 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoRA: Nested Low-Rank Adaptation for Efficient Fine-Tuning Large Models
Aug 18, 2024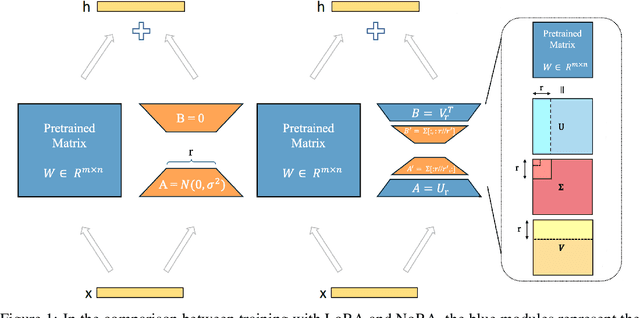
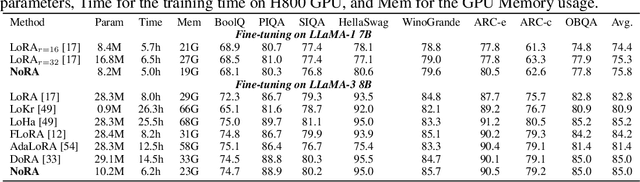
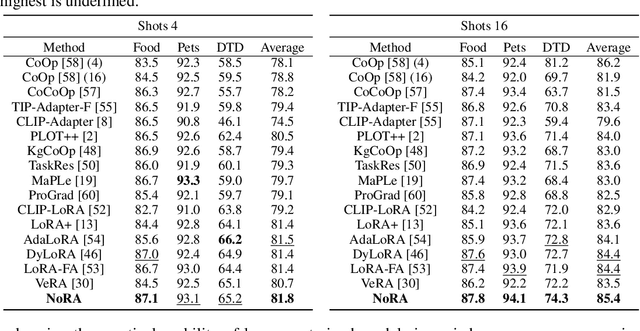

In this paper, we introduce Nested Low-Rank Adaptation (NoRA), a novel approach to parameter-efficient fine-tuning that extends the capabilities of Low-Rank Adaptation (LoRA) techniques. Vanilla LoRA overlooks pre-trained weight inheritance and still requires fine-tuning numerous parameters. To addresses these issues, our NoRA adopts a dual-layer nested structure with Singular Value Decomposition (SVD), effectively leveraging original matrix knowledge while reducing tunable parameters. Specifically, NoRA freezes the outer LoRA weights and utilizes an inner LoRA design, providing enhanced control over model optimization. This approach allows the model to more precisely adapt to specific tasks while maintaining a compact parameter space. By freezing outer LoRA weights and using an inner LoRA design, NoRA enables precise task adaptation with a compact parameter space. Evaluations on tasks including commonsense reasoning with large language models, fine-tuning vision-language models, and subject-driven generation demonstrate NoRA's superiority over LoRA and its variants. Notably, NoRA reduces fine-tuning parameters|training-time|memory-usage by 4\%|22.5\%|20.7\% compared to LoRA on LLaMA-3 8B, while achieving 2.2\% higher performance. Code will be released upon acceptance.