manager-guided multi-agent framework that reconstructs a sparse directed communication graph at each round. Conditioned on the manager's round goal, each agent outputs lightweight natural-language query (need) and \key (offer) descriptors; DyTopo embeds these descriptors and performs semantic matching, routing private messages only along the induced edges. Across code generation and mathematical reasoning benchmarks and four LLM backbones, DyTopo consistently outperforms over the strongest baseline (avg. +6.2). Beyond accuracy, DyTopo yields an interpretable coordination trace via the evolving graphs, enabling qualitative inspection of how communication pathways reconfigure across rounds.
CLM-Bench: Benchmarking and Analyzing Cross-lingual Misalignment of LLMs in Knowledge Editing
Jan 24, 2026Knowledge Editing (KE) has emerged as a promising paradigm for updating facts in Large Language Models (LLMs) without retraining. However, progress in Multilingual Knowledge Editing (MKE) is currently hindered by biased evaluation frameworks. We observe that existing MKE benchmarks are typically constructed by mechanically translating English-centric datasets into target languages (e.g., English-to-Chinese). This approach introduces translation artifacts and neglects culturally specific entities native to the target language, failing to reflect the true knowledge distribution of LLMs. To address this, we propose CLM-Bench, a culture-aware benchmark constructed using a native Chinese-first methodology. We curate 1,010 high-quality CounterFact pairs rooted in Chinese cultural contexts and align them with English counterparts. Using CLM-Bench, we conduct extensive experiments on representative LLMs (e.g., Llama-3, Qwen2) and reveal a significant Cross-lingual Misalignment: edits in one language function independently and fail to propagate to the other. We further provide a geometric explanation via layer-wise representation analysis, demonstrating that edit vectors for Chinese and English are nearly orthogonal -- residing in disjoint subspaces -- while mixed-lingual editing exhibits linear additivity of these vectors. Our findings challenge the effectiveness of current methods in cross-lingual transfer and underscore the importance of culturally native benchmarks.
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
Rethinking Agent Design: From Top-Down Workflows to Bottom-Up Skill Evolution
May 23, 2025Most LLM-based agent frameworks adopt a top-down philosophy: humans decompose tasks, define workflows, and assign agents to execute each step. While effective on benchmark-style tasks, such systems rely on designer updates and overlook agents' potential to learn from experience. Recently, Silver and Sutton(2025) envision a shift into a new era, where agents could progress from a stream of experiences. In this paper, we instantiate this vision of experience-driven learning by introducing a bottom-up agent paradigm that mirrors the human learning process. Agents acquire competence through a trial-and-reasoning mechanism-exploring, reflecting on outcomes, and abstracting skills over time. Once acquired, skills can be rapidly shared and extended, enabling continual evolution rather than static replication. As more agents are deployed, their diverse experiences accelerate this collective process, making bottom-up design especially suited for open-ended environments. We evaluate this paradigm in Slay the Spire and Civilization V, where agents perceive through raw visual inputs and act via mouse outputs, the same as human players. Using a unified, game-agnostic codebase without any game-specific prompts or privileged APIs, our bottom-up agents acquire skills entirely through autonomous interaction, demonstrating the potential of the bottom-up paradigm in complex, real-world environments. Our code is available at https://github.com/AngusDujw/Bottom-Up-Agent.
UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
Jan 31, 2025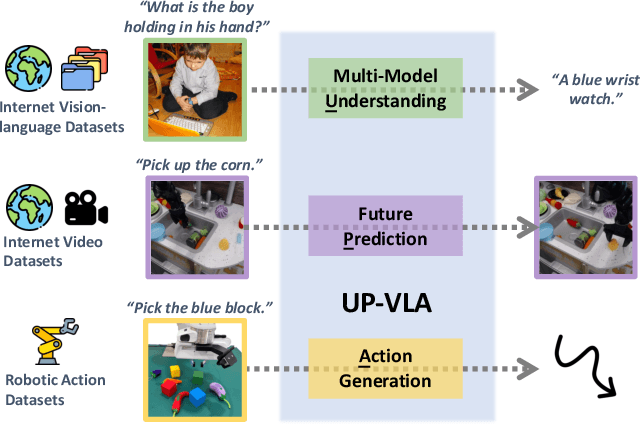
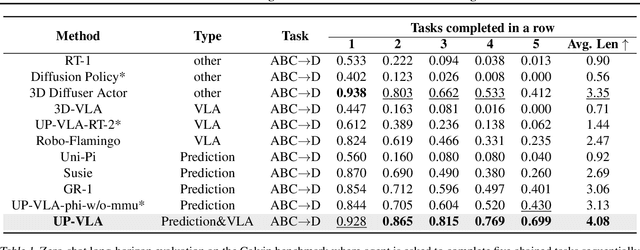
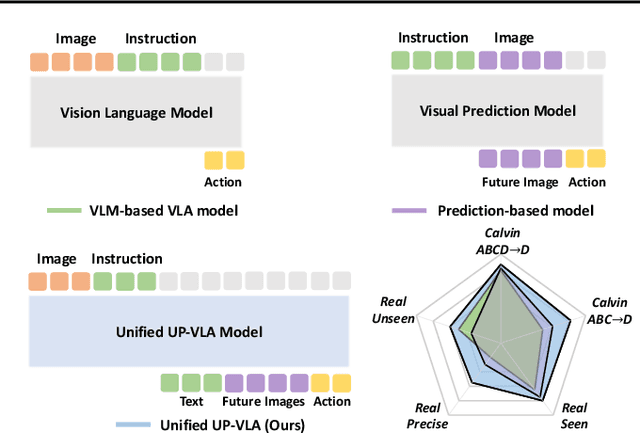
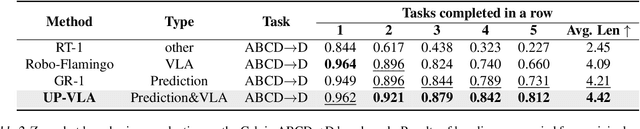
Recent advancements in Vision-Language-Action (VLA) models have leveraged pre-trained Vision-Language Models (VLMs) to improve the generalization capabilities. VLMs, typically pre-trained on vision-language understanding tasks, provide rich semantic knowledge and reasoning abilities. However, prior research has shown that VLMs often focus on high-level semantic content and neglect low-level features, limiting their ability to capture detailed spatial information and understand physical dynamics. These aspects, which are crucial for embodied control tasks, remain underexplored in existing pre-training paradigms. In this paper, we investigate the training paradigm for VLAs, and introduce \textbf{UP-VLA}, a \textbf{U}nified VLA model training with both multi-modal \textbf{U}nderstanding and future \textbf{P}rediction objectives, enhancing both high-level semantic comprehension and low-level spatial understanding. Experimental results show that UP-VLA achieves a 33% improvement on the Calvin ABC-D benchmark compared to the previous state-of-the-art method. Additionally, UP-VLA demonstrates improved success rates in real-world manipulation tasks, particularly those requiring precise spatial information.
Improving Vision-Language-Action Model with Online Reinforcement Learning
Jan 28, 2025
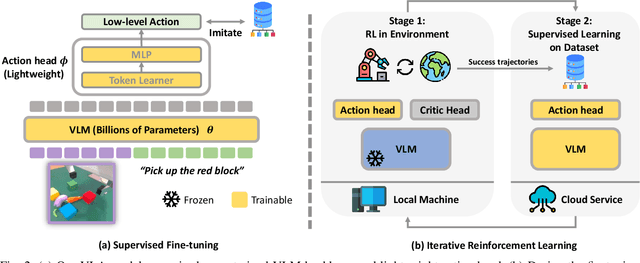

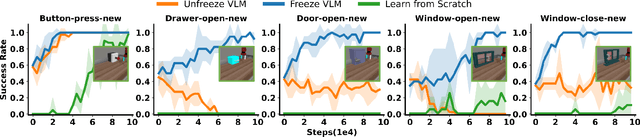
Recent studies have successfully integrated large vision-language models (VLMs) into low-level robotic control by supervised fine-tuning (SFT) with expert robotic datasets, resulting in what we term vision-language-action (VLA) models. Although the VLA models are powerful, how to improve these large models during interaction with environments remains an open question. In this paper, we explore how to further improve these VLA models via Reinforcement Learning (RL), a commonly used fine-tuning technique for large models. However, we find that directly applying online RL to large VLA models presents significant challenges, including training instability that severely impacts the performance of large models, and computing burdens that exceed the capabilities of most local machines. To address these challenges, we propose iRe-VLA framework, which iterates between Reinforcement Learning and Supervised Learning to effectively improve VLA models, leveraging the exploratory benefits of RL while maintaining the stability of supervised learning. Experiments in two simulated benchmarks and a real-world manipulation suite validate the effectiveness of our method.
