 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Super-Resolution: All You Need is a Video Diffusion Model
Mar 05, 2025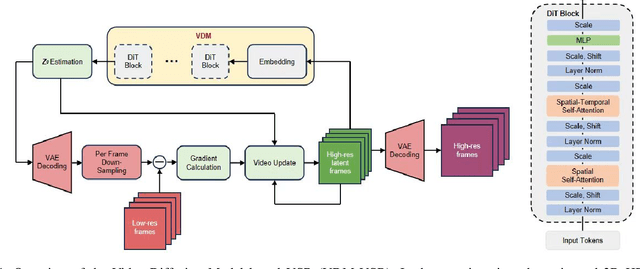


We present a generic video super-resolution algorithm in this paper, based on the Diffusion Posterior Sampling framework with an unconditional video generation model in latent space. The video generation model, a diffusion transformer, functions as a space-time model. We argue that a powerful model, which learns the physics of the real world, can easily handle various kinds of motion patterns as prior knowledge, thus eliminating the need for explicit estimation of optical flows or motion parameters for pixel alignment. Furthermore, a single instance of the proposed video diffusion transformer model can adapt to different sampling conditions without re-training. Due to limited computational resources and training data, our experiments provide empirical evidence of the algorithm's strong super-resolution capabilities using synthetic data.