 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Human Feedback: A Statistical Perspective
Apr 02, 2026Reinforcement learning from human feedback (RLHF) has emerged as a central framework for aligning large language models (LLMs) with human preferences. Despite its practical success, RLHF raises fundamental statistical questions because it relies on noisy, subjective, and often heterogeneous feedback to learn reward models and optimize policies. This survey provides a statistical perspective on RLHF, focusing primarily on the LLM alignment setting. We introduce the main components of RLHF, including supervised fine-tuning, reward modeling, and policy optimization, and relate them to familiar statistical ideas such as Bradley-Terry-Luce (BTL) model, latent utility estimation, active learning, experimental design, and uncertainty quantification. We review methods for learning reward functions from pairwise preference data and for optimizing policies through both two-stage RLHF pipelines and emerging one-stage approaches such as direct preference optimization. We further discuss recent extensions including reinforcement learning from AI feedback, inference-time algorithms, and reinforcement learning from verifiable rewards, as well as benchmark datasets, evaluation protocols, and open-source frameworks that support RLHF research. We conclude by highlighting open challenges in RLHF. An accompanying GitHub demo https://github.com/Pangpang-Liu/RLHF_demo illustrates key components of the RLHF pipeline.
Do More Predictions Improve Statistical Inference? Filtered Prediction-Powered Inference
Feb 11, 2026Recent advances in artificial intelligence have enabled the generation of large-scale, low-cost predictions with increasingly high fidelity. As a result, the primary challenge in statistical inference has shifted from data scarcity to data reliability. Prediction-powered inference methods seek to exploit such predictions to improve efficiency when labeled data are limited. However, existing approaches implicitly adopt a use-all philosophy, under which incorporating more predictions is presumed to improve inference. When prediction quality is heterogeneous, this assumption can fail, and indiscriminate use of unlabeled data may dilute informative signals and degrade inferential accuracy. In this paper, we propose Filtered Prediction-Powered Inference (FPPI), a framework that selectively incorporates predictions by identifying a data-adaptive filtered region in which predictions are informative for inference. We show that this region can be consistently estimated under a margin condition, achieving fast rates of convergence. By restricting the prediction-powered correction to the estimated filtered region, FPPI adaptively mitigates the impact of biased or noisy predictions. We establish that FPPI attains strictly improved asymptotic efficiency compared with existing prediction-powered inference methods. Numerical studies and a real-data application to large language model evaluation demonstrate that FPPI substantially reduces reliance on expensive labels by selectively leveraging reliable predictions, yielding accurate inference even in the presence of heterogeneous prediction quality.
PPI-SVRG: Unifying Prediction-Powered Inference and Variance Reduction for Semi-Supervised Optimization
Jan 29, 2026We study semi-supervised stochastic optimization when labeled data is scarce but predictions from pre-trained models are available. PPI and SVRG both reduce variance through control variates -- PPI uses predictions, SVRG uses reference gradients. We show they are mathematically equivalent and develop PPI-SVRG, which combines both. Our convergence bound decomposes into the standard SVRG rate plus an error floor from prediction uncertainty. The rate depends only on loss geometry; predictions affect only the neighborhood size. When predictions are perfect, we recover SVRG exactly. When predictions degrade, convergence remains stable but reaches a larger neighborhood. Experiments confirm the theory: PPI-SVRG reduces MSE by 43--52\% under label scarcity on mean estimation benchmarks and improves test accuracy by 2.7--2.9 percentage points on MNIST with only 10\% labeled data.
Fairness-aware Contextual Dynamic Pricing with Strategic Buyers
Jan 25, 2025



Contextual pricing strategies are prevalent in online retailing, where the seller adjusts prices based on products' attributes and buyers' characteristics. Although such strategies can enhance seller's profits, they raise concerns about fairness when significant price disparities emerge among specific groups, such as gender or race. These disparities can lead to adverse perceptions of fairness among buyers and may even violate the law and regulation. In contrast, price differences can incentivize disadvantaged buyers to strategically manipulate their group identity to obtain a lower price. In this paper, we investigate contextual dynamic pricing with fairness constraints, taking into account buyers' strategic behaviors when their group status is private and unobservable from the seller. We propose a dynamic pricing policy that simultaneously achieves price fairness and discourages strategic behaviors. Our policy achieves an upper bound of $O(\sqrt{T}+H(T))$ regret over $T$ time horizons, where the term $H(T)$ arises from buyers' assessment of the fairness of the pricing policy based on their learned price difference. When buyers are able to learn the fairness of the price policy, this upper bound reduces to $O(\sqrt{T})$. We also prove an $\Omega(\sqrt{T})$ regret lower bound of any pricing policy under our problem setting. We support our findings with extensive experimental evidence, showcasing our policy's effectiveness. In our real data analysis, we observe the existence of price discrimination against race in the loan application even after accounting for other contextual information. Our proposed pricing policy demonstrates a significant improvement, achieving 35.06% reduction in regret compared to the benchmark policy.
Low-Rank Contextual Reinforcement Learning from Heterogeneous Human Feedback
Dec 27, 2024



