 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Active Learning for Reinforcement Learning from Human Feedback
Paper and Code
Oct 03, 2024
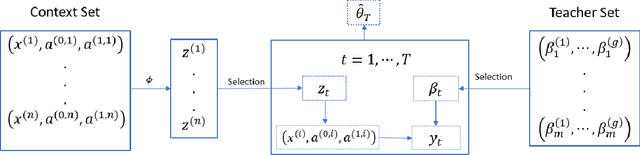

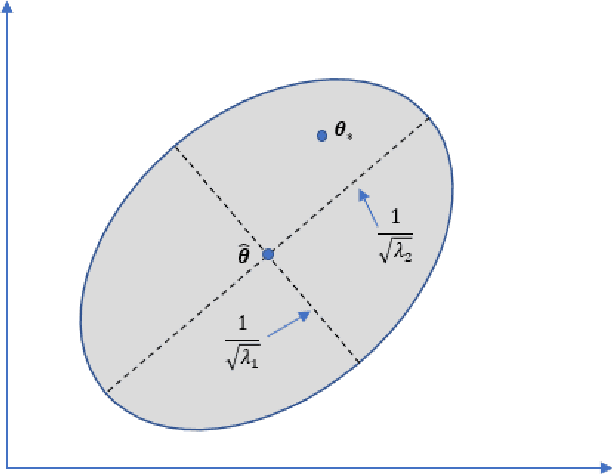
Aligning large language models (LLMs) with human preferences is critical to recent advances in generative artificial intelligence. Reinforcement learning from human feedback (RLHF) is widely applied to achieve this objective. A key step in RLHF is to learn the reward function from human feedback. However, human feedback is costly and time-consuming, making it essential to collect high-quality conversation data for human teachers to label. Additionally, different human teachers have different levels of expertise. It is thus critical to query the most appropriate teacher for their opinions. In this paper, we use offline reinforcement learning (RL) to formulate the alignment problem. Motivated by the idea of $D$-optimal design, we first propose a dual active reward learning algorithm for the simultaneous selection of conversations and teachers. Next, we apply pessimistic RL to solve the alignment problem, based on the learned reward estimator. Theoretically, we show that the reward estimator obtained through our proposed adaptive selection strategy achieves minimal generalized variance asymptotically, and prove that the sub-optimality of our pessimistic policy scales as $O(1/\sqrt{T})$ with a given sample budget $T$. Through simulations and experiments on LLMs, we demonstrate the effectiveness of our algorithm and its superiority over state-of-the-arts.