 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskCraft: Automated Generation of Agentic Tasks
Jun 11, 2025Agentic tasks, which require multi-step problem solving with autonomy, tool use, and adaptive reasoning, are becoming increasingly central to the advancement of NLP and AI. However, existing instruction data lacks tool interaction, and current agentic benchmarks rely on costly human annotation, limiting their scalability. We introduce \textsc{TaskCraft}, an automated workflow for generating difficulty-scalable, multi-tool, and verifiable agentic tasks with execution trajectories. TaskCraft expands atomic tasks using depth-based and width-based extensions to create structurally and hierarchically complex challenges. Empirical results show that these tasks improve prompt optimization in the generation workflow and enhance supervised fine-tuning of agentic foundation models. We present a large-scale synthetic dataset of approximately 36,000 tasks with varying difficulty to support future research on agent tuning and evaluation.
Complexity boosted adaptive training for better low resource ASR performance
Dec 01, 2024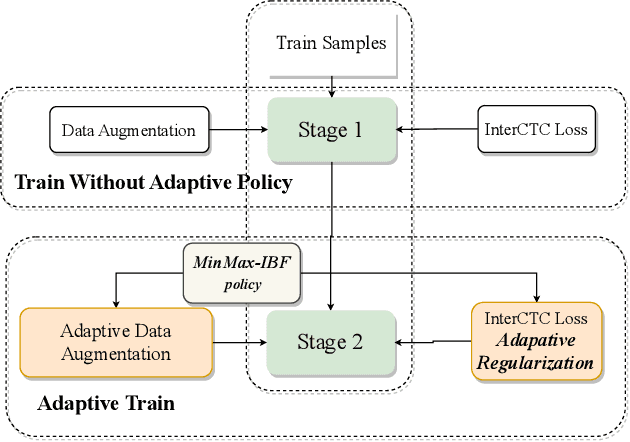

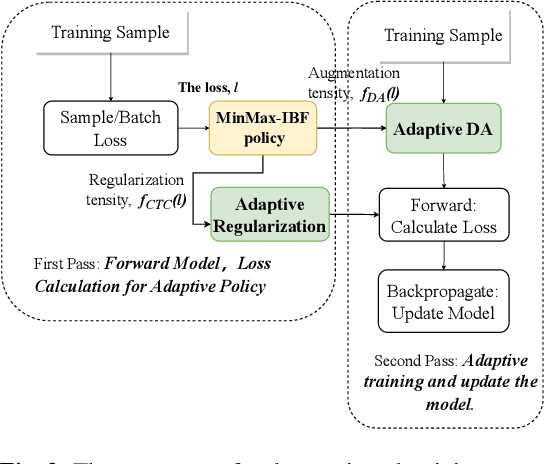

During the entire training process of the ASR model, the intensity of data augmentation and the approach of calculating training loss are applied in a regulated manner based on preset parameters. For example, SpecAugment employs a predefined strength of augmentation to mask parts of the time-frequency domain spectrum. Similarly, in CTC-based multi-layer models, the loss is generally determined based on the output of the encoder's final layer during the training process. However, ignoring dynamic characteristics may suboptimally train models. To address the issue, we present a two-stage training method, known as complexity-boosted adaptive (CBA) training. It involves making dynamic adjustments to data augmentation strategies and CTC loss propagation based on the complexity of the training samples. In the first stage, we train the model with intermediate-CTC-based regularization and data augmentation without any adaptive policy. In the second stage, we propose a novel adaptive policy, called MinMax-IBF, which calculates the complexity of samples. We combine the MinMax-IBF policy to data augmentation and intermediate CTC loss regularization to continue training. The proposed CBA training approach shows considerable improvements, up to 13.4% and 14.1% relative reduction in WER on the LibriSpeech 100h test-clean and test-other dataset and also up to 6.3% relative reduction on AISHELL-1 test set, over the Conformer architecture in Wenet.
Sample adaptive data augmentation with progressive scheduling
Nov 30, 2024



Data augmentation is a widely adopted technique utilized to improve the robustness of automatic speech recognition (ASR). Employing a fixed data augmentation strategy for all training data is a common practice. However, it is important to note that there can be variations in factors such as background noise, speech rate, etc. among different samples within a single training batch. By using a fixed augmentation strategy, there is a risk that the model may reach a suboptimal state. In addition to the risks of employing a fixed augmentation strategy, the model's capabilities may differ across various training stages. To address these issues, this paper proposes the method of sample-adaptive data augmentation with progressive scheduling(PS-SapAug). The proposed method applies dynamic data augmentation in a two-stage training approach. It employs hybrid normalization to compute sample-specific augmentation parameters based on each sample's loss. Additionally, the probability of augmentation gradually increases throughout the training progression. Our method is evaluated on popular ASR benchmark datasets, including Aishell-1 and Librispeech-100h, achieving up to 8.13% WER reduction on LibriSpeech-100h test-clean, 6.23% on test-other, and 5.26% on AISHELL-1 test set, which demonstrate the efficacy of our approach enhancing performance and minimizing errors.