Reinforcement learning from human feedback (RLHF) has become a cornerstone for aligning large language models with human preferences. However, the heterogeneity of human feedback, driven by diverse individual contexts and preferences, poses significant challenges for reward learning. To address this, we propose a Low-rank Contextual RLHF (LoCo-RLHF) framework that integrates contextual information to better model heterogeneous feedback while maintaining computational efficiency. Our approach builds on a contextual preference model, leveraging the intrinsic low-rank structure of the interaction between user contexts and query-answer pairs to mitigate the high dimensionality of feature representations. Furthermore, we address the challenge of distributional shifts in feedback through our Pessimism in Reduced Subspace (PRS) policy, inspired by pessimistic offline reinforcement learning techniques. We theoretically demonstrate that our policy achieves a tighter sub-optimality gap compared to existing methods. Extensive experiments validate the effectiveness of LoCo-RLHF, showcasing its superior performance in personalized RLHF settings and its robustness to distribution shifts.
Privacy-Preserving Dynamic Assortment Selection
Oct 29, 2024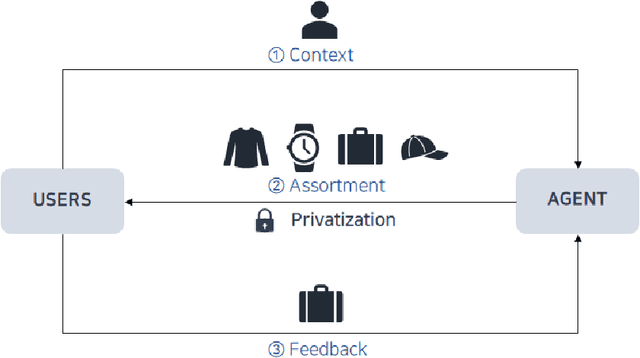

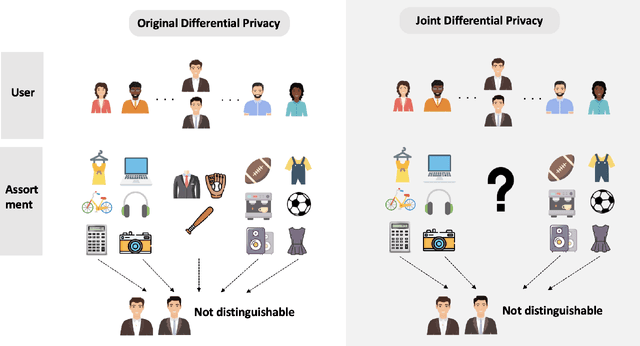
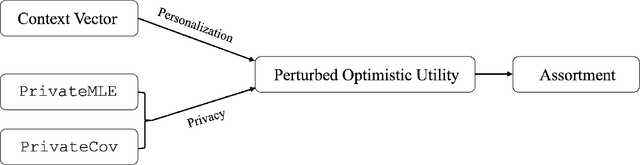
With the growing demand for personalized assortment recommendations, concerns over data privacy have intensified, highlighting the urgent need for effective privacy-preserving strategies. This paper presents a novel framework for privacy-preserving dynamic assortment selection using the multinomial logit (MNL) bandits model. Our approach employs a perturbed upper confidence bound method, integrating calibrated noise into user utility estimates to balance between exploration and exploitation while ensuring robust privacy protection. We rigorously prove that our policy satisfies Joint Differential Privacy (JDP), which better suits dynamic environments than traditional differential privacy, effectively mitigating inference attack risks. This analysis is built upon a novel objective perturbation technique tailored for MNL bandits, which is also of independent interest. Theoretically, we derive a near-optimal regret bound of $\tilde{O}(\sqrt{T})$ for our policy and explicitly quantify how privacy protection impacts regret. Through extensive simulations and an application to the Expedia hotel dataset, we demonstrate substantial performance enhancements over the benchmark method.
Dual Active Learning for Reinforcement Learning from Human Feedback
Oct 03, 2024
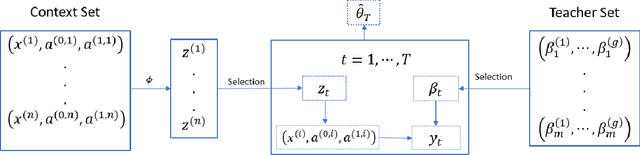

