 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Needs to Focus: A Unified Perspective on Attention Allocation
Jan 07, 2026The Transformer architecture, a cornerstone of modern Large Language Models (LLMs), has achieved extraordinary success in sequence modeling, primarily due to its attention mechanism. However, despite its power, the standard attention mechanism is plagued by well-documented issues: representational collapse and attention sink. Although prior work has proposed approaches for these issues, they are often studied in isolation, obscuring their deeper connection. In this paper, we present a unified perspective, arguing that both can be traced to a common root -- improper attention allocation. We identify two failure modes: 1) Attention Overload, where tokens receive comparable high weights, blurring semantic features that lead to representational collapse; 2) Attention Underload, where no token is semantically relevant, yet attention is still forced to distribute, resulting in spurious focus such as attention sink. Building on this insight, we introduce Lazy Attention, a novel mechanism designed for a more focused attention distribution. To mitigate overload, it employs positional discrimination across both heads and dimensions to sharpen token distinctions. To counteract underload, it incorporates Elastic-Softmax, a modified normalization function that relaxes the standard softmax constraint to suppress attention on irrelevant tokens. Experiments on the FineWeb-Edu corpus, evaluated across nine diverse benchmarks, demonstrate that Lazy Attention successfully mitigates attention sink and achieves competitive performance compared to both standard attention and modern architectures, while reaching up to 59.58% attention sparsity.
IPENS:Interactive Unsupervised Framework for Rapid Plant Phenotyping Extraction via NeRF-SAM2 Fusion
May 19, 2025Advanced plant phenotyping technologies play a crucial role in targeted trait improvement and accelerating intelligent breeding. Due to the species diversity of plants, existing methods heavily rely on large-scale high-precision manually annotated data. For self-occluded objects at the grain level, unsupervised methods often prove ineffective. This study proposes IPENS, an interactive unsupervised multi-target point cloud extraction method. The method utilizes radiance field information to lift 2D masks, which are segmented by SAM2 (Segment Anything Model 2), into 3D space for target point cloud extraction. A multi-target collaborative optimization strategy is designed to effectively resolve the single-interaction multi-target segmentation challenge. Experimental validation demonstrates that IPENS achieves a grain-level segmentation accuracy (mIoU) of 63.72% on a rice dataset, with strong phenotypic estimation capabilities: grain volume prediction yields R2 = 0.7697 (RMSE = 0.0025), leaf surface area R2 = 0.84 (RMSE = 18.93), and leaf length and width predictions achieve R2 = 0.97 and 0.87 (RMSE = 1.49 and 0.21). On a wheat dataset,IPENS further improves segmentation accuracy to 89.68% (mIoU), with equally outstanding phenotypic estimation performance: spike volume prediction achieves R2 = 0.9956 (RMSE = 0.0055), leaf surface area R2 = 1.00 (RMSE = 0.67), and leaf length and width predictions reach R2 = 0.99 and 0.92 (RMSE = 0.23 and 0.15). This method provides a non-invasive, high-quality phenotyping extraction solution for rice and wheat. Without requiring annotated data, it rapidly extracts grain-level point clouds within 3 minutes through simple single-round interactions on images for multiple targets, demonstrating significant potential to accelerate intelligent breeding efficiency.
Sliding Window Attention Training for Efficient Large Language Models
Feb 26, 2025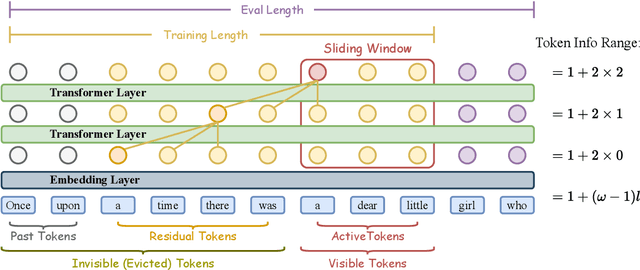
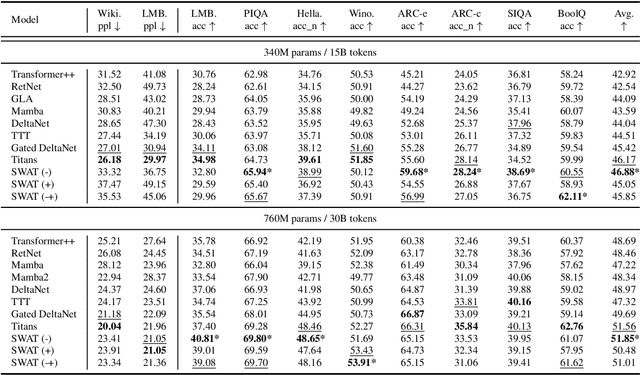
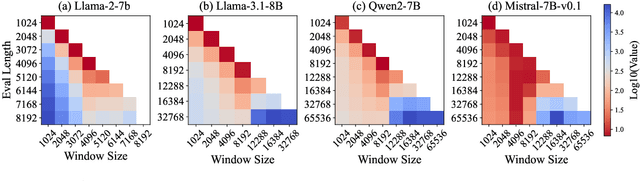
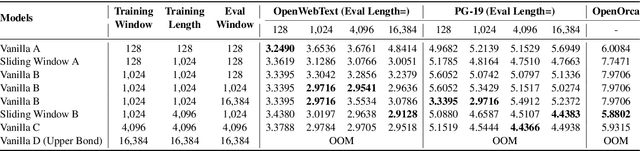
Recent advances in transformer-based Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks. However, their quadratic computational complexity concerning sequence length remains a significant bottleneck for processing long documents. As a result, many efforts like sparse attention and state space models have been proposed to improve the efficiency of LLMs over long sequences. Though effective, these approaches compromise the performance or introduce structural complexity. This calls for a simple yet efficient model that preserves the fundamental Transformer architecture. To this end, we introduce SWAT, which enables efficient long-context handling via Sliding Window Attention Training. This paper first attributes the inefficiency of Transformers to the attention sink phenomenon resulting from the high variance of softmax operation. Then, we replace softmax with the sigmoid function and utilize a balanced ALiBi and Rotary Position Embedding for efficient information compression and retention. Experiments demonstrate that SWAT achieves SOTA performance compared with state-of-the-art linear recurrent architectures on eight benchmarks. Code is available at https://anonymous.4open.science/r/SWAT-attention.