 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFantastic Pretraining Optimizers and Where to Find Them II: Hyperball Optimization
Jun 15, 2026Matrix based optimizers such as Muon can substantially speed up language model pretraining, but their gains over AdamW are observed to shrink as model size and data scale grow when using standard constant decoupled weight decay. We propose Hyperball, a simple optimizer wrapper that addresses this issue. Given a base optimizer such as Adam or Muon, Hyperball sets the Frobenius norms of weight matrices and their corresponding optimizer updates to fixed constants. On Qwen3 style models up to 1.2B parameters, Muon Hyperball achieves 20--30% token equivalent speedup over weight decay baselines. Hyperball also improves learning rate transfer across widths and depths compared to decoupled weight decay. This method is motivated by prior theory showing that training with weight decay leads to an equilibrium weight norm that only depends on the training hyperparameters. Through this mechanism, the weight decay then decides the angular learning rate, i.e. how fast the direction of the weight matrix changes.
Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Jun 04, 2026We introduce Goedel-Architect, an agentic framework for formal theorem proving in Lean 4 centered on blueprint generation and refinement. A blueprint is a dependency graph of definitions and lemmas that builds up to the main theorem. First, Goedel-Architect generates a blueprint of formally stated definitions and lemmas, along with declared dependencies. This blueprint is optionally guided by a natural language proof. Then, a tool-equipped Lean prover component closes each open lemma node in parallel using relevant dependencies. Failed lemmas in turn drive refinement of the global blueprint. This strategy contrasts with other mainstream approaches which use recursive lemma decomposition, and can inefficiently loop on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With an optional natural-language proof seeding the initial blueprint on the harder problems, we additionally close the remaining two MiniF2F-test problems (reaching 100%), lift PutnamBench to 88.8% (597/672), and solve 4/6 on IMO 2025, 11/12 on Putnam 2025, and 3/6 on USAMO 2026. This represents state-of-the-art performance for an open-source pipeline at a price point up to 500x less than comparable open-source pipelines.
The Power of Power Law: Asymmetry Enables Compositional Reasoning
Apr 24, 2026Natural language data follows a power-law distribution, with most knowledge and skills appearing at very low frequency. While a common intuition suggests that reweighting or curating data towards a uniform distribution may help models better learn these long-tail skills, we find a counterintuitive result: across a wide range of compositional reasoning tasks, such as state tracking and multi-step arithmetic, training under power-law distributions consistently outperforms training under uniform distributions. To understand this advantage, we introduce a minimalist skill-composition task and show that learning under a power-law distribution provably requires significantly less training data. Our theoretical analysis reveals that power law sampling induces a beneficial asymmetry that improves the pathological loss landscape, which enables models to first acquire high-frequency skill compositions with low data complexity, which in turn serves as a stepping stone to efficiently learn rare long-tailed skills. Our results offer an alternative perspective on what constitutes an effective data distribution for training models.
Fine-tuning DeepSeek-OCR-2 for Molecular Structure Recognition
Apr 03, 2026Optical Chemical Structure Recognition (OCSR) is critical for converting 2D molecular diagrams from printed literature into machine-readable formats. While Vision-Language Models have shown promise in end-to-end OCR tasks, their direct application to OCSR remains challenging, and direct full-parameter supervised fine-tuning often fails. In this work, we adapt DeepSeek-OCR-2 for molecular optical recognition by formulating the task as image-conditioned SMILES generation. To overcome training instabilities, we propose a two-stage progressive supervised fine-tuning strategy: starting with parameter-efficient LoRA and transitioning to selective full-parameter fine-tuning with split learning rates. We train our model on a large-scale corpus combining synthetic renderings from PubChem and realistic patent images from USPTO-MOL to improve coverage and robustness. Our fine-tuned model, MolSeek-OCR, demonstrates competitive capabilities, achieving exact matching accuracies comparable to the best-performing image-to-sequence model. However, it remains inferior to state-of-the-art image-to-graph modelS. Furthermore, we explore reinforcement-style post-training and data-curation-based refinement, finding that they fail to improve the strict sequence-level fidelity required for exact SMILES matching.