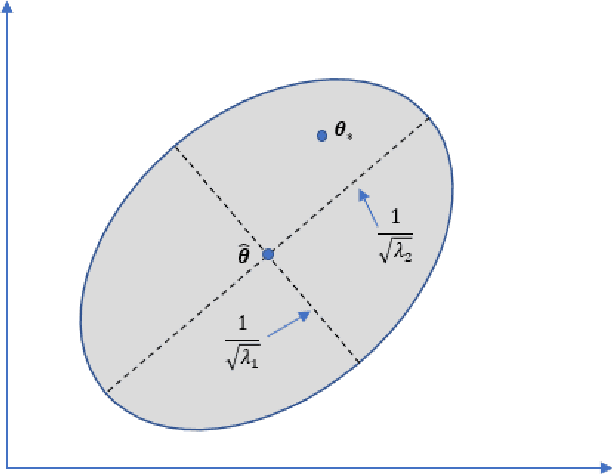
Aligning large language models (LLMs) with human preferences is critical to recent advances in generative artificial intelligence. Reinforcement learning from human feedback (RLHF) is widely applied to achieve this objective. A key step in RLHF is to learn the reward function from human feedback. However, human feedback is costly and time-consuming, making it essential to collect high-quality conversation data for human teachers to label. Additionally, different human teachers have different levels of expertise. It is thus critical to query the most appropriate teacher for their opinions. In this paper, we use offline reinforcement learning (RL) to formulate the alignment problem. Motivated by the idea of $D$-optimal design, we first propose a dual active reward learning algorithm for the simultaneous selection of conversations and teachers. Next, we apply pessimistic RL to solve the alignment problem, based on the learned reward estimator. Theoretically, we show that the reward estimator obtained through our proposed adaptive selection strategy achieves minimal generalized variance asymptotically, and prove that the sub-optimality of our pessimistic policy scales as $O(1/\sqrt{T})$ with a given sample budget $T$. Through simulations and experiments on LLMs, we demonstrate the effectiveness of our algorithm and its superiority over state-of-the-arts.
Active Learning for Fair and Stable Online Allocations
Jun 20, 2024
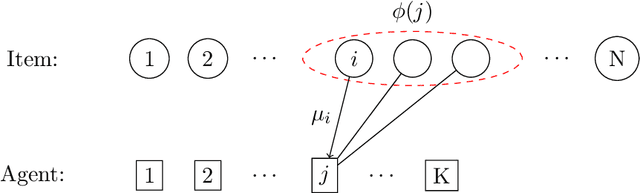

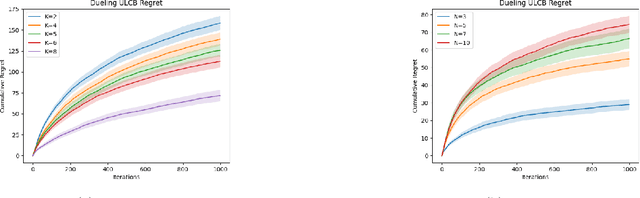
We explore an active learning approach for dynamic fair resource allocation problems. Unlike previous work that assumes full feedback from all agents on their allocations, we consider feedback from a select subset of agents at each epoch of the online resource allocation process. Despite this restriction, our proposed algorithms provide regret bounds that are sub-linear in number of time-periods for various measures that include fairness metrics commonly used in resource allocation problems and stability considerations in matching mechanisms. The key insight of our algorithms lies in adaptively identifying the most informative feedback using dueling upper and lower confidence bounds. With this strategy, we show that efficient decision-making does not require extensive feedback and produces efficient outcomes for a variety of problem classes.
Low-Rank Online Dynamic Assortment with Dual Contextual Information
Apr 19, 2024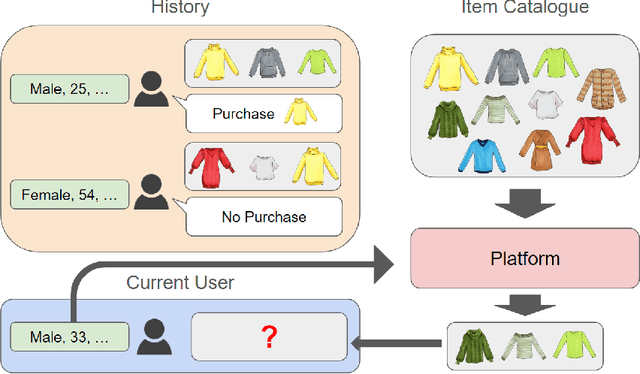

