 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Imbalanced Safety Data Using Extended Accident Triangle
Aug 12, 2024There is growing interest in using safety analytics and machine learning to support the prevention of workplace incidents, especially in high-risk industries like construction and trucking. Although existing safety analytics studies have made remarkable progress, they suffer from imbalanced datasets, a common problem in safety analytics, resulting in prediction inaccuracies. This can lead to management problems, e.g., incorrect resource allocation and improper interventions. To overcome the imbalanced data problem, we extend the theory of accident triangle to claim that the importance of data samples should be based on characteristics such as injury severity, accident frequency, and accident type. Thus, three oversampling methods are proposed based on assigning different weights to samples in the minority class. We find robust improvements among different machine learning algorithms. For the lack of open-source safety datasets, we are sharing three imbalanced datasets, e.g., a 9-year nationwide construction accident record dataset, and their corresponding codes.
Predicting trucking accidents with truck drivers 'safety climate perception across companies: A transfer learning approach
Feb 19, 2024
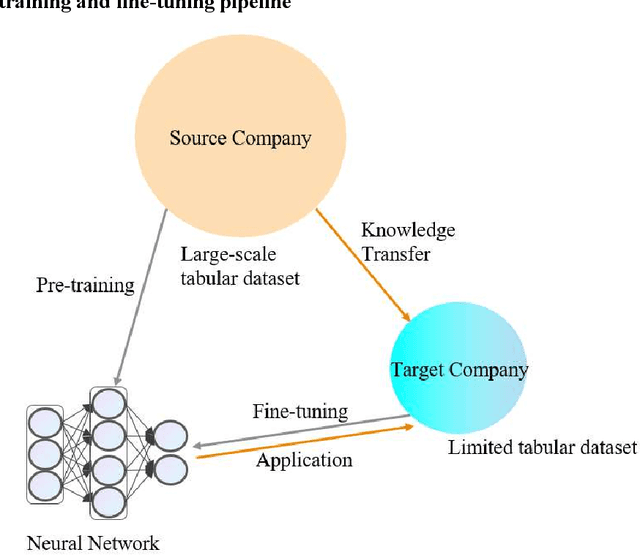


There is a rising interest in using artificial intelligence (AI)-powered safety analytics to predict accidents in the trucking industry. Companies may face the practical challenge, however, of not having enough data to develop good safety analytics models. Although pretrained models may offer a solution for such companies, existing safety research using transfer learning has mostly focused on computer vision and natural language processing, rather than accident analytics. To fill the above gap, we propose a pretrain-then-fine-tune transfer learning approach to help any company leverage other companies' data to develop AI models for a more accurate prediction of accident risk. We also develop SafeNet, a deep neural network algorithm for classification tasks suitable for accident prediction. Using the safety climate survey data from seven trucking companies with different data sizes, we show that our proposed approach results in better model performance compared to training the model from scratch using only the target company's data. We also show that for the transfer learning model to be effective, the pretrained model should be developed with larger datasets from diverse sources. The trucking industry may, thus, consider pooling safety analytics data from a wide range of companies to develop pretrained models and share them within the industry for better knowledge and resource transfer. The above contributions point to the promise of advanced safety analytics to make the industry safer and more sustainable.
An interpretable clustering approach to safety climate analysis: examining driver group distinction in safety climate perceptions
Oct 30, 2023



The transportation industry, particularly the trucking sector, is prone to workplace accidents and fatalities. Accidents involving large trucks accounted for a considerable percentage of overall traffic fatalities. Recognizing the crucial role of safety climate in accident prevention, researchers have sought to understand its factors and measure its impact within organizations. While existing data-driven safety climate studies have made remarkable progress, clustering employees based on their safety climate perception is innovative and has not been extensively utilized in research. Identifying clusters of drivers based on their safety climate perception allows the organization to profile its workforce and devise more impactful interventions. The lack of utilizing the clustering approach could be due to difficulties interpreting or explaining the factors influencing employees' cluster membership. Moreover, existing safety-related studies did not compare multiple clustering algorithms, resulting in potential bias. To address these issues, this study introduces an interpretable clustering approach for safety climate analysis. This study compares 5 algorithms for clustering truck drivers based on their safety climate perceptions. It proposes a novel method for quantitatively evaluating partial dependence plots (QPDP). To better interpret the clustering results, this study introduces different interpretable machine learning measures (SHAP, PFI, and QPDP). Drawing on data collected from more than 7,000 American truck drivers, this study significantly contributes to the scientific literature. It highlights the critical role of supervisory care promotion in distinguishing various driver groups. The Python code is available at https://github.com/NUS-DBE/truck-driver-safety-climate.