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Dec 19, 2024



Recent advancements in robotics have focused on developing generalist policies capable of performing multiple tasks. Typically, these policies utilize pre-trained vision encoders to capture crucial information from current observations. However, previous vision encoders, which trained on two-image contrastive learning or single-image reconstruction, can not perfectly capture the sequential information essential for embodied tasks. Recently, video diffusion models (VDMs) have demonstrated the capability to accurately predict future image sequences, exhibiting a good understanding of physical dynamics. Motivated by the strong visual prediction capabilities of VDMs, we hypothesize that they inherently possess visual representations that reflect the evolution of the physical world, which we term predictive visual representations. Building on this hypothesis, we propose the Video Prediction Policy (VPP), a generalist robotic policy conditioned on the predictive visual representations from VDMs. To further enhance these representations, we incorporate diverse human or robotic manipulation datasets, employing unified video-generation training objectives. VPP consistently outperforms existing methods across two simulated and two real-world benchmarks. Notably, it achieves a 28.1\% relative improvement in the Calvin ABC-D benchmark compared to the previous state-of-the-art and delivers a 28.8\% increase in success rates for complex real-world dexterous manipulation tasks.
Prediction with Action: Visual Policy Learning via Joint Denoising Process
Nov 27, 2024



Diffusion models have demonstrated remarkable capabilities in image generation tasks, including image editing and video creation, representing a good understanding of the physical world. On the other line, diffusion models have also shown promise in robotic control tasks by denoising actions, known as diffusion policy. Although the diffusion generative model and diffusion policy exhibit distinct capabilities--image prediction and robotic action, respectively--they technically follow a similar denoising process. In robotic tasks, the ability to predict future images and generate actions is highly correlated since they share the same underlying dynamics of the physical world. Building on this insight, we introduce PAD, a novel visual policy learning framework that unifies image Prediction and robot Action within a joint Denoising process. Specifically, PAD utilizes Diffusion Transformers (DiT) to seamlessly integrate images and robot states, enabling the simultaneous prediction of future images and robot actions. Additionally, PAD supports co-training on both robotic demonstrations and large-scale video datasets and can be easily extended to other robotic modalities, such as depth images. PAD outperforms previous methods, achieving a significant 26.3% relative improvement on the full Metaworld benchmark, by utilizing a single text-conditioned visual policy within a data-efficient imitation learning setting. Furthermore, PAD demonstrates superior generalization to unseen tasks in real-world robot manipulation settings with 28.0% success rate increase compared to the strongest baseline. Project page at https://sites.google.com/view/pad-paper
RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
Apr 30, 2024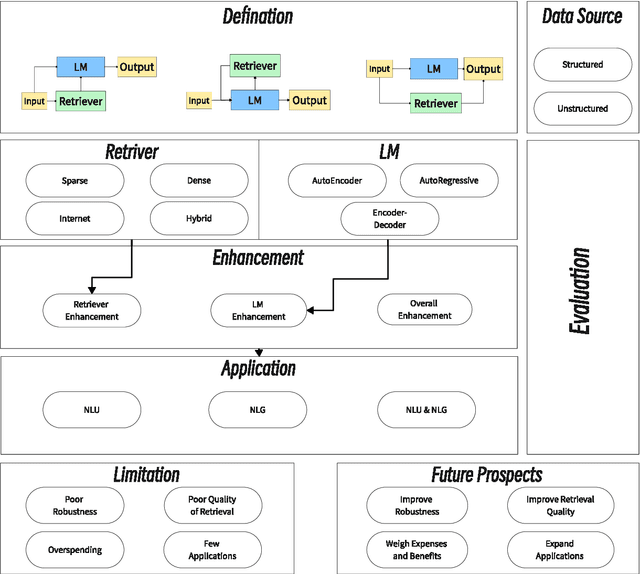



Large Language Models (LLMs) have catalyzed significant advancements in Natural Language Processing (NLP), yet they encounter challenges such as hallucination and the need for domain-specific knowledge. To mitigate these, recent methodologies have integrated information retrieved from external resources with LLMs, substantially enhancing their performance across NLP tasks. This survey paper addresses the absence of a comprehensive overview on Retrieval-Augmented Language Models (RALMs), both Retrieval-Augmented Generation (RAG) and Retrieval-Augmented Understanding (RAU), providing an in-depth examination of their paradigm, evolution, taxonomy, and applications. The paper discusses the essential components of RALMs, including Retrievers, Language Models, and Augmentations, and how their interactions lead to diverse model structures and applications. RALMs demonstrate utility in a spectrum of tasks, from translation and dialogue systems to knowledge-intensive applications. The survey includes several evaluation methods of RALMs, emphasizing the importance of robustness, accuracy, and relevance in their assessment. It also acknowledges the limitations of RALMs, particularly in retrieval quality and computational efficiency, offering directions for future research. In conclusion, this survey aims to offer a structured insight into RALMs, their potential, and the avenues for their future development in NLP. The paper is supplemented with a Github Repository containing the surveyed works and resources for further study: https://github.com/2471023025/RALM_Survey.
