 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-aware Contextual Dynamic Pricing with Strategic Buyers
Jan 25, 2025Contextual pricing strategies are prevalent in online retailing, where the seller adjusts prices based on products' attributes and buyers' characteristics. Although such strategies can enhance seller's profits, they raise concerns about fairness when significant price disparities emerge among specific groups, such as gender or race. These disparities can lead to adverse perceptions of fairness among buyers and may even violate the law and regulation. In contrast, price differences can incentivize disadvantaged buyers to strategically manipulate their group identity to obtain a lower price. In this paper, we investigate contextual dynamic pricing with fairness constraints, taking into account buyers' strategic behaviors when their group status is private and unobservable from the seller. We propose a dynamic pricing policy that simultaneously achieves price fairness and discourages strategic behaviors. Our policy achieves an upper bound of $O(\sqrt{T}+H(T))$ regret over $T$ time horizons, where the term $H(T)$ arises from buyers' assessment of the fairness of the pricing policy based on their learned price difference. When buyers are able to learn the fairness of the price policy, this upper bound reduces to $O(\sqrt{T})$. We also prove an $\Omega(\sqrt{T})$ regret lower bound of any pricing policy under our problem setting. We support our findings with extensive experimental evidence, showcasing our policy's effectiveness. In our real data analysis, we observe the existence of price discrimination against race in the loan application even after accounting for other contextual information. Our proposed pricing policy demonstrates a significant improvement, achieving 35.06% reduction in regret compared to the benchmark policy.
Dual Active Learning for Reinforcement Learning from Human Feedback
Oct 03, 2024
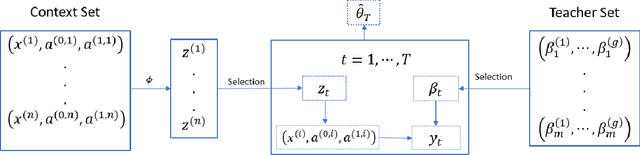

Aligning large language models (LLMs) with human preferences is critical to recent advances in generative artificial intelligence. Reinforcement learning from human feedback (RLHF) is widely applied to achieve this objective. A key step in RLHF is to learn the reward function from human feedback. However, human feedback is costly and time-consuming, making it essential to collect high-quality conversation data for human teachers to label. Additionally, different human teachers have different levels of expertise. It is thus critical to query the most appropriate teacher for their opinions. In this paper, we use offline reinforcement learning (RL) to formulate the alignment problem. Motivated by the idea of $D$-optimal design, we first propose a dual active reward learning algorithm for the simultaneous selection of conversations and teachers. Next, we apply pessimistic RL to solve the alignment problem, based on the learned reward estimator. Theoretically, we show that the reward estimator obtained through our proposed adaptive selection strategy achieves minimal generalized variance asymptotically, and prove that the sub-optimality of our pessimistic policy scales as $O(1/\sqrt{T})$ with a given sample budget $T$. Through simulations and experiments on LLMs, we demonstrate the effectiveness of our algorithm and its superiority over state-of-the-arts.
Contextual Dynamic Pricing with Strategic Buyers
Jul 08, 2023



Personalized pricing, which involves tailoring prices based on individual characteristics, is commonly used by firms to implement a consumer-specific pricing policy. In this process, buyers can also strategically manipulate their feature data to obtain a lower price, incurring certain manipulation costs. Such strategic behavior can hinder firms from maximizing their profits. In this paper, we study the contextual dynamic pricing problem with strategic buyers. The seller does not observe the buyer's true feature, but a manipulated feature according to buyers' strategic behavior. In addition, the seller does not observe the buyers' valuation of the product, but only a binary response indicating whether a sale happens or not. Recognizing these challenges, we propose a strategic dynamic pricing policy that incorporates the buyers' strategic behavior into the online learning to maximize the seller's cumulative revenue. We first prove that existing non-strategic pricing policies that neglect the buyers' strategic behavior result in a linear $\Omega(T)$ regret with $T$ the total time horizon, indicating that these policies are not better than a random pricing policy. We then establish that our proposed policy achieves a sublinear regret upper bound of $O(\sqrt{T})$. Importantly, our policy is not a mere amalgamation of existing dynamic pricing policies and strategic behavior handling algorithms. Our policy can also accommodate the scenario when the marginal cost of manipulation is unknown in advance. To account for it, we simultaneously estimate the valuation parameter and the cost parameter in the online pricing policy, which is shown to also achieve an $O(\sqrt{T})$ regret bound. Extensive experiments support our theoretical developments and demonstrate the superior performance of our policy compared to other pricing policies that are unaware of the strategic behaviors.