Escaping the Cognitive Well: Efficient Competition Math with Off-the-Shelf Models
Feb 18, 2026In the past year, custom and unreleased math reasoning models reached gold medal performance on the International Mathematical Olympiad (IMO). Similar performance was then reported using large-scale inference on publicly available models but at prohibitive costs (e.g., 3000 USD per problem). In this work, we present an inference pipeline that attains best-in-class performance on IMO-style math problems at an average inference cost orders of magnitude below competing methods while using only general-purpose off-the-shelf models. Our method relies on insights about grader failure in solver-grader pipelines, which we call the Cognitive Well (iterative refinement converging to a wrong solution that the solver as well as the pipeline's internal grader consider to be basically correct). Our pipeline addresses these failure modes through conjecture extraction, wherein candidate lemmas are isolated from generated solutions and independently verified alongside their negations in a fresh environment (context detachment). On IMO-ProofBench Advanced (PB-Adv), our pipeline achieves 67.1 percent performance using Gemini 3.0 Pro with an average cost per question of approximately 31 USD. At the time of evaluation, this represented the state-of-the-art on PB-Adv among both public and unreleased models, and more than doubles the success rate of the next best publicly accessible pipeline, all at a fraction of the cost.
Weight Ensembling Improves Reasoning in Language Models
Apr 15, 2025We investigate a failure mode that arises during the training of reasoning models, where the diversity of generations begins to collapse, leading to suboptimal test-time scaling. Notably, the Pass@1 rate reliably improves during supervised finetuning (SFT), but Pass@k rapidly deteriorates. Surprisingly, a simple intervention of interpolating the weights of the latest SFT checkpoint with an early checkpoint, otherwise known as WiSE-FT, almost completely recovers Pass@k while also improving Pass@1. The WiSE-FT variant achieves better test-time scaling (Best@k, majority vote) and achieves superior results with less data when tuned further by reinforcement learning. Finally, we find that WiSE-FT provides complementary performance gains that cannot be achieved only through diversity-inducing decoding strategies, like temperature scaling. We formalize a bias-variance tradeoff of Pass@k with respect to the expectation and variance of Pass@1 over the test distribution. We find that WiSE-FT can reduce bias and variance simultaneously, while temperature scaling inherently trades-off between bias and variance.
RNNs are not Transformers : The Key Bottleneck on In-context Retrieval
Feb 29, 2024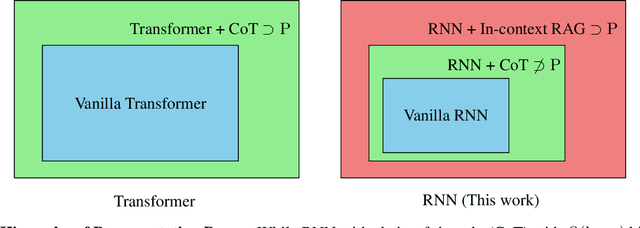
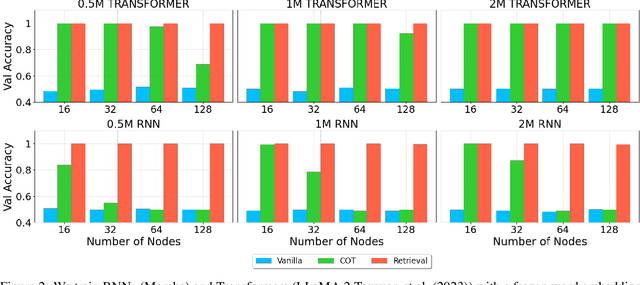
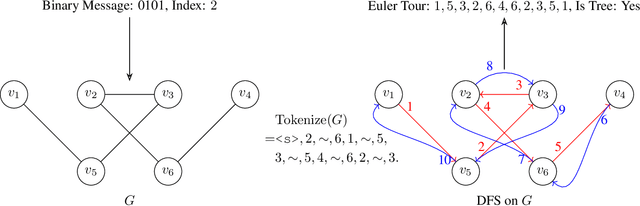
