 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning
May 07, 2025In this paper, we tackle the problem of learning to play 3v3 multi-drone volleyball, a new embodied competitive task that requires both high-level strategic coordination and low-level agile control. The task is turn-based, multi-agent, and physically grounded, posing significant challenges due to its long-horizon dependencies, tight inter-agent coupling, and the underactuated dynamics of quadrotors. To address this, we propose Hierarchical Co-Self-Play (HCSP), a hierarchical reinforcement learning framework that separates centralized high-level strategic decision-making from decentralized low-level motion control. We design a three-stage population-based training pipeline to enable both strategy and skill to emerge from scratch without expert demonstrations: (I) training diverse low-level skills, (II) learning high-level strategy via self-play with fixed low-level controllers, and (III) joint fine-tuning through co-self-play. Experiments show that HCSP achieves superior performance, outperforming non-hierarchical self-play and rule-based hierarchical baselines with an average 82.9\% win rate and a 71.5\% win rate against the two-stage variant. Moreover, co-self-play leads to emergent team behaviors such as role switching and coordinated formations, demonstrating the effectiveness of our hierarchical design and training scheme.
VolleyBots: A Testbed for Multi-Drone Volleyball Game Combining Motion Control and Strategic Play
Feb 04, 2025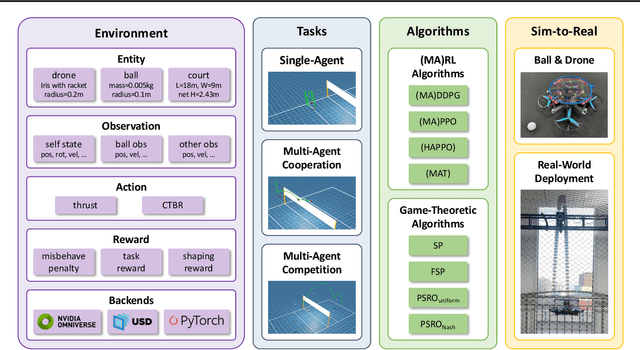
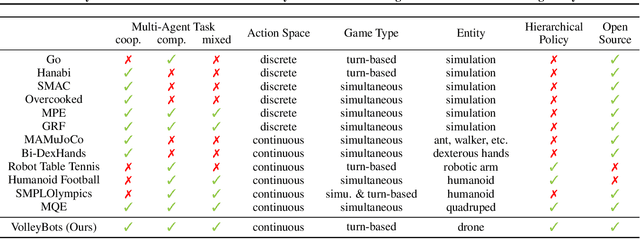
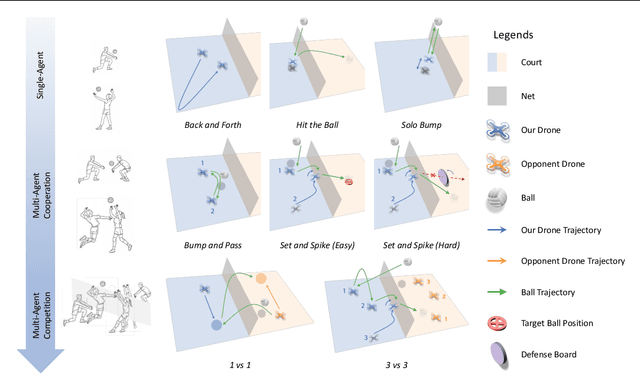

Multi-agent reinforcement learning (MARL) has made significant progress, largely fueled by the development of specialized testbeds that enable systematic evaluation of algorithms in controlled yet challenging scenarios. However, existing testbeds often focus on purely virtual simulations or limited robot morphologies such as robotic arms, quadrupeds, and humanoids, leaving high-mobility platforms with real-world physical constraints like drones underexplored. To bridge this gap, we present VolleyBots, a new MARL testbed where multiple drones cooperate and compete in the sport of volleyball under physical dynamics. VolleyBots features a turn-based interaction model under volleyball rules, a hierarchical decision-making process that combines motion control and strategic play, and a high-fidelity simulation for seamless sim-to-real transfer. We provide a comprehensive suite of tasks ranging from single-drone drills to multi-drone cooperative and competitive tasks, accompanied by baseline evaluations of representative MARL and game-theoretic algorithms. Results in simulation show that while existing algorithms handle simple tasks effectively, they encounter difficulty in complex tasks that require both low-level control and high-level strategy. We further demonstrate zero-shot deployment of a simulation-learned policy to real-world drones, highlighting VolleyBots' potential to propel MARL research involving agile robotic platforms. The project page is at https://sites.google.com/view/volleybots/home.
What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
Dec 17, 2024Executing precise and agile flight maneuvers is critical for quadrotors in various applications. Traditional quadrotor control approaches are limited by their reliance on flat trajectories or time-consuming optimization, which restricts their flexibility. Recently, RL-based policy has emerged as a promising alternative due to its ability to directly map observations to actions, reducing the need for detailed system knowledge and actuation constraints. However, a significant challenge remains in bridging the sim-to-real gap, where RL-based policies often experience instability when deployed in real world. In this paper, we investigate key factors for learning robust RL-based control policies that are capable of zero-shot deployment in real-world quadrotors. We identify five critical factors and we develop a PPO-based training framework named SimpleFlight, which integrates these five techniques. We validate the efficacy of SimpleFlight on Crazyflie quadrotor, demonstrating that it achieves more than a 50% reduction in trajectory tracking error compared to state-of-the-art RL baselines, and achieves 70% improvement over the traditional MPC. The policy derived by SimpleFlight consistently excels across both smooth polynominal trajectories and challenging infeasible zigzag trajectories on small thrust-to-weight quadrotors. In contrast, baseline methods struggle with high-speed or infeasible trajectories. To support further research and reproducibility, we integrate SimpleFlight into a GPU-based simulator Omnidrones and provide open-source access to the code and model checkpoints. We hope SimpleFlight will offer valuable insights for advancing RL-based quadrotor control. For more details, visit our project website at https://sites.google.com/view/simpleflight/.