 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
Paper and Code
Apr 14, 2025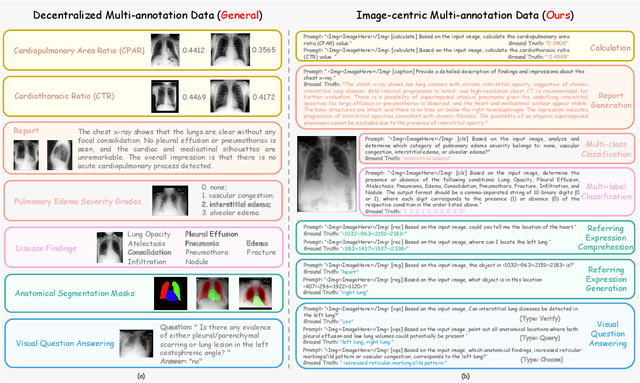
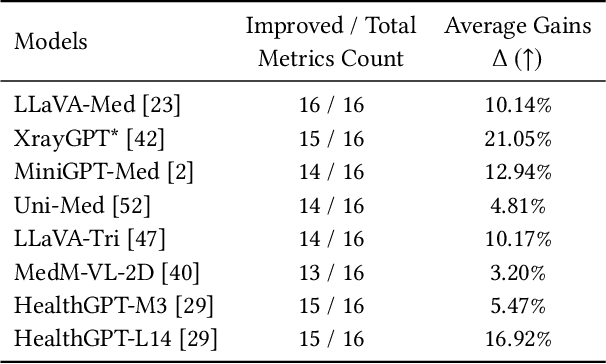
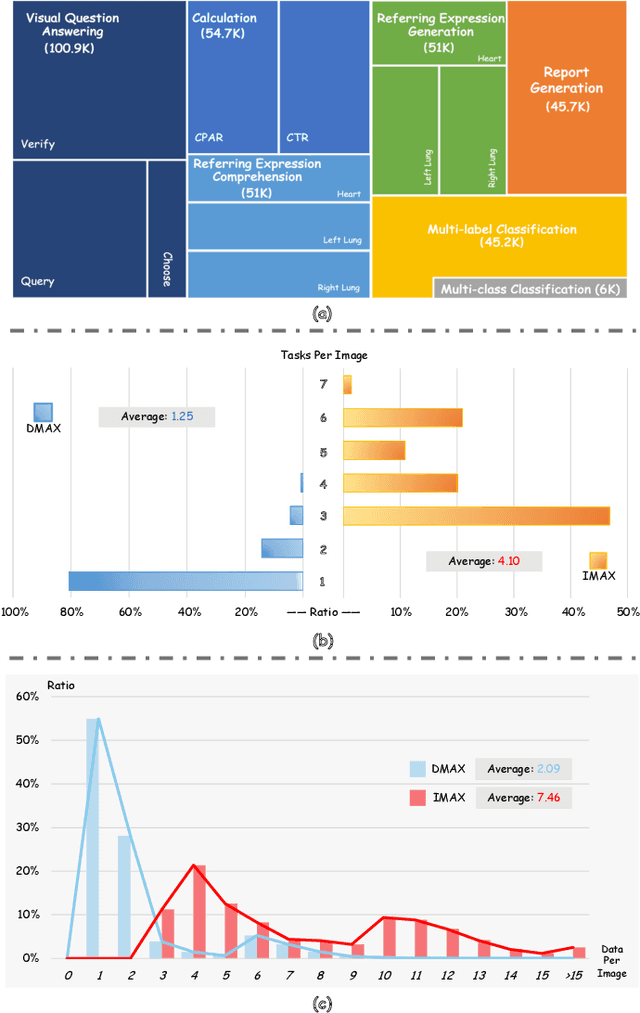

The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.