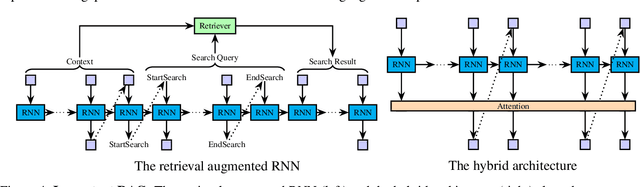
This paper investigates the gap in representation powers of Recurrent Neural Networks (RNNs) and Transformers in the context of solving algorithmic problems. We focus on understanding whether RNNs, known for their memory efficiency in handling long sequences, can match the performance of Transformers, particularly when enhanced with Chain-of-Thought (CoT) prompting. Our theoretical analysis reveals that CoT improves RNNs but is insufficient to close the gap with Transformers. A key bottleneck lies in the inability of RNNs to perfectly retrieve information from the context, even with CoT: for several tasks that explicitly or implicitly require this capability, such as associative recall and determining if a graph is a tree, we prove that RNNs are not expressive enough to solve the tasks while Transformers can solve them with ease. Conversely, we prove that adopting techniques to enhance the in-context retrieval capability of RNNs, including Retrieval-Augmented Generation (RAG) and adding a single Transformer layer, can elevate RNNs to be capable of solving all polynomial-time solvable problems with CoT, hence closing the representation gap with Transformers.
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Jun 01, 2023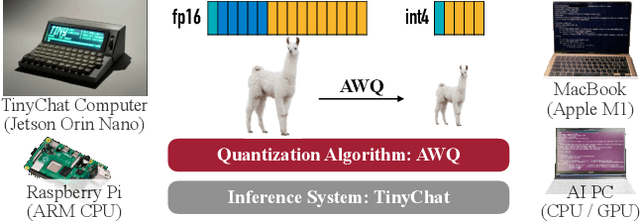

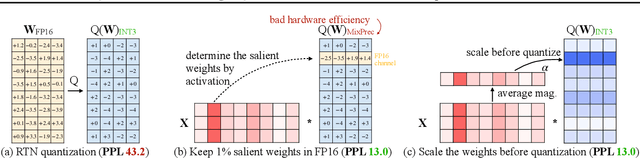
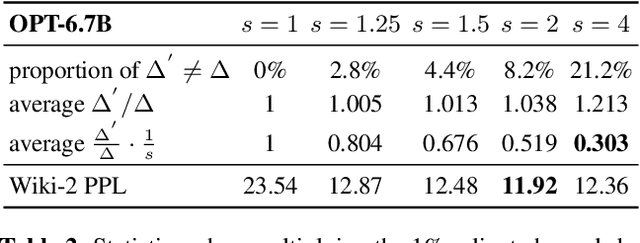
Large language models (LLMs) have shown excellent performance on various tasks, but the astronomical model size raises the hardware barrier for serving (memory size) and slows down token generation (memory bandwidth). In this paper, we propose Activation-aware Weight Quantization (AWQ), a hardware-friendly approach for LLM low-bit weight-only quantization. Our method is based on the observation that weights are not equally important: protecting only 1% of salient weights can greatly reduce quantization error. We then propose to search for the optimal per-channel scaling that protects the salient weights by observing the activation, not weights. AWQ does not rely on any backpropagation or reconstruction, so it can well preserve LLMs' generalization ability on different domains and modalities, without overfitting to the calibration set; it also does not rely on any data layout reordering, maintaining the hardware efficiency. AWQ outperforms existing work on various language modeling, common sense QA, and domain-specific benchmarks. Thanks to better generalization, it achieves excellent quantization performance for instruction-tuned LMs and, for the first time, multi-modal LMs. We also implement efficient tensor core kernels with reorder-free online dequantization to accelerate AWQ, achieving a 1.45x speedup over GPTQ and is 1.85x faster than the cuBLAS FP16 implementation. Our method provides a turn-key solution to compress LLMs to 3/4 bits for efficient deployment.