Revisiting the Loss Weight Adjustment in Object Detection
Mar 18, 2021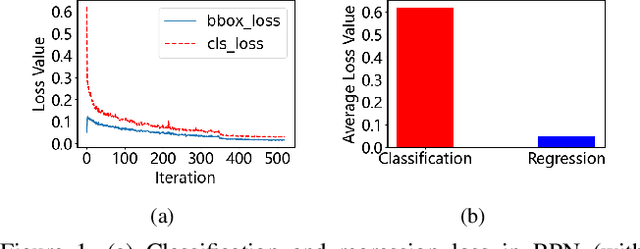
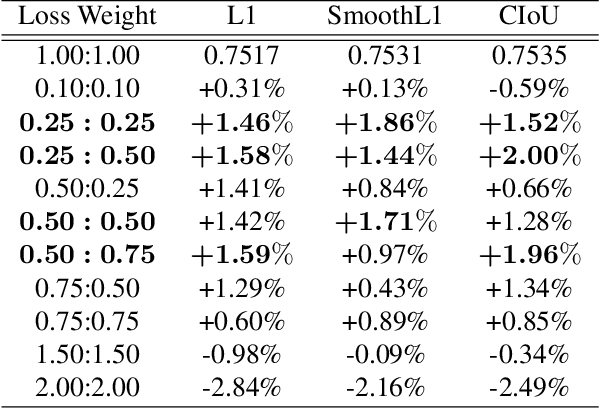
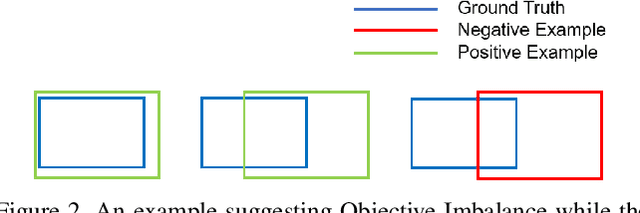
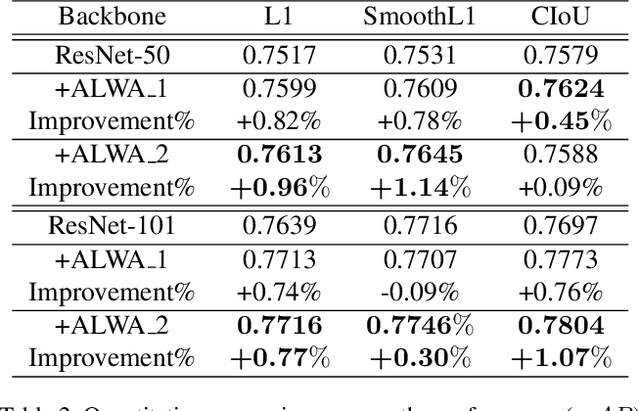
By definition, object detection requires a multi-task loss in order to solve classification and regression tasks simultaneously. However, loss weight tends to be set manually in actuality. Therefore, a very practical problem that has not been studied so far arises: how to quickly find the loss weight that fits the current loss functions. In addition, when we choose different regression loss functions, whether the loss weight need to be adjusted and if so, how should it be adjusted still is a problem demanding prompt solution. In this paper, through experiments and theoretical analysis of prediction box shifting, we firstly find out three important conclusions about optimal loss weight allocation strategy, including (1) the classification loss curve decays faster than regression loss curve; (2) loss weight is less than 1; (3) the gap between classification and regression loss weight should not be too large. Then, based on the above conclusions, we propose an Adaptive Loss Weight Adjustment(ALWA) to solve the above two problems by dynamically adjusting the loss weight in the training process, according to statistical characteristics of loss values. By incorporating ALWA into both one-stage and two-stage object detectors, we show a consistent improvement on their performance using L1, SmoothL1 and CIoU loss, performance measures on popular object detection benchmarks including PASCAL VOC and MS COCO. The code is available at https://github.com/ywx-hub/ALWA.