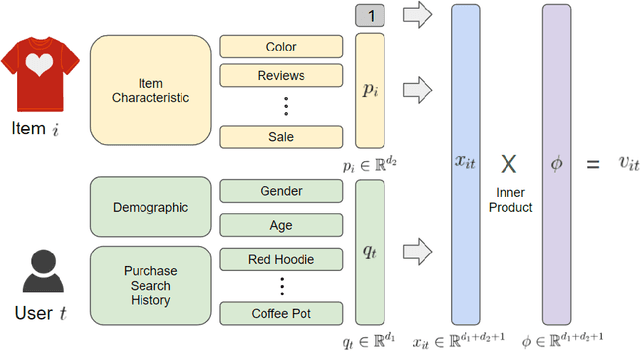
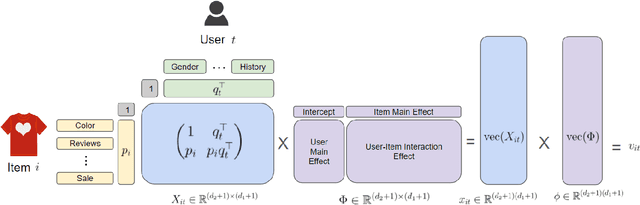
As e-commerce expands, delivering real-time personalized recommendations from vast catalogs poses a critical challenge for retail platforms. Maximizing revenue requires careful consideration of both individual customer characteristics and available item features to optimize assortments over time. In this paper, we consider the dynamic assortment problem with dual contexts -- user and item features. In high-dimensional scenarios, the quadratic growth of dimensions complicates computation and estimation. To tackle this challenge, we introduce a new low-rank dynamic assortment model to transform this problem into a manageable scale. Then we propose an efficient algorithm that estimates the intrinsic subspaces and utilizes the upper confidence bound approach to address the exploration-exploitation trade-off in online decision making. Theoretically, we establish a regret bound of $\tilde{O}((d_1+d_2)r\sqrt{T})$, where $d_1, d_2$ represent the dimensions of the user and item features respectively, $r$ is the rank of the parameter matrix, and $T$ denotes the time horizon. This bound represents a substantial improvement over prior literature, made possible by leveraging the low-rank structure. Extensive simulations and an application to the Expedia hotel recommendation dataset further demonstrate the advantages of our proposed method.
Pessimistic Causal Reinforcement Learning with Mediators for Confounded Offline Data
Mar 18, 2024



In real-world scenarios, datasets collected from randomized experiments are often constrained by size, due to limitations in time and budget. As a result, leveraging large observational datasets becomes a more attractive option for achieving high-quality policy learning. However, most existing offline reinforcement learning (RL) methods depend on two key assumptions--unconfoundedness and positivity--which frequently do not hold in observational data contexts. Recognizing these challenges, we propose a novel policy learning algorithm, PESsimistic CAusal Learning (PESCAL). We utilize the mediator variable based on front-door criterion to remove the confounding bias; additionally, we adopt the pessimistic principle to address the distributional shift between the action distributions induced by candidate policies, and the behavior policy that generates the observational data. Our key observation is that, by incorporating auxiliary variables that mediate the effect of actions on system dynamics, it is sufficient to learn a lower bound of the mediator distribution function, instead of the Q-function, to partially mitigate the issue of distributional shift. This insight significantly simplifies our algorithm, by circumventing the challenging task of sequential uncertainty quantification for the estimated Q-function. Moreover, we provide theoretical guarantees for the algorithms we propose, and demonstrate their efficacy through simulations, as well as real-world experiments utilizing offline datasets from a leading ride-hailing platform.