 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
Apr 14, 2025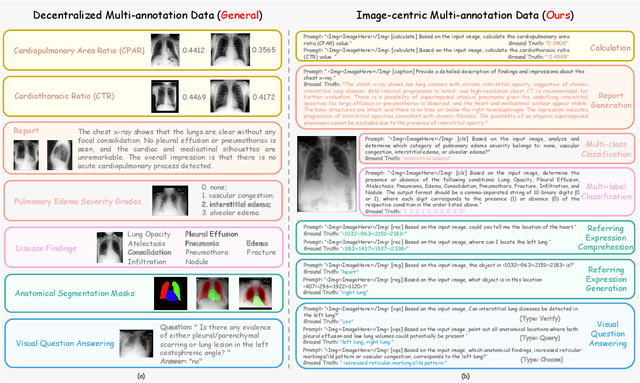
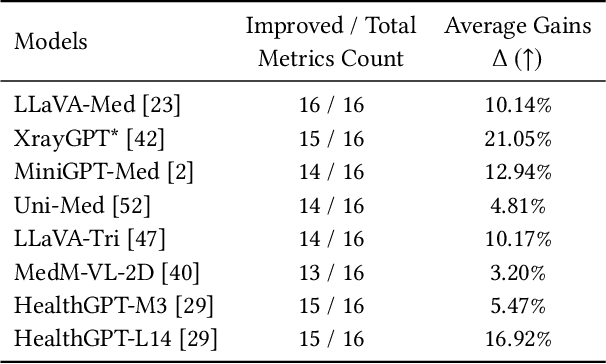
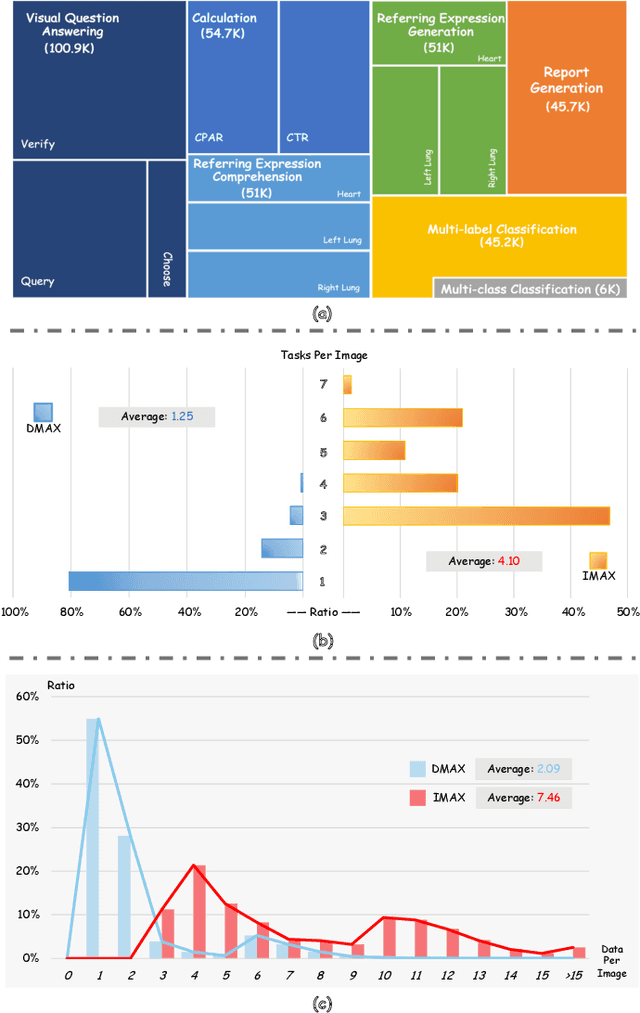

The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.
Uni-Med: A Unified Medical Generalist Foundation Model For Multi-Task Learning Via Connector-MoE
Sep 26, 2024



Multi-modal large language models (MLLMs) have shown impressive capabilities as a general-purpose interface for various visual and linguistic tasks. However, building a unified MLLM for multi-task learning in the medical field remains a thorny challenge. To mitigate the tug-of-war problem of multi-modal multi-task optimization, recent advances primarily focus on improving the LLM components, while neglecting the connector that bridges the gap between modalities. In this paper, we introduce Uni-Med, a novel medical generalist foundation model which consists of a universal visual feature extraction module, a connector mixture-of-experts (CMoE) module, and an LLM. Benefiting from the proposed CMoE that leverages a well-designed router with a mixture of projection experts at the connector, Uni-Med achieves efficient solution to the tug-of-war problem and can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification. To the best of our knowledge, Uni-Med is the first effort to tackle multi-task interference at the connector. Extensive ablation experiments validate the effectiveness of introducing CMoE under any configuration, with up to an average 8% performance gains. We further provide interpretation analysis of the tug-of-war problem from the perspective of gradient optimization and parameter statistics. Compared to previous state-of-the-art medical MLLMs, Uni-Med achieves competitive or superior evaluation metrics on diverse tasks. Code, data and model will be soon available at GitHub.