Object Detection Based Handwriting Localization
Jun 28, 2021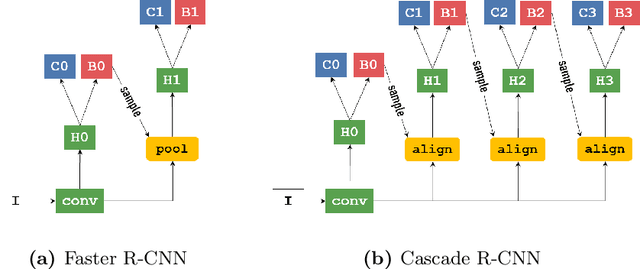
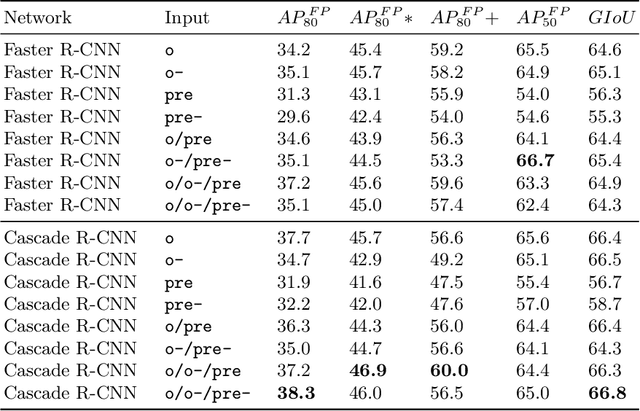
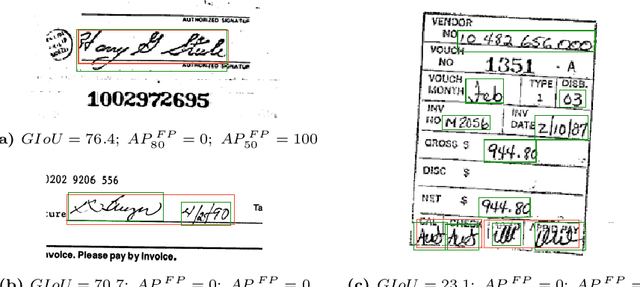
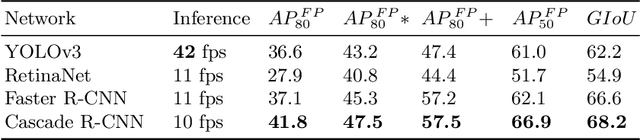
We present an object detection based approach to localize handwritten regions from documents, which initially aims to enhance the anonymization during the data transmission. The concatenated fusion of original and preprocessed images containing both printed texts and handwritten notes or signatures are fed into the convolutional neural network, where the bounding boxes are learned to detect the handwriting. Afterwards, the handwritten regions can be processed (e.g. replaced with redacted signatures) to conceal the personally identifiable information (PII). This processing pipeline based on the deep learning network Cascade R-CNN works at 10 fps on a GPU during the inference, which ensures the enhanced anonymization with minimal computational overheads. Furthermore, the impressive generalizability has been empirically showcased: the trained model based on the English-dominant dataset works well on the fictitious unseen invoices, even in Chinese. The proposed approach is also expected to facilitate other tasks such as handwriting recognition and signature verification.