 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Sensing Attention Network for Video-based Person Re-identification
Paper and Code
Jul 06, 2022

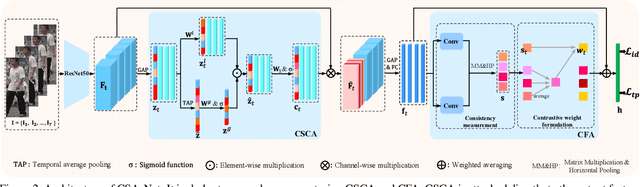
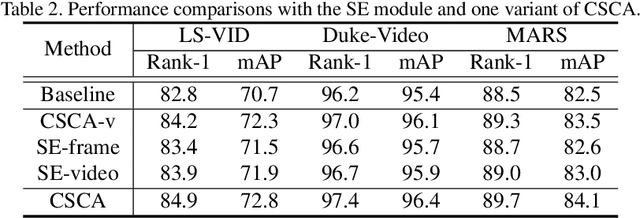
Video-based person re-identification (ReID) is challenging due to the presence of various interferences in video frames. Recent approaches handle this problem using temporal aggregation strategies. In this work, we propose a novel Context Sensing Attention Network (CSA-Net), which improves both the frame feature extraction and temporal aggregation steps. First, we introduce the Context Sensing Channel Attention (CSCA) module, which emphasizes responses from informative channels for each frame. These informative channels are identified with reference not only to each individual frame, but also to the content of the entire sequence. Therefore, CSCA explores both the individuality of each frame and the global context of the sequence. Second, we propose the Contrastive Feature Aggregation (CFA) module, which predicts frame weights for temporal aggregation. Here, the weight for each frame is determined in a contrastive manner: i.e., not only by the quality of each individual frame, but also by the average quality of the other frames in a sequence. Therefore, it effectively promotes the contribution of relatively good frames. Extensive experimental results on four datasets show that CSA-Net consistently achieves state-of-